Andrew Runge, Yigal Attali, Geoffrey T LaFlair, Yena Park, Jacqueline Church
{"title":"人工智能驱动的交互式听力评估任务。","authors":"Andrew Runge, Yigal Attali, Geoffrey T LaFlair, Yena Park, Jacqueline Church","doi":"10.3389/frai.2024.1474019","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Assessments of interactional competence have traditionally been limited in large-scale language assessments. The listening portion suffers from construct underrepresentation, whereas the speaking portion suffers from limited task formats such as in-person interviews or role plays. Human-delivered tasks are challenging to administer at large scales, while automated assessments are typically very narrow in their assessment of the construct because they have carried over the limitations of traditional paper-based tasks to digital formats. However, computer-based assessments do allow for more interactive, automatically administered tasks, but come with increased complexity in task creation. Large language models present new opportunities for enhanced automated item generation (AIG) processes that can create complex content types and tasks at scale that support richer assessments.</p><p><strong>Methods: </strong>This paper describes the use of such methods to generate content at scale for an interactive listening measure of interactional competence for the Duolingo English Test (DET), a large-scale, high-stakes test of English proficiency. The Interactive Listening task assesses test takers' ability to participate in a full conversation, resulting in a more authentic assessment of interactive listening ability than prior automated assessments by positing comprehension and interaction as purposes of listening.</p><p><strong>Results and discussion: </strong>The results of a pilot of 713 tasks with hundreds of responses per task, along with the results of human review, demonstrate the feasibility of a human-in-the-loop, generative AI-driven approach for automatic creation of complex educational assessments at scale.</p>","PeriodicalId":33315,"journal":{"name":"Frontiers in Artificial Intelligence","volume":"7 ","pages":"1474019"},"PeriodicalIF":4.7000,"publicationDate":"2024-11-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11571064/pdf/","citationCount":"0","resultStr":"{\"title\":\"A generative AI-driven interactive listening assessment task.\",\"authors\":\"Andrew Runge, Yigal Attali, Geoffrey T LaFlair, Yena Park, Jacqueline Church\",\"doi\":\"10.3389/frai.2024.1474019\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Assessments of interactional competence have traditionally been limited in large-scale language assessments. The listening portion suffers from construct underrepresentation, whereas the speaking portion suffers from limited task formats such as in-person interviews or role plays. Human-delivered tasks are challenging to administer at large scales, while automated assessments are typically very narrow in their assessment of the construct because they have carried over the limitations of traditional paper-based tasks to digital formats. However, computer-based assessments do allow for more interactive, automatically administered tasks, but come with increased complexity in task creation. Large language models present new opportunities for enhanced automated item generation (AIG) processes that can create complex content types and tasks at scale that support richer assessments.</p><p><strong>Methods: </strong>This paper describes the use of such methods to generate content at scale for an interactive listening measure of interactional competence for the Duolingo English Test (DET), a large-scale, high-stakes test of English proficiency. The Interactive Listening task assesses test takers' ability to participate in a full conversation, resulting in a more authentic assessment of interactive listening ability than prior automated assessments by positing comprehension and interaction as purposes of listening.</p><p><strong>Results and discussion: </strong>The results of a pilot of 713 tasks with hundreds of responses per task, along with the results of human review, demonstrate the feasibility of a human-in-the-loop, generative AI-driven approach for automatic creation of complex educational assessments at scale.</p>\",\"PeriodicalId\":33315,\"journal\":{\"name\":\"Frontiers in Artificial Intelligence\",\"volume\":\"7 \",\"pages\":\"1474019\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2024-11-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11571064/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Artificial Intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/frai.2024.1474019\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Artificial Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/frai.2024.1474019","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
简介在大规模语言评估中,对互动能力的评估历来受到限制。听力部分存在语篇代表性不足的问题,而口语部分则存在任务形式有限的问题,如面谈或角色扮演。大规模的人工任务具有挑战性,而自动评估由于将传统纸质任务的局限性转化为数字格式,因此对语构的评估通常非常狭窄。不过,基于计算机的评估的确可以实现互动性更强的自动管理任务,但同时也增加了任务创建的复杂性。大型语言模型为增强自动项目生成(AIG)流程提供了新的机遇,该流程可以大规模创建复杂的内容类型和任务,从而支持更丰富的评估:本文介绍了如何利用这些方法为杜林格英语测试(Duolingo English Test,DET)(一项大规模、高风险的英语水平测试)的互动听力能力测量大规模生成内容。互动听力任务评估的是应试者参与完整对话的能力,通过将理解和互动作为听力的目的,对互动听力能力的评估比以前的自动评估更加真实:713 项任务的试验结果(每项任务有数百个回答)以及人工审核的结果,证明了以人工智能为驱动的 "人在回路中 "生成方法在大规模自动创建复杂教育评估方面的可行性。
A generative AI-driven interactive listening assessment task.
