Lawrence McKnight, Chandra Jaiswal, Issa AlHmoud, Balakrishna Gokaraju
{"title":"基于MNIST和MNIST- c的跨基数据编码的深度学习性能数据集。","authors":"Lawrence McKnight, Chandra Jaiswal, Issa AlHmoud, Balakrishna Gokaraju","doi":"10.1016/j.dib.2024.111194","DOIUrl":null,"url":null,"abstract":"<p><p>Effective data representation in machine learning and deep learning is paramount. For an algorithm or neural network to capture patterns in data and be able to make reliable predictions, the data must appropriately describe the problem domain. Although there exists much literature on data preprocessing for machine learning and data science applications, novel data representation methods for enhancing machine learning model performance remain highly absent within the literature. This dataset is a compilation of convolutional neural network model performance trained and tested on a wide range of numerical base representations of the MNIST and MNIST-C datasets. This performance data can be further analysed by the research community to uncover trends in model performance against the numerical base of its data. This dataset can be used to produce more research of the same nature, testing cross-base data encoding on machine learning training and testing data for a wide range of real-world applications.</p>","PeriodicalId":10973,"journal":{"name":"Data in Brief","volume":"57 ","pages":"111194"},"PeriodicalIF":1.9000,"publicationDate":"2024-12-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11697575/pdf/","citationCount":"0","resultStr":"{\"title\":\"A dataset of deep learning performance from cross-base data encoding on MNIST and MNIST-C.\",\"authors\":\"Lawrence McKnight, Chandra Jaiswal, Issa AlHmoud, Balakrishna Gokaraju\",\"doi\":\"10.1016/j.dib.2024.111194\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Effective data representation in machine learning and deep learning is paramount. For an algorithm or neural network to capture patterns in data and be able to make reliable predictions, the data must appropriately describe the problem domain. Although there exists much literature on data preprocessing for machine learning and data science applications, novel data representation methods for enhancing machine learning model performance remain highly absent within the literature. This dataset is a compilation of convolutional neural network model performance trained and tested on a wide range of numerical base representations of the MNIST and MNIST-C datasets. This performance data can be further analysed by the research community to uncover trends in model performance against the numerical base of its data. This dataset can be used to produce more research of the same nature, testing cross-base data encoding on machine learning training and testing data for a wide range of real-world applications.</p>\",\"PeriodicalId\":10973,\"journal\":{\"name\":\"Data in Brief\",\"volume\":\"57 \",\"pages\":\"111194\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2024-12-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11697575/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Data in Brief\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1016/j.dib.2024.111194\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data in Brief","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.dib.2024.111194","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
A dataset of deep learning performance from cross-base data encoding on MNIST and MNIST-C.
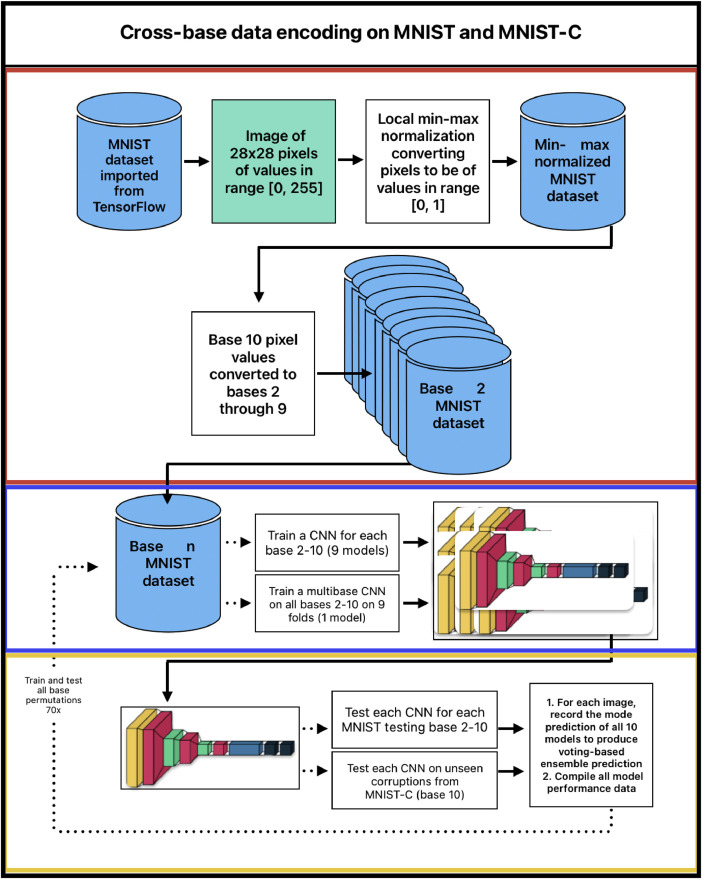
Effective data representation in machine learning and deep learning is paramount. For an algorithm or neural network to capture patterns in data and be able to make reliable predictions, the data must appropriately describe the problem domain. Although there exists much literature on data preprocessing for machine learning and data science applications, novel data representation methods for enhancing machine learning model performance remain highly absent within the literature. This dataset is a compilation of convolutional neural network model performance trained and tested on a wide range of numerