{"title":"为高效目标条件强化学习生成高价值子目标","authors":"Yao Li , YuHui Wang , XiaoYang Tan","doi":"10.1016/j.neunet.2024.106825","DOIUrl":null,"url":null,"abstract":"<div><div>Goal-conditioned reinforcement learning is widely used in robot control, manipulating the robot to accomplish specific tasks by maximizing accumulated rewards. However, the useful reward signal is only received when the desired goal is reached, leading to the issue of sparse rewards and affecting the efficiency of policy learning. In this paper, we propose a method to generate highly valued subgoals for efficient goal-conditioned policy learning, enabling the development of smart home robots or automatic pilots in our daily life. The highly valued subgoals are conditioned on the context of the specific tasks and characterized by suitable complexity for efficient goal-conditioned action value learning. The context variable captures the latent representation of the particular tasks, allowing for efficient subgoal generation. Additionally, the goal-conditioned action values regularized by the self-adaptive ranges generate subgoals with suitable complexity. Compared to Hindsight Experience Replay that uniformly samples subgoals from visited trajectories, our method generates the subgoals based on the context of tasks with suitable difficulty for efficient policy training. Experimental results show that our method achieves stable performance in robotic environments compared to baseline methods.</div></div>","PeriodicalId":49763,"journal":{"name":"Neural Networks","volume":"181 ","pages":"Article 106825"},"PeriodicalIF":6.3000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Highly valued subgoal generation for efficient goal-conditioned reinforcement learning\",\"authors\":\"Yao Li , YuHui Wang , XiaoYang Tan\",\"doi\":\"10.1016/j.neunet.2024.106825\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Goal-conditioned reinforcement learning is widely used in robot control, manipulating the robot to accomplish specific tasks by maximizing accumulated rewards. However, the useful reward signal is only received when the desired goal is reached, leading to the issue of sparse rewards and affecting the efficiency of policy learning. In this paper, we propose a method to generate highly valued subgoals for efficient goal-conditioned policy learning, enabling the development of smart home robots or automatic pilots in our daily life. The highly valued subgoals are conditioned on the context of the specific tasks and characterized by suitable complexity for efficient goal-conditioned action value learning. The context variable captures the latent representation of the particular tasks, allowing for efficient subgoal generation. Additionally, the goal-conditioned action values regularized by the self-adaptive ranges generate subgoals with suitable complexity. Compared to Hindsight Experience Replay that uniformly samples subgoals from visited trajectories, our method generates the subgoals based on the context of tasks with suitable difficulty for efficient policy training. Experimental results show that our method achieves stable performance in robotic environments compared to baseline methods.</div></div>\",\"PeriodicalId\":49763,\"journal\":{\"name\":\"Neural Networks\",\"volume\":\"181 \",\"pages\":\"Article 106825\"},\"PeriodicalIF\":6.3000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neural Networks\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0893608024007494\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/28 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Networks","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0893608024007494","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/28 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Highly valued subgoal generation for efficient goal-conditioned reinforcement learning
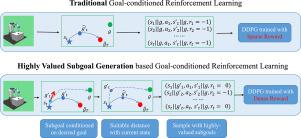
Goal-conditioned reinforcement learning is widely used in robot control, manipulating the robot to accomplish specific tasks by maximizing accumulated rewards. However, the useful reward signal is only received when the desired goal is reached, leading to the issue of sparse rewards and affecting the efficiency of policy learning. In this paper, we propose a method to generate highly valued subgoals for efficient goal-conditioned policy learning, enabling the development of smart home robots or automatic pilots in our daily life. The highly valued subgoals are conditioned on the context of the specific tasks and characterized by suitable complexity for efficient goal-conditioned action value learning. The context variable captures the latent representation of the particular tasks, allowing for efficient subgoal generation. Additionally, the goal-conditioned action values regularized by the self-adaptive ranges generate subgoals with suitable complexity. Compared to Hindsight Experience Replay that uniformly samples subgoals from visited trajectories, our method generates the subgoals based on the context of tasks with suitable difficulty for efficient policy training. Experimental results show that our method achieves stable performance in robotic environments compared to baseline methods.
期刊介绍:
Neural Networks is a platform that aims to foster an international community of scholars and practitioners interested in neural networks, deep learning, and other approaches to artificial intelligence and machine learning. Our journal invites submissions covering various aspects of neural networks research, from computational neuroscience and cognitive modeling to mathematical analyses and engineering applications. By providing a forum for interdisciplinary discussions between biology and technology, we aim to encourage the development of biologically-inspired artificial intelligence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
