{"title":"将关系作为已知条件基于标记的关系三提取方法","authors":"Guanqing Kong , Qi Lei","doi":"10.1016/j.csl.2024.101734","DOIUrl":null,"url":null,"abstract":"<div><div>Relational triple extraction refers to extracting entities and relations from natural texts, which is a crucial task in the construction of knowledge graph. Recently, tagging based methods have received increasing attention because of their simple and effective structural form. Among them, the two-step extraction method is easy to cause the problem of category imbalance. To address this issue, we propose a novel two-step extraction method, which first extracts subjects, generates a fixed-size embedding for each relation, and then regards these relations as known conditions to extract the objects directly with the identified subjects. In order to eliminate the influence of irrelevant relations when predicting objects, we use a relation-special attention mechanism and a gate unit to select appropriate relations. In addition, most current models do not account for two-way interaction between tasks, so we design a feature interactive network to achieve bidirectional interaction between subject and object extraction tasks and enhance their connection. Experimental results on NYT, WebNLG, NYT<span><math><msup><mrow></mrow><mrow><mo>⋆</mo></mrow></msup></math></span> and WebNLG<span><math><msup><mrow></mrow><mrow><mo>⋆</mo></mrow></msup></math></span> datasets show that our model is competitive among joint extraction models.</div></div>","PeriodicalId":50638,"journal":{"name":"Computer Speech and Language","volume":"90 ","pages":"Article 101734"},"PeriodicalIF":3.0000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Taking relations as known conditions: A tagging based method for relational triple extraction\",\"authors\":\"Guanqing Kong , Qi Lei\",\"doi\":\"10.1016/j.csl.2024.101734\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Relational triple extraction refers to extracting entities and relations from natural texts, which is a crucial task in the construction of knowledge graph. Recently, tagging based methods have received increasing attention because of their simple and effective structural form. Among them, the two-step extraction method is easy to cause the problem of category imbalance. To address this issue, we propose a novel two-step extraction method, which first extracts subjects, generates a fixed-size embedding for each relation, and then regards these relations as known conditions to extract the objects directly with the identified subjects. In order to eliminate the influence of irrelevant relations when predicting objects, we use a relation-special attention mechanism and a gate unit to select appropriate relations. In addition, most current models do not account for two-way interaction between tasks, so we design a feature interactive network to achieve bidirectional interaction between subject and object extraction tasks and enhance their connection. Experimental results on NYT, WebNLG, NYT<span><math><msup><mrow></mrow><mrow><mo>⋆</mo></mrow></msup></math></span> and WebNLG<span><math><msup><mrow></mrow><mrow><mo>⋆</mo></mrow></msup></math></span> datasets show that our model is competitive among joint extraction models.</div></div>\",\"PeriodicalId\":50638,\"journal\":{\"name\":\"Computer Speech and Language\",\"volume\":\"90 \",\"pages\":\"Article 101734\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2025-03-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Speech and Language\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0885230824001177\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/24 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Speech and Language","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0885230824001177","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/24 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Taking relations as known conditions: A tagging based method for relational triple extraction
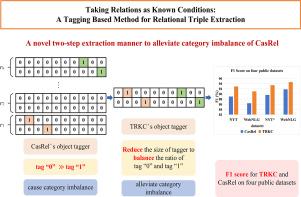
Relational triple extraction refers to extracting entities and relations from natural texts, which is a crucial task in the construction of knowledge graph. Recently, tagging based methods have received increasing attention because of their simple and effective structural form. Among them, the two-step extraction method is easy to cause the problem of category imbalance. To address this issue, we propose a novel two-step extraction method, which first extracts subjects, generates a fixed-size embedding for each relation, and then regards these relations as known conditions to extract the objects directly with the identified subjects. In order to eliminate the influence of irrelevant relations when predicting objects, we use a relation-special attention mechanism and a gate unit to select appropriate relations. In addition, most current models do not account for two-way interaction between tasks, so we design a feature interactive network to achieve bidirectional interaction between subject and object extraction tasks and enhance their connection. Experimental results on NYT, WebNLG, NYT and WebNLG datasets show that our model is competitive among joint extraction models.
期刊介绍:
Computer Speech & Language publishes reports of original research related to the recognition, understanding, production, coding and mining of speech and language.
The speech and language sciences have a long history, but it is only relatively recently that large-scale implementation of and experimentation with complex models of speech and language processing has become feasible. Such research is often carried out somewhat separately by practitioners of artificial intelligence, computer science, electronic engineering, information retrieval, linguistics, phonetics, or psychology.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
