{"title":"以人为本的可解释人工智能应用评估:系统回顾。","authors":"Jenia Kim, Henry Maathuis, Danielle Sent","doi":"10.3389/frai.2024.1456486","DOIUrl":null,"url":null,"abstract":"<p><p>Explainable Artificial Intelligence (XAI) aims to provide insights into the inner workings and the outputs of AI systems. Recently, there's been growing recognition that explainability is inherently human-centric, tied to how people perceive explanations. Despite this, there is no consensus in the research community on whether user evaluation is crucial in XAI, and if so, what exactly needs to be evaluated and how. This systematic literature review addresses this gap by providing a detailed overview of the current state of affairs in human-centered XAI evaluation. We reviewed 73 papers across various domains where XAI was evaluated with users. These studies assessed what makes an explanation \"good\" from a user's perspective, i.e., what makes an explanation <i>meaningful</i> to a user of an AI system. We identified 30 components of meaningful explanations that were evaluated in the reviewed papers and categorized them into a taxonomy of human-centered XAI evaluation, based on: (a) the contextualized quality of the explanation, (b) the contribution of the explanation to human-AI interaction, and (c) the contribution of the explanation to human-AI performance. Our analysis also revealed a lack of standardization in the methodologies applied in XAI user studies, with only 19 of the 73 papers applying an evaluation framework used by at least one other study in the sample. These inconsistencies hinder cross-study comparisons and broader insights. Our findings contribute to understanding what makes explanations meaningful to users and how to measure this, guiding the XAI community toward a more unified approach in human-centered explainability.</p>","PeriodicalId":33315,"journal":{"name":"Frontiers in Artificial Intelligence","volume":"7 ","pages":"1456486"},"PeriodicalIF":4.7000,"publicationDate":"2024-10-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11525002/pdf/","citationCount":"0","resultStr":"{\"title\":\"Human-centered evaluation of explainable AI applications: a systematic review.\",\"authors\":\"Jenia Kim, Henry Maathuis, Danielle Sent\",\"doi\":\"10.3389/frai.2024.1456486\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Explainable Artificial Intelligence (XAI) aims to provide insights into the inner workings and the outputs of AI systems. Recently, there's been growing recognition that explainability is inherently human-centric, tied to how people perceive explanations. Despite this, there is no consensus in the research community on whether user evaluation is crucial in XAI, and if so, what exactly needs to be evaluated and how. This systematic literature review addresses this gap by providing a detailed overview of the current state of affairs in human-centered XAI evaluation. We reviewed 73 papers across various domains where XAI was evaluated with users. These studies assessed what makes an explanation \\\"good\\\" from a user's perspective, i.e., what makes an explanation <i>meaningful</i> to a user of an AI system. We identified 30 components of meaningful explanations that were evaluated in the reviewed papers and categorized them into a taxonomy of human-centered XAI evaluation, based on: (a) the contextualized quality of the explanation, (b) the contribution of the explanation to human-AI interaction, and (c) the contribution of the explanation to human-AI performance. Our analysis also revealed a lack of standardization in the methodologies applied in XAI user studies, with only 19 of the 73 papers applying an evaluation framework used by at least one other study in the sample. These inconsistencies hinder cross-study comparisons and broader insights. Our findings contribute to understanding what makes explanations meaningful to users and how to measure this, guiding the XAI community toward a more unified approach in human-centered explainability.</p>\",\"PeriodicalId\":33315,\"journal\":{\"name\":\"Frontiers in Artificial Intelligence\",\"volume\":\"7 \",\"pages\":\"1456486\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2024-10-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11525002/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Artificial Intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/frai.2024.1456486\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Artificial Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/frai.2024.1456486","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Human-centered evaluation of explainable AI applications: a systematic review.
