{"title":"GRL-PUL:基于图表示学习和正向无标记学习预测微生物与药物的关联。","authors":"Jinqing Liang, Yuping Sun and Jie Ling","doi":"10.1039/D4MO00117F","DOIUrl":null,"url":null,"abstract":"<p >Extensive research has confirmed the widespread presence of microorganisms in the human body and their crucial impact on human health, with drugs being an effective method of regulation. Hence it is essential to identify potential microbe–drug associations (MDAs). Owing to the limitations of wet experiments, such as high costs and long durations, computational methods for binary classification tasks have become valuable alternatives for traditional experimental approaches. Since validated negative MDAs are absent in existing datasets, most methods randomly sample negatives from unlabeled data, which evidently leads to false negative issues. In this manuscript, we propose a novel model based on graph representation learning and positive-unlabeled learning (GRL–PUL), to infer potential MDAs. Firstly, we screen reliable negative samples by applying weighted matrix factorization and the PU-bagging strategy on the known microbe–drug bipartite network. Then, we combine muti-model attributes and constructed a microbe–drug heterogeneous network. After that, graph attention auto-encoder module, an encoder combining graph convolutional networks and graph attention networks, is introduced to extract informative embeddings based on the microbe–drug heterogeneous network. Lastly, we adopt a modified random forest as the final classifier. Comparison experiments with five baseline models on three benchmark datasets show that our model surpasses other methods in terms of the AUC, AUPR, ACC, F1-score and MCC. Moreover, several case studies show that GRL–PUL could capably predict latent MDAs. Notably, we further verify the effectiveness of a reliable negative sample selection module by migrating it to other state-of-the-art models, and the experimental results demonstrate its ability to substantially improve their prediction performance.</p>","PeriodicalId":19065,"journal":{"name":"Molecular omics","volume":" 1","pages":" 38-50"},"PeriodicalIF":2.4000,"publicationDate":"2024-11-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"GRL–PUL: predicting microbe–drug association based on graph representation learning and positive unlabeled learning\",\"authors\":\"Jinqing Liang, Yuping Sun and Jie Ling\",\"doi\":\"10.1039/D4MO00117F\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Extensive research has confirmed the widespread presence of microorganisms in the human body and their crucial impact on human health, with drugs being an effective method of regulation. Hence it is essential to identify potential microbe–drug associations (MDAs). Owing to the limitations of wet experiments, such as high costs and long durations, computational methods for binary classification tasks have become valuable alternatives for traditional experimental approaches. Since validated negative MDAs are absent in existing datasets, most methods randomly sample negatives from unlabeled data, which evidently leads to false negative issues. In this manuscript, we propose a novel model based on graph representation learning and positive-unlabeled learning (GRL–PUL), to infer potential MDAs. Firstly, we screen reliable negative samples by applying weighted matrix factorization and the PU-bagging strategy on the known microbe–drug bipartite network. Then, we combine muti-model attributes and constructed a microbe–drug heterogeneous network. After that, graph attention auto-encoder module, an encoder combining graph convolutional networks and graph attention networks, is introduced to extract informative embeddings based on the microbe–drug heterogeneous network. Lastly, we adopt a modified random forest as the final classifier. Comparison experiments with five baseline models on three benchmark datasets show that our model surpasses other methods in terms of the AUC, AUPR, ACC, F1-score and MCC. Moreover, several case studies show that GRL–PUL could capably predict latent MDAs. Notably, we further verify the effectiveness of a reliable negative sample selection module by migrating it to other state-of-the-art models, and the experimental results demonstrate its ability to substantially improve their prediction performance.</p>\",\"PeriodicalId\":19065,\"journal\":{\"name\":\"Molecular omics\",\"volume\":\" 1\",\"pages\":\" 38-50\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2024-11-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular omics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://pubs.rsc.org/en/content/articlelanding/2025/mo/d4mo00117f\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular omics","FirstCategoryId":"99","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2025/mo/d4mo00117f","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
GRL–PUL: predicting microbe–drug association based on graph representation learning and positive unlabeled learning
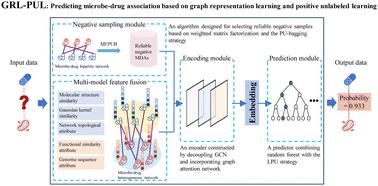
Extensive research has confirmed the widespread presence of microorganisms in the human body and their crucial impact on human health, with drugs being an effective method of regulation. Hence it is essential to identify potential microbe–drug associations (MDAs). Owing to the limitations of wet experiments, such as high costs and long durations, computational methods for binary classification tasks have become valuable alternatives for traditional experimental approaches. Since validated negative MDAs are absent in existing datasets, most methods randomly sample negatives from unlabeled data, which evidently leads to false negative issues. In this manuscript, we propose a novel model based on graph representation learning and positive-unlabeled learning (GRL–PUL), to infer potential MDAs. Firstly, we screen reliable negative samples by applying weighted matrix factorization and the PU-bagging strategy on the known microbe–drug bipartite network. Then, we combine muti-model attributes and constructed a microbe–drug heterogeneous network. After that, graph attention auto-encoder module, an encoder combining graph convolutional networks and graph attention networks, is introduced to extract informative embeddings based on the microbe–drug heterogeneous network. Lastly, we adopt a modified random forest as the final classifier. Comparison experiments with five baseline models on three benchmark datasets show that our model surpasses other methods in terms of the AUC, AUPR, ACC, F1-score and MCC. Moreover, several case studies show that GRL–PUL could capably predict latent MDAs. Notably, we further verify the effectiveness of a reliable negative sample selection module by migrating it to other state-of-the-art models, and the experimental results demonstrate its ability to substantially improve their prediction performance.
Molecular omicsBiochemistry, Genetics and Molecular Biology-Biochemistry
CiteScore
5.40
自引率
3.40%
发文量
91
期刊介绍:
Molecular Omics publishes high-quality research from across the -omics sciences.
Topics include, but are not limited to:
-omics studies to gain mechanistic insight into biological processes – for example, determining the mode of action of a drug or the basis of a particular phenotype, such as drought tolerance
-omics studies for clinical applications with validation, such as finding biomarkers for diagnostics or potential new drug targets
-omics studies looking at the sub-cellular make-up of cells – for example, the subcellular localisation of certain proteins or post-translational modifications or new imaging techniques
-studies presenting new methods and tools to support omics studies, including new spectroscopic/chromatographic techniques, chip-based/array technologies and new classification/data analysis techniques. New methods should be proven and demonstrate an advance in the field.
Molecular Omics only accepts articles of high importance and interest that provide significant new insight into important chemical or biological problems. This could be fundamental research that significantly increases understanding or research that demonstrates clear functional benefits.
Papers reporting new results that could be routinely predicted, do not show a significant improvement over known research, or are of interest only to the specialist in the area are not suitable for publication in Molecular Omics.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
