Amy Hughes, Pablo Vangeenderhuysen, Marilyn De Graeve, Beata Pomian, Tim S. Nawrot, Jeroen Raes, Simon J. S. Cameron, Lynn Vanhaecke
{"title":"基于lc - ms的人体生物体液代谢组学特征自动预处理研究","authors":"Amy Hughes, Pablo Vangeenderhuysen, Marilyn De Graeve, Beata Pomian, Tim S. Nawrot, Jeroen Raes, Simon J. S. Cameron, Lynn Vanhaecke","doi":"10.1021/acs.analchem.4c03124","DOIUrl":null,"url":null,"abstract":"Maximizing the extraction of true, high-quality, nonredundant features from biofluids analyzed via LC-MS systems is challenging. Here, the R packages IPO and AutoTuner were used to optimize XCMS parameter settings for the retrieval of metabolite or lipid features in both ionization modes from either faecal or urine samples from two cohorts (<i>n</i> = 621). The feature lists obtained were compared with those where the parameter values were selected manually. Three categories were used to compare feature lists: 1) feature quality through removing false positives, 2) tentative metabolite identification using the Human Metabolome Database (HMDB) and 3) feature utility such as analyzing the proportion of features within intensity threshold bins. Furthermore, a PCA-based approach to feature filtering using QC samples and variable loadings was also explored under this category. Overall, more features were observed after automated selection of parameter values for all data sets (1.3- to 3.7-fold), which propagated through comparative exercises. For example, a greater number of features (on average 51 vs 45%) had a coefficient of variation (CV) < 30%. Additionally, there was a significant increase (7.6–10.4%) in the number of faecal metabolites that could be tentatively annotated, and more features were present in higher intensity threshold bins. Considering the overlap across all three categories, a greater number of features were also retained. Automated approaches that guide selection of optimal parameter values for preprocessing are important to decrease the time invested for this step, while taking advantage of the wealth of data that LC-MS systems provide.","PeriodicalId":27,"journal":{"name":"Analytical Chemistry","volume":"37 1","pages":""},"PeriodicalIF":6.7000,"publicationDate":"2025-01-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Toward Automated Preprocessing of Untargeted LC-MS-Based Metabolomics Feature Lists from Human Biofluids\",\"authors\":\"Amy Hughes, Pablo Vangeenderhuysen, Marilyn De Graeve, Beata Pomian, Tim S. Nawrot, Jeroen Raes, Simon J. S. Cameron, Lynn Vanhaecke\",\"doi\":\"10.1021/acs.analchem.4c03124\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Maximizing the extraction of true, high-quality, nonredundant features from biofluids analyzed via LC-MS systems is challenging. Here, the R packages IPO and AutoTuner were used to optimize XCMS parameter settings for the retrieval of metabolite or lipid features in both ionization modes from either faecal or urine samples from two cohorts (<i>n</i> = 621). The feature lists obtained were compared with those where the parameter values were selected manually. Three categories were used to compare feature lists: 1) feature quality through removing false positives, 2) tentative metabolite identification using the Human Metabolome Database (HMDB) and 3) feature utility such as analyzing the proportion of features within intensity threshold bins. Furthermore, a PCA-based approach to feature filtering using QC samples and variable loadings was also explored under this category. Overall, more features were observed after automated selection of parameter values for all data sets (1.3- to 3.7-fold), which propagated through comparative exercises. For example, a greater number of features (on average 51 vs 45%) had a coefficient of variation (CV) < 30%. Additionally, there was a significant increase (7.6–10.4%) in the number of faecal metabolites that could be tentatively annotated, and more features were present in higher intensity threshold bins. Considering the overlap across all three categories, a greater number of features were also retained. Automated approaches that guide selection of optimal parameter values for preprocessing are important to decrease the time invested for this step, while taking advantage of the wealth of data that LC-MS systems provide.