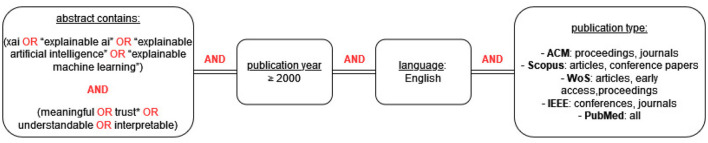
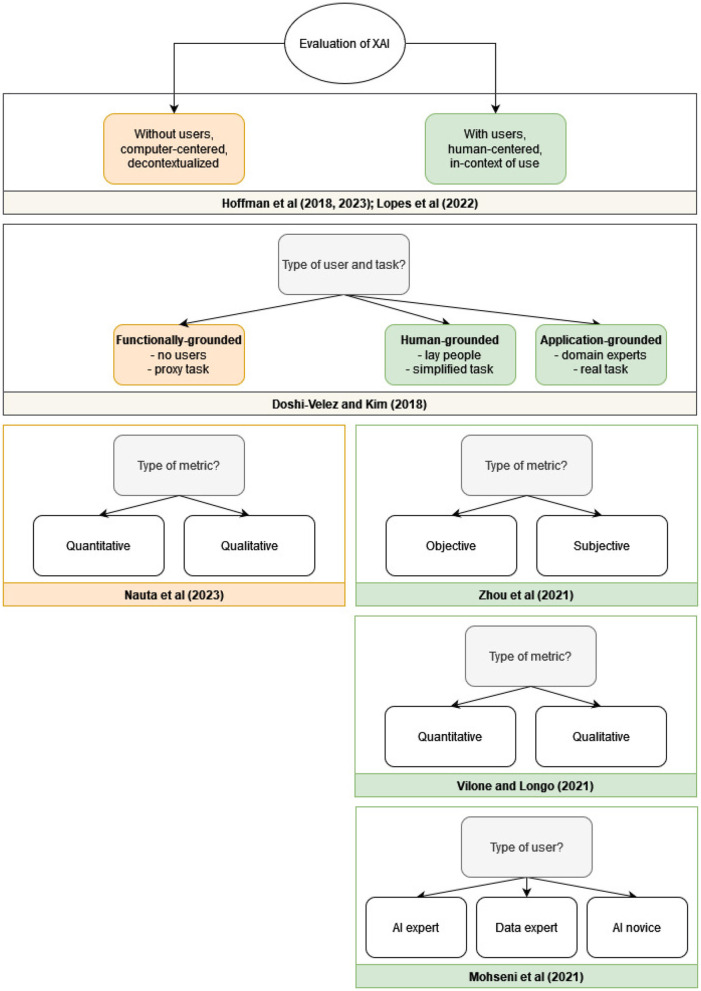
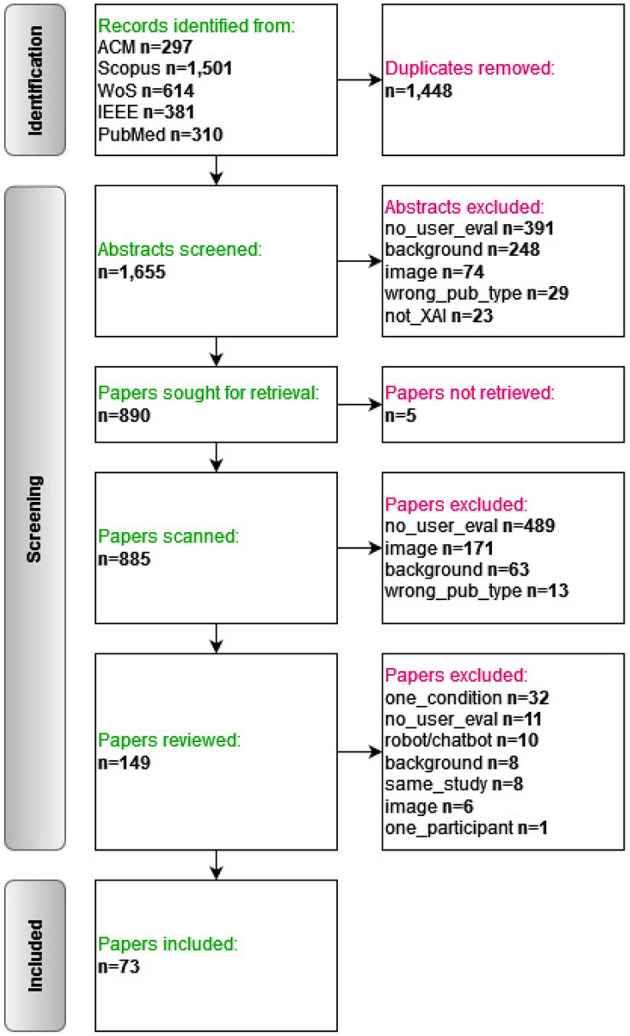
Explainable Artificial Intelligence (XAI) aims to provide insights into the inner workings and the outputs of AI systems. Recently, there's been growing recognition that explainability is inherently human-centric, tied to how people perceive explanations. Despite this, there is no consensus in the research community on whether user evaluation is crucial in XAI, and if so, what exactly needs to be evaluated and how. This systematic literature review addresses this gap by providing a detailed overview of the current state of affairs in human-centered XAI evaluation. We reviewed 73 papers across various domains where XAI was evaluated with users. These studies assessed what makes an explanation "good" from a user's perspective, i.e., what makes an explanation meaningful to a user of an AI system. We identified 30 components of meaningful explanations that were evaluated in the reviewed papers and categorized them into a taxonomy of human-centered XAI evaluation, based on: (a) the contextualized quality of the explanation, (b) the contribution of the explanation to human-AI interaction, and (c) the contribution of the explanation to human-AI performance. Our analysis also revealed a lack of standardization in the methodologies applied in XAI user studies, with only 19 of the 73 papers applying an evaluation framework used by at least one other study in the sample. These inconsistencies hinder cross-study comparisons and broader insights. Our findings contribute to understanding what makes explanations meaningful to users and how to measure this, guiding the XAI community toward a more unified approach in human-centered explainability.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
