{"title":"解读用于预测翻译率的深度神经网络。","authors":"Frederick Korbel, Ekaterina Eroshok, Uwe Ohler","doi":"10.1186/s12864-024-10925-8","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The 5' untranslated region of mRNA strongly impacts the rate of translation initiation. A recent convolutional neural network (CNN) model accurately quantifies the relationship between massively parallel synthetic 5' untranslated regions (5'UTRs) and translation levels. However, the underlying biological features, which drive model predictions, remain elusive. Uncovering sequence determinants predictive of translation output may allow us to develop a more detailed understanding of translation regulation at the 5'UTR.</p><p><strong>Results: </strong>Applying model interpretation, we extract representations of regulatory logic from CNNs trained on synthetic and human 5'UTR reporter data. We reveal a complex interplay of regulatory sequence elements, such as initiation context and upstream open reading frames (uORFs) to influence model predictions. We show that models trained on synthetic data alone do not sufficiently explain translation regulation via the 5'UTR due to differences in the frequency of regulatory motifs compared to natural 5'UTRs.</p><p><strong>Conclusions: </strong>Our study demonstrates the significance of model interpretation in understanding model behavior, properties of experimental data and ultimately mRNA translation. By combining synthetic and human 5'UTR reporter data, we develop a model (OptMRL) which better captures the characteristics of human translation regulation. This approach provides a general strategy for building more successful sequence-based models of gene regulation, as it combines global sampling of random sequences with the subspace of naturally occurring sequences. Ultimately, this will enhance our understanding of 5'UTR sequences in disease and our ability to engineer translation output.</p>","PeriodicalId":9030,"journal":{"name":"BMC Genomics","volume":"25 1","pages":"1061"},"PeriodicalIF":3.7000,"publicationDate":"2024-11-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11549864/pdf/","citationCount":"0","resultStr":"{\"title\":\"Interpreting deep neural networks for the prediction of translation rates.\",\"authors\":\"Frederick Korbel, Ekaterina Eroshok, Uwe Ohler\",\"doi\":\"10.1186/s12864-024-10925-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The 5' untranslated region of mRNA strongly impacts the rate of translation initiation. A recent convolutional neural network (CNN) model accurately quantifies the relationship between massively parallel synthetic 5' untranslated regions (5'UTRs) and translation levels. However, the underlying biological features, which drive model predictions, remain elusive. Uncovering sequence determinants predictive of translation output may allow us to develop a more detailed understanding of translation regulation at the 5'UTR.</p><p><strong>Results: </strong>Applying model interpretation, we extract representations of regulatory logic from CNNs trained on synthetic and human 5'UTR reporter data. We reveal a complex interplay of regulatory sequence elements, such as initiation context and upstream open reading frames (uORFs) to influence model predictions. We show that models trained on synthetic data alone do not sufficiently explain translation regulation via the 5'UTR due to differences in the frequency of regulatory motifs compared to natural 5'UTRs.</p><p><strong>Conclusions: </strong>Our study demonstrates the significance of model interpretation in understanding model behavior, properties of experimental data and ultimately mRNA translation. By combining synthetic and human 5'UTR reporter data, we develop a model (OptMRL) which better captures the characteristics of human translation regulation. This approach provides a general strategy for building more successful sequence-based models of gene regulation, as it combines global sampling of random sequences with the subspace of naturally occurring sequences. Ultimately, this will enhance our understanding of 5'UTR sequences in disease and our ability to engineer translation output.</p>\",\"PeriodicalId\":9030,\"journal\":{\"name\":\"BMC Genomics\",\"volume\":\"25 1\",\"pages\":\"1061\"},\"PeriodicalIF\":3.7000,\"publicationDate\":\"2024-11-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11549864/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Genomics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s12864-024-10925-8\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOTECHNOLOGY & APPLIED MICROBIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Genomics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s12864-024-10925-8","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOTECHNOLOGY & APPLIED MICROBIOLOGY","Score":null,"Total":0}
Interpreting deep neural networks for the prediction of translation rates.