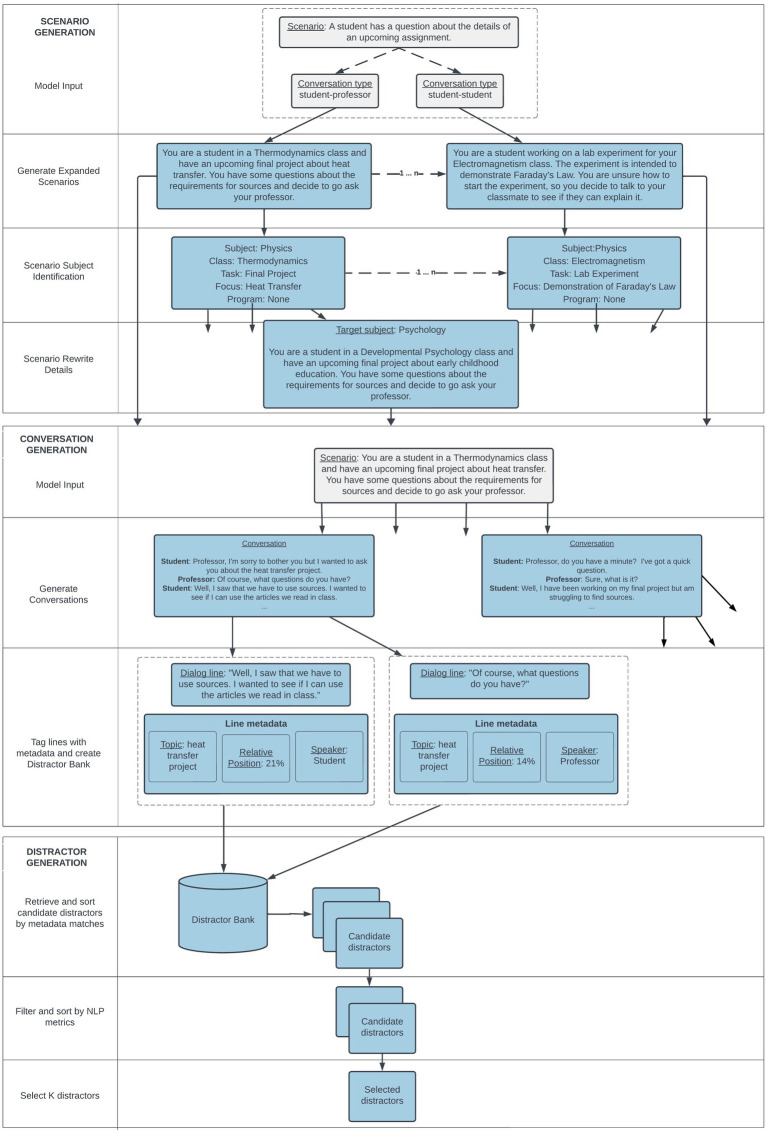
Introduction: Assessments of interactional competence have traditionally been limited in large-scale language assessments. The listening portion suffers from construct underrepresentation, whereas the speaking portion suffers from limited task formats such as in-person interviews or role plays. Human-delivered tasks are challenging to administer at large scales, while automated assessments are typically very narrow in their assessment of the construct because they have carried over the limitations of traditional paper-based tasks to digital formats. However, computer-based assessments do allow for more interactive, automatically administered tasks, but come with increased complexity in task creation. Large language models present new opportunities for enhanced automated item generation (AIG) processes that can create complex content types and tasks at scale that support richer assessments.
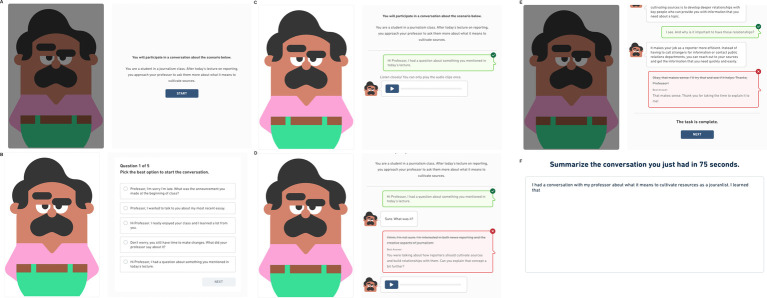
Methods: This paper describes the use of such methods to generate content at scale for an interactive listening measure of interactional competence for the Duolingo English Test (DET), a large-scale, high-stakes test of English proficiency. The Interactive Listening task assesses test takers' ability to participate in a full conversation, resulting in a more authentic assessment of interactive listening ability than prior automated assessments by positing comprehension and interaction as purposes of listening.
Results and discussion: The results of a pilot of 713 tasks with hundreds of responses per task, along with the results of human review, demonstrate the feasibility of a human-in-the-loop, generative AI-driven approach for automatic creation of complex educational assessments at scale.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
