{"title":"真实世界情感识别的多模态时空框架","authors":"Karishma Raut , Sujata Kulkarni , Ashwini Sawant","doi":"10.1016/j.ijin.2024.10.001","DOIUrl":null,"url":null,"abstract":"<div><div>Deep learning models show great potential in applications involving video-based affect recognition, including human-computer interaction, robotic interfaces, stress and depression assessment, and Alzheimer's disease detection. The low complex Multimodal Diverse Spatio-Temporal Network (MDSTN) has been analysed to effectively capture spatio-temporal information from audio-visual modalities for affect recognition using the Acted Facial Expressions in the Wild (AFEW) dataset. The scarcity of data is handled by data augmented parallel feature extraction for visual network. Visual features extracted by carefully reviewing and customizing Convolutional 3D architecture over different ranges are combined to train a neural network for classification. Multi-resolution Cochleagram (MRCG) features from speech, along with spectral and prosodic audio features, are processed by a supervised classifier. The late fusion technique is explored to integrate audio and video modalities, considering their processing over different temporal spans. The MDSTN approach significantly boosts the accuracy of basic emotion recognition to 71.54 % on the AFEW dataset. It demonstrates exceptional proficiency in identifying emotions such as disgust and surprise, thus exceeding current benchmarks in real-world affect recognition.</div></div>","PeriodicalId":100702,"journal":{"name":"International Journal of Intelligent Networks","volume":"5 ","pages":"Pages 340-350"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multimodal spatio-temporal framework for real-world affect recognition\",\"authors\":\"Karishma Raut , Sujata Kulkarni , Ashwini Sawant\",\"doi\":\"10.1016/j.ijin.2024.10.001\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Deep learning models show great potential in applications involving video-based affect recognition, including human-computer interaction, robotic interfaces, stress and depression assessment, and Alzheimer's disease detection. The low complex Multimodal Diverse Spatio-Temporal Network (MDSTN) has been analysed to effectively capture spatio-temporal information from audio-visual modalities for affect recognition using the Acted Facial Expressions in the Wild (AFEW) dataset. The scarcity of data is handled by data augmented parallel feature extraction for visual network. Visual features extracted by carefully reviewing and customizing Convolutional 3D architecture over different ranges are combined to train a neural network for classification. Multi-resolution Cochleagram (MRCG) features from speech, along with spectral and prosodic audio features, are processed by a supervised classifier. The late fusion technique is explored to integrate audio and video modalities, considering their processing over different temporal spans. The MDSTN approach significantly boosts the accuracy of basic emotion recognition to 71.54 % on the AFEW dataset. It demonstrates exceptional proficiency in identifying emotions such as disgust and surprise, thus exceeding current benchmarks in real-world affect recognition.</div></div>\",\"PeriodicalId\":100702,\"journal\":{\"name\":\"International Journal of Intelligent Networks\",\"volume\":\"5 \",\"pages\":\"Pages 340-350\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Intelligent Networks\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666603024000332\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/11 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Intelligent Networks","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666603024000332","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/11 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Multimodal spatio-temporal framework for real-world affect recognition
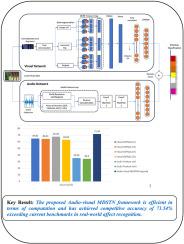
Deep learning models show great potential in applications involving video-based affect recognition, including human-computer interaction, robotic interfaces, stress and depression assessment, and Alzheimer's disease detection. The low complex Multimodal Diverse Spatio-Temporal Network (MDSTN) has been analysed to effectively capture spatio-temporal information from audio-visual modalities for affect recognition using the Acted Facial Expressions in the Wild (AFEW) dataset. The scarcity of data is handled by data augmented parallel feature extraction for visual network. Visual features extracted by carefully reviewing and customizing Convolutional 3D architecture over different ranges are combined to train a neural network for classification. Multi-resolution Cochleagram (MRCG) features from speech, along with spectral and prosodic audio features, are processed by a supervised classifier. The late fusion technique is explored to integrate audio and video modalities, considering their processing over different temporal spans. The MDSTN approach significantly boosts the accuracy of basic emotion recognition to 71.54 % on the AFEW dataset. It demonstrates exceptional proficiency in identifying emotions such as disgust and surprise, thus exceeding current benchmarks in real-world affect recognition.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
