{"title":"临床试验药物疗效检测总分模型的功效及1型误差比较。","authors":"Elham Haem, Mats O Karlsson, Sebastian Ueckert","doi":"10.1007/s10928-024-09949-0","DOIUrl":null,"url":null,"abstract":"<p><p>Composite scale data consists of numerous categorical questions/items that are often summed as a total score and are commonly utilized as primary endpoints in clinical trials. These endpoints are conceptually discrete and constrained by nature. Item response theory (IRT) is a powerful approach for detecting drug effects in composite scale data from clinical trials, but estimating all parameters requires a large sample size and all item information, which may not be available. Therefore, total score models are often utilized. The most popular total score models are continuous variable (CV) models, but this strategy establishes assumptions that go against the integer nature, and typically also the bounded nature, of data. Bounded integer (BI) and Coarsened grid (CG) models respect the nature of the data. However, their power to detect drug effects has not been as thoroughly studied in clinical trials. When an IRT model is accessible, IRT-informed models (I-BI and I-CV) are promising methods in which the mean and variability of the total score at any position are extracted from the existing IRT model. In this study, total score data were simulated from the MDS-UPDRS motor subscale. Then, the power, type 1 error, and treatment effect bias of six total score models for detecting drug effects in clinical trials were explored. Further, it was investigated how the power, type 1 of error, and treatment effect bias for the I-BI and I-CV models were affected by mis-specified item information from the IRT model. The I-BI model demonstrated the highest statistical power, maintained an acceptable Type I error rate, and exhibited minimal bias, approaching zero. Following that, the I-CV, BI, and CG with Czado transformation (CG_Czado) models provided the maximum power. However, the CG_Czado model had inflated type 1 error under low sample size scenarios in each arm of clinical trials. The CG model among total score models displayed the lowest power and the most inflated type 1 error. Therefore, the results favor the I-BI model when an IRT model is available; otherwise, the BI model.</p>","PeriodicalId":16851,"journal":{"name":"Journal of Pharmacokinetics and Pharmacodynamics","volume":"52 1","pages":"4"},"PeriodicalIF":2.8000,"publicationDate":"2024-12-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11632077/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparison of the power and type 1 error of total score models for drug effect detection in clinical trials.\",\"authors\":\"Elham Haem, Mats O Karlsson, Sebastian Ueckert\",\"doi\":\"10.1007/s10928-024-09949-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Composite scale data consists of numerous categorical questions/items that are often summed as a total score and are commonly utilized as primary endpoints in clinical trials. These endpoints are conceptually discrete and constrained by nature. Item response theory (IRT) is a powerful approach for detecting drug effects in composite scale data from clinical trials, but estimating all parameters requires a large sample size and all item information, which may not be available. Therefore, total score models are often utilized. The most popular total score models are continuous variable (CV) models, but this strategy establishes assumptions that go against the integer nature, and typically also the bounded nature, of data. Bounded integer (BI) and Coarsened grid (CG) models respect the nature of the data. However, their power to detect drug effects has not been as thoroughly studied in clinical trials. When an IRT model is accessible, IRT-informed models (I-BI and I-CV) are promising methods in which the mean and variability of the total score at any position are extracted from the existing IRT model. In this study, total score data were simulated from the MDS-UPDRS motor subscale. Then, the power, type 1 error, and treatment effect bias of six total score models for detecting drug effects in clinical trials were explored. Further, it was investigated how the power, type 1 of error, and treatment effect bias for the I-BI and I-CV models were affected by mis-specified item information from the IRT model. The I-BI model demonstrated the highest statistical power, maintained an acceptable Type I error rate, and exhibited minimal bias, approaching zero. Following that, the I-CV, BI, and CG with Czado transformation (CG_Czado) models provided the maximum power. However, the CG_Czado model had inflated type 1 error under low sample size scenarios in each arm of clinical trials. The CG model among total score models displayed the lowest power and the most inflated type 1 error. Therefore, the results favor the I-BI model when an IRT model is available; otherwise, the BI model.</p>\",\"PeriodicalId\":16851,\"journal\":{\"name\":\"Journal of Pharmacokinetics and Pharmacodynamics\",\"volume\":\"52 1\",\"pages\":\"4\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-12-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11632077/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Pharmacokinetics and Pharmacodynamics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s10928-024-09949-0\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pharmacokinetics and Pharmacodynamics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s10928-024-09949-0","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
Comparison of the power and type 1 error of total score models for drug effect detection in clinical trials.