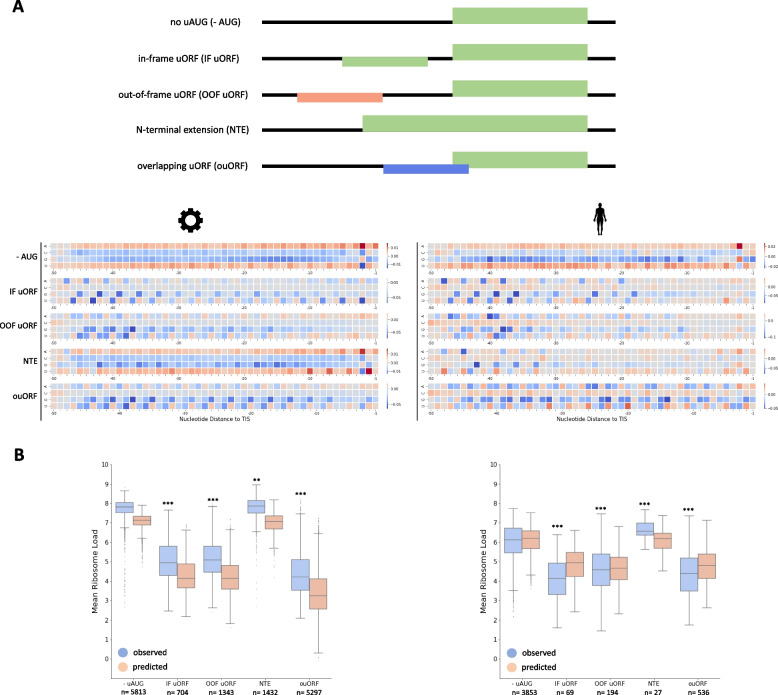
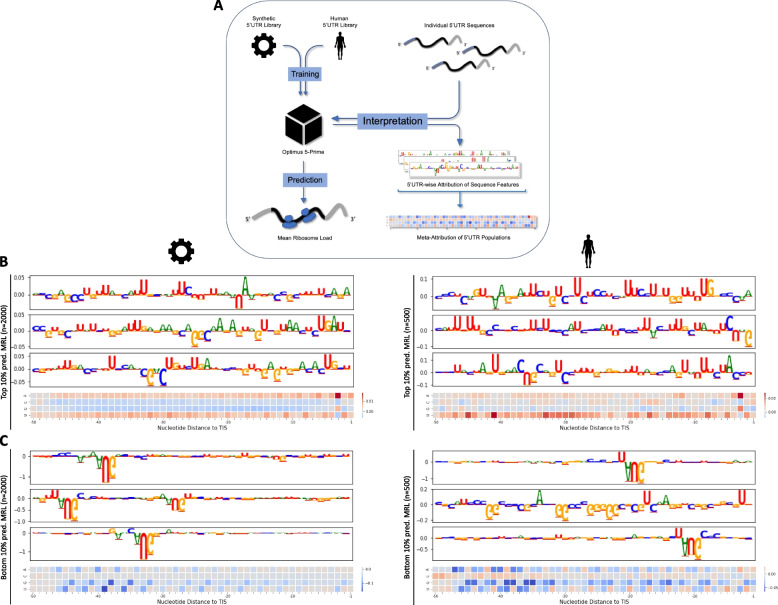
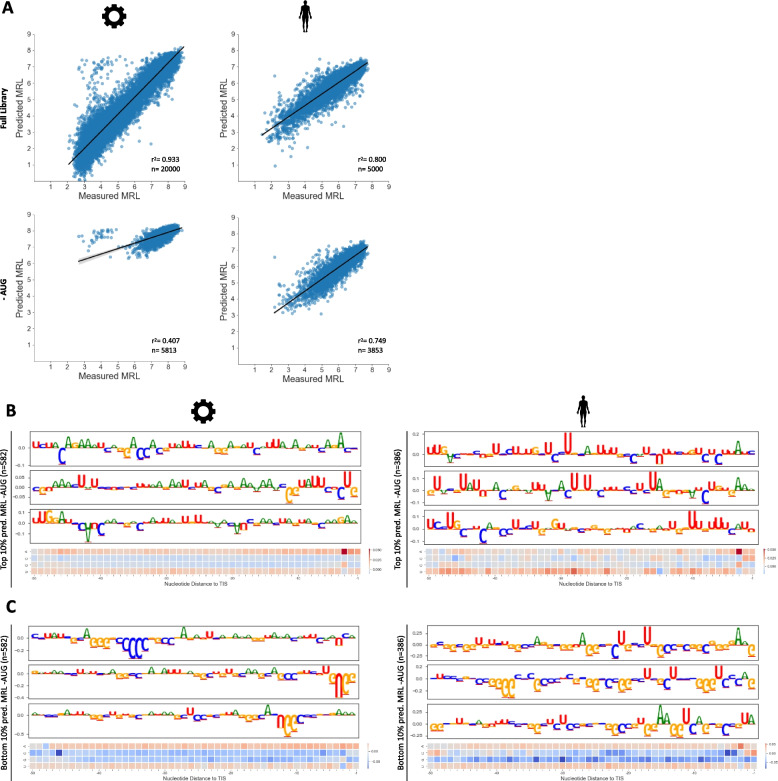
Background: The 5' untranslated region of mRNA strongly impacts the rate of translation initiation. A recent convolutional neural network (CNN) model accurately quantifies the relationship between massively parallel synthetic 5' untranslated regions (5'UTRs) and translation levels. However, the underlying biological features, which drive model predictions, remain elusive. Uncovering sequence determinants predictive of translation output may allow us to develop a more detailed understanding of translation regulation at the 5'UTR.
Results: Applying model interpretation, we extract representations of regulatory logic from CNNs trained on synthetic and human 5'UTR reporter data. We reveal a complex interplay of regulatory sequence elements, such as initiation context and upstream open reading frames (uORFs) to influence model predictions. We show that models trained on synthetic data alone do not sufficiently explain translation regulation via the 5'UTR due to differences in the frequency of regulatory motifs compared to natural 5'UTRs.
Conclusions: Our study demonstrates the significance of model interpretation in understanding model behavior, properties of experimental data and ultimately mRNA translation. By combining synthetic and human 5'UTR reporter data, we develop a model (OptMRL) which better captures the characteristics of human translation regulation. This approach provides a general strategy for building more successful sequence-based models of gene regulation, as it combines global sampling of random sequences with the subspace of naturally occurring sequences. Ultimately, this will enhance our understanding of 5'UTR sequences in disease and our ability to engineer translation output.
期刊介绍:
BMC Genomics is an open access, peer-reviewed journal that considers articles on all aspects of genome-scale analysis, functional genomics, and proteomics.
BMC Genomics is part of the BMC series which publishes subject-specific journals focused on the needs of individual research communities across all areas of biology and medicine. We offer an efficient, fair and friendly peer review service, and are committed to publishing all sound science, provided that there is some advance in knowledge presented by the work.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
