{"title":"基于本体增强大语言模型的罕见病知识图谱端到端自动构建系统研究。","authors":"Lang Cao, Jimeng Sun, Adam Cross","doi":"10.2196/60665","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Rare diseases affect millions worldwide but sometimes face limited research focus individually due to low prevalence. Many rare diseases do not have specific International Classification of Diseases, Ninth Edition (ICD-9) and Tenth Edition (ICD-10), codes and therefore cannot be reliably extracted from granular fields like \"Diagnosis\" and \"Problem List\" entries, which complicates tasks that require identification of patients with these conditions, including clinical trial recruitment and research efforts. Recent advancements in large language models (LLMs) have shown promise in automating the extraction of medical information, offering the potential to improve medical research, diagnosis, and management. However, most LLMs lack professional medical knowledge, especially concerning specific rare diseases, and cannot effectively manage rare disease data in its various ontological forms, making it unsuitable for these tasks.</p><p><strong>Objective: </strong>Our aim is to create an end-to-end system called automated rare disease mining (AutoRD), which automates the extraction of rare disease-related information from medical text, focusing on entities and their relations to other medical concepts, such as signs and symptoms. AutoRD integrates up-to-date ontologies with other structured knowledge and demonstrates superior performance in rare disease extraction tasks. We conducted various experiments to evaluate AutoRD's performance, aiming to surpass common LLMs and traditional methods.</p><p><strong>Methods: </strong>AutoRD is a pipeline system that involves data preprocessing, entity extraction, relation extraction, entity calibration, and knowledge graph construction. We implemented this system using GPT-4 and medical knowledge graphs developed from the open-source Human Phenotype and Orphanet ontologies, using techniques such as chain-of-thought reasoning and prompt engineering. We quantitatively evaluated our system's performance in entity extraction, relation extraction, and knowledge graph construction. The experiment used the well-curated dataset RareDis2023, which contains medical literature focused on rare disease entities and their relations, making it an ideal dataset for training and testing our methodology.</p><p><strong>Results: </strong>On the RareDis2023 dataset, AutoRD achieved an overall entity extraction F1-score of 56.1% and a relation extraction F1-score of 38.6%, marking a 14.4% improvement over the baseline LLM. Notably, the F1-score for rare disease entity extraction reached 83.5%, indicating high precision and recall in identifying rare disease mentions. These results demonstrate the effectiveness of integrating LLMs with medical ontologies in extracting complex rare disease information.</p><p><strong>Conclusions: </strong>AutoRD is an automated end-to-end system for extracting rare disease information from text to build knowledge graphs, addressing critical limitations of existing LLMs by improving identification of these diseases and connecting them to related clinical features. This work underscores the significant potential of LLMs in transforming health care, particularly in the rare disease domain. By leveraging ontology-enhanced LLMs, AutoRD constructs a robust medical knowledge base that incorporates up-to-date rare disease information, facilitating improved identification of patients and resulting in more inclusive research and trial candidacy efforts.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"12 ","pages":"e60665"},"PeriodicalIF":3.8000,"publicationDate":"2024-12-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11683654/pdf/","citationCount":"0","resultStr":"{\"title\":\"An Automatic and End-to-End System for Rare Disease Knowledge Graph Construction Based on Ontology-Enhanced Large Language Models: Development Study.\",\"authors\":\"Lang Cao, Jimeng Sun, Adam Cross\",\"doi\":\"10.2196/60665\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Rare diseases affect millions worldwide but sometimes face limited research focus individually due to low prevalence. Many rare diseases do not have specific International Classification of Diseases, Ninth Edition (ICD-9) and Tenth Edition (ICD-10), codes and therefore cannot be reliably extracted from granular fields like \\\"Diagnosis\\\" and \\\"Problem List\\\" entries, which complicates tasks that require identification of patients with these conditions, including clinical trial recruitment and research efforts. Recent advancements in large language models (LLMs) have shown promise in automating the extraction of medical information, offering the potential to improve medical research, diagnosis, and management. However, most LLMs lack professional medical knowledge, especially concerning specific rare diseases, and cannot effectively manage rare disease data in its various ontological forms, making it unsuitable for these tasks.