\",\"PeriodicalId\":27,\"journal\":{\"name\":\"Analytical Chemistry\",\"volume\":\"37 1\",\"pages\":\"\"},\"PeriodicalIF\":6.7000,\"publicationDate\":\"2025-01-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Analytical Chemistry\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.analchem.4c03124\",\"RegionNum\":1,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, ANALYTICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Analytical Chemistry","FirstCategoryId":"92","ListUrlMain":"https://doi.org/10.1021/acs.analchem.4c03124","RegionNum":1,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
引用次数: 0
摘要
最大限度地从LC-MS系统分析的生物流体中提取真实、高质量、无冗余的特征是一项挑战。在这里,使用R包IPO和AutoTuner优化XCMS参数设置,以便在两种电离模式下从两个队列(n = 621)的粪便或尿液样本中检索代谢物或脂质特征。将得到的特征列表与手动选择参数值的特征列表进行比较。通过三个类别来比较特征列表:1)通过去除假阳性的特征质量,2)使用人类代谢组数据库(HMDB)进行初步代谢物鉴定,3)特征效用,如分析强度阈值箱内特征的比例。此外,在此类别下还探讨了基于pca的使用QC样本和可变负载的特征滤波方法。总体而言,在所有数据集的参数值自动选择后(1.3- 3.7倍),通过比较练习传播,观察到更多的特征。例如,更多的特征(平均51 vs 45%)具有变异系数(CV) <;30%。此外,可以初步注释的粪便代谢物数量显著增加(7.6-10.4%),并且在高强度阈值箱中存在更多特征。考虑到这三个类别之间的重叠,还保留了更多的特征。指导选择最佳预处理参数值的自动化方法对于减少这一步投入的时间很重要,同时利用LC-MS系统提供的丰富数据。
Toward Automated Preprocessing of Untargeted LC-MS-Based Metabolomics Feature Lists from Human Biofluids
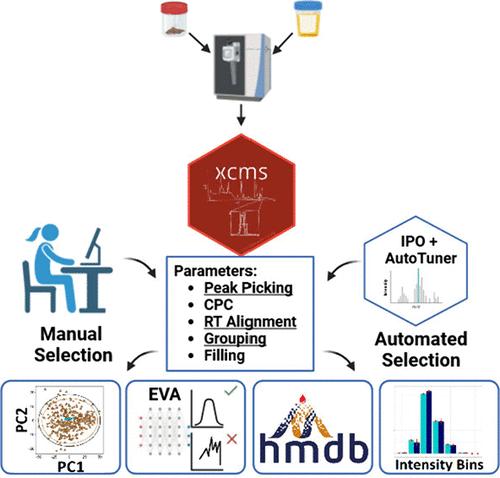
Maximizing the extraction of true, high-quality, nonredundant features from biofluids analyzed via LC-MS systems is challenging. Here, the R packages IPO and AutoTuner were used to optimize XCMS parameter settings for the retrieval of metabolite or lipid features in both ionization modes from either faecal or urine samples from two cohorts (n = 621). The feature lists obtained were compared with those where the parameter values were selected manually. Three categories were used to compare feature lists: 1) feature quality through removing false positives, 2) tentative metabolite identification using the Human Metabolome Database (HMDB) and 3) feature utility such as analyzing the proportion of features within intensity threshold bins. Furthermore, a PCA-based approach to feature filtering using QC samples and variable loadings was also explored under this category. Overall, more features were observed after automated selection of parameter values for all data sets (1.3- to 3.7-fold), which propagated through comparative exercises. For example, a greater number of features (on average 51 vs 45%) had a coefficient of variation (CV) < 30%. Additionally, there was a significant increase (7.6–10.4%) in the number of faecal metabolites that could be tentatively annotated, and more features were present in higher intensity threshold bins. Considering the overlap across all three categories, a greater number of features were also retained. Automated approaches that guide selection of optimal parameter values for preprocessing are important to decrease the time invested for this step, while taking advantage of the wealth of data that LC-MS systems provide.
期刊介绍:
Analytical Chemistry, a peer-reviewed research journal, focuses on disseminating new and original knowledge across all branches of analytical chemistry. Fundamental articles may explore general principles of chemical measurement science and need not directly address existing or potential analytical methodology. They can be entirely theoretical or report experimental results. Contributions may cover various phases of analytical operations, including sampling, bioanalysis, electrochemistry, mass spectrometry, microscale and nanoscale systems, environmental analysis, separations, spectroscopy, chemical reactions and selectivity, instrumentation, imaging, surface analysis, and data processing. Papers discussing known analytical methods should present a significant, original application of the method, a notable improvement, or results on an important analyte.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