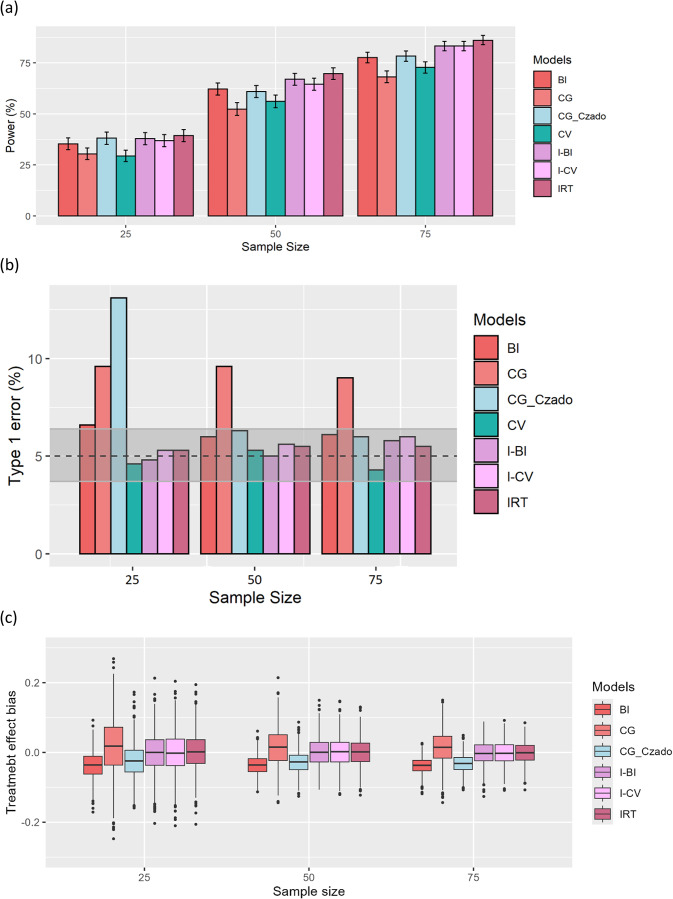
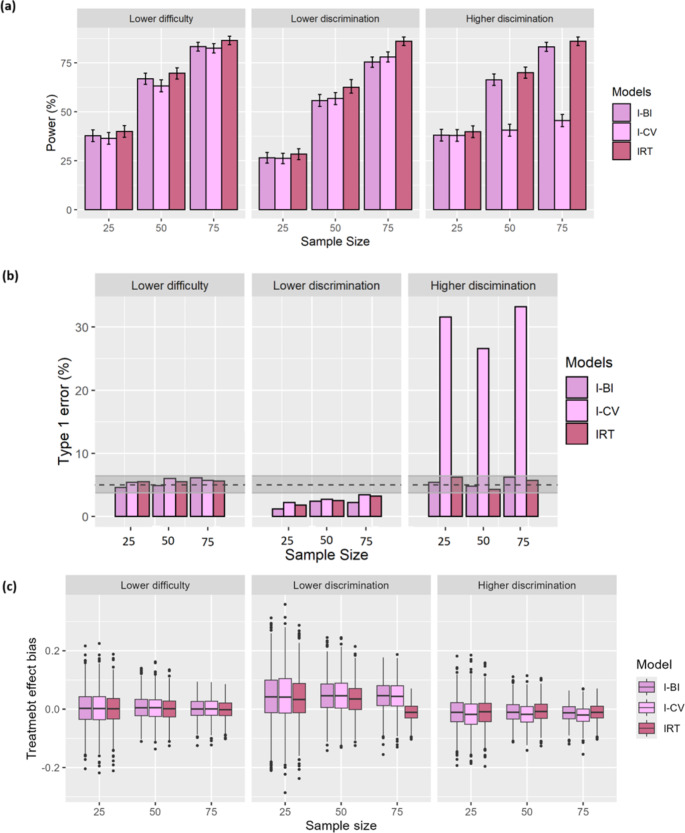
Composite scale data consists of numerous categorical questions/items that are often summed as a total score and are commonly utilized as primary endpoints in clinical trials. These endpoints are conceptually discrete and constrained by nature. Item response theory (IRT) is a powerful approach for detecting drug effects in composite scale data from clinical trials, but estimating all parameters requires a large sample size and all item information, which may not be available. Therefore, total score models are often utilized. The most popular total score models are continuous variable (CV) models, but this strategy establishes assumptions that go against the integer nature, and typically also the bounded nature, of data. Bounded integer (BI) and Coarsened grid (CG) models respect the nature of the data. However, their power to detect drug effects has not been as thoroughly studied in clinical trials. When an IRT model is accessible, IRT-informed models (I-BI and I-CV) are promising methods in which the mean and variability of the total score at any position are extracted from the existing IRT model. In this study, total score data were simulated from the MDS-UPDRS motor subscale. Then, the power, type 1 error, and treatment effect bias of six total score models for detecting drug effects in clinical trials were explored. Further, it was investigated how the power, type 1 of error, and treatment effect bias for the I-BI and I-CV models were affected by mis-specified item information from the IRT model. The I-BI model demonstrated the highest statistical power, maintained an acceptable Type I error rate, and exhibited minimal bias, approaching zero. Following that, the I-CV, BI, and CG with Czado transformation (CG_Czado) models provided the maximum power. However, the CG_Czado model had inflated type 1 error under low sample size scenarios in each arm of clinical trials. The CG model among total score models displayed the lowest power and the most inflated type 1 error. Therefore, the results favor the I-BI model when an IRT model is available; otherwise, the BI model.
期刊介绍:
Broadly speaking, the Journal of Pharmacokinetics and Pharmacodynamics covers the area of pharmacometrics. The journal is devoted to illustrating the importance of pharmacokinetics, pharmacodynamics, and pharmacometrics in drug development, clinical care, and the understanding of drug action. The journal publishes on a variety of topics related to pharmacometrics, including, but not limited to, clinical, experimental, and theoretical papers examining the kinetics of drug disposition and effects of drug action in humans, animals, in vitro, or in silico; modeling and simulation methodology, including optimal design; precision medicine; systems pharmacology; and mathematical pharmacology (including computational biology, bioengineering, and biophysics related to pharmacology, pharmacokinetics, orpharmacodynamics). Clinical papers that include population pharmacokinetic-pharmacodynamic relationships are welcome. The journal actively invites and promotes up-and-coming areas of pharmacometric research, such as real-world evidence, quality of life analyses, and artificial intelligence. The Journal of Pharmacokinetics and Pharmacodynamics is an official journal of the International Society of Pharmacometrics.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