</p><p><strong>Objective: </strong>Our aim is to create an end-to-end system called automated rare disease mining (AutoRD), which automates the extraction of rare disease-related information from medical text, focusing on entities and their relations to other medical concepts, such as signs and symptoms. AutoRD integrates up-to-date ontologies with other structured knowledge and demonstrates superior performance in rare disease extraction tasks. We conducted various experiments to evaluate AutoRD's performance, aiming to surpass common LLMs and traditional methods.</p><p><strong>Methods: </strong>AutoRD is a pipeline system that involves data preprocessing, entity extraction, relation extraction, entity calibration, and knowledge graph construction. We implemented this system using GPT-4 and medical knowledge graphs developed from the open-source Human Phenotype and Orphanet ontologies, using techniques such as chain-of-thought reasoning and prompt engineering. We quantitatively evaluated our system's performance in entity extraction, relation extraction, and knowledge graph construction. The experiment used the well-curated dataset RareDis2023, which contains medical literature focused on rare disease entities and their relations, making it an ideal dataset for training and testing our methodology.</p><p><strong>Results: </strong>On the RareDis2023 dataset, AutoRD achieved an overall entity extraction F1-score of 56.1% and a relation extraction F1-score of 38.6%, marking a 14.4% improvement over the baseline LLM. Notably, the F1-score for rare disease entity extraction reached 83.5%, indicating high precision and recall in identifying rare disease mentions. These results demonstrate the effectiveness of integrating LLMs with medical ontologies in extracting complex rare disease information.</p><p><strong>Conclusions: </strong>AutoRD is an automated end-to-end system for extracting rare disease information from text to build knowledge graphs, addressing critical limitations of existing LLMs by improving identification of these diseases and connecting them to related clinical features. This work underscores the significant potential of LLMs in transforming health care, particularly in the rare disease domain. By leveraging ontology-enhanced LLMs, AutoRD constructs a robust medical knowledge base that incorporates up-to-date rare disease information, facilitating improved identification of patients and resulting in more inclusive research and trial candidacy efforts.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"12 \",\"pages\":\"e60665\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-12-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11683654/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/60665\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/60665","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
An Automatic and End-to-End System for Rare Disease Knowledge Graph Construction Based on Ontology-Enhanced Large Language Models: Development Study.
Background: Rare diseases affect millions worldwide but sometimes face limited research focus individually due to low prevalence. Many rare diseases do not have specific International Classification of Diseases, Ninth Edition (ICD-9) and Tenth Edition (ICD-10), codes and therefore cannot be reliably extracted from granular fields like "Diagnosis" and "Problem List" entries, which complicates tasks that require identification of patients with these conditions, including clinical trial recruitment and research efforts. Recent advancements in large language models (LLMs) have shown promise in automating the extraction of medical information, offering the potential to improve medical research, diagnosis, and management. However, most LLMs lack professional medical knowledge, especially concerning specific rare diseases, and cannot effectively manage rare disease data in its various ontological forms, making it unsuitable for these tasks.
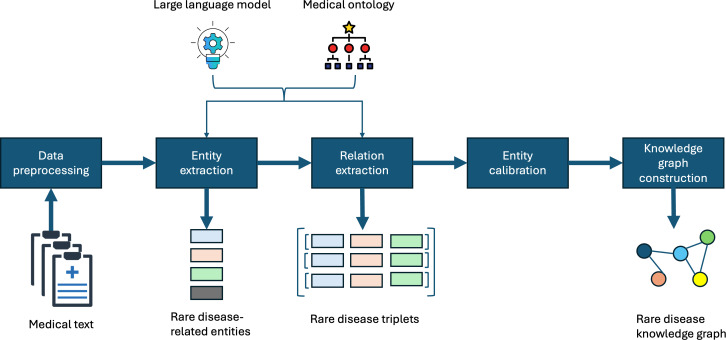
Objective: Our aim is to create an end-to-end system called automated rare disease mining (AutoRD), which automates the extraction of rare disease-related information from medical text, focusing on entities and their relations to other medical concepts, such as signs and symptoms. AutoRD integrates up-to-date ontologies with other structured knowledge and demonstrates superior performance in rare disease extraction tasks. We conducted various experiments to evaluate AutoRD's performance, aiming to surpass common LLMs and traditional methods.
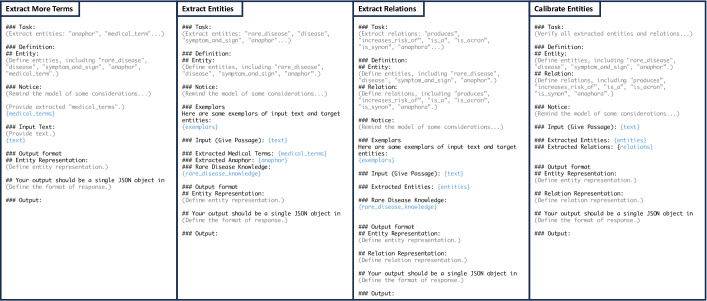
Methods: AutoRD is a pipeline system that involves data preprocessing, entity extraction, relation extraction, entity calibration, and knowledge graph construction. We implemented this system using GPT-4 and medical knowledge graphs developed from the open-source Human Phenotype and Orphanet ontologies, using techniques such as chain-of-thought reasoning and prompt engineering. We quantitatively evaluated our system's performance in entity extraction, relation extraction, and knowledge graph construction. The experiment used the well-curated dataset RareDis2023, which contains medical literature focused on rare disease entities and their relations, making it an ideal dataset for training and testing our methodology.
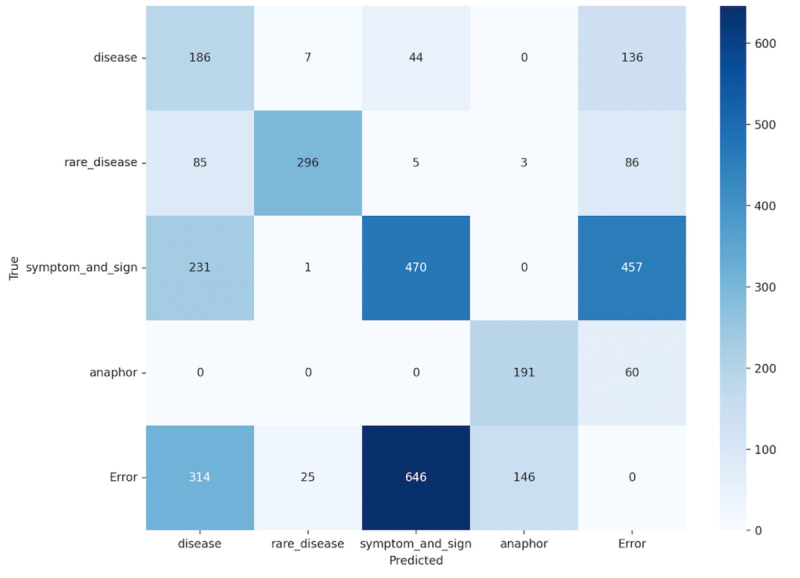
Results: On the RareDis2023 dataset, AutoRD achieved an overall entity extraction F1-score of 56.1% and a relation extraction F1-score of 38.6%, marking a 14.4% improvement over the baseline LLM. Notably, the F1-score for rare disease entity extraction reached 83.5%, indicating high precision and recall in identifying rare disease mentions. These results demonstrate the effectiveness of integrating LLMs with medical ontologies in extracting complex rare disease information.
Conclusions: AutoRD is an automated end-to-end system for extracting rare disease information from text to build knowledge graphs, addressing critical limitations of existing LLMs by improving identification of these diseases and connecting them to related clinical features. This work underscores the significant potential of LLMs in transforming health care, particularly in the rare disease domain. By leveraging ontology-enhanced LLMs, AutoRD constructs a robust medical knowledge base that incorporates up-to-date rare disease information, facilitating improved identification of patients and resulting in more inclusive research and trial candidacy efforts.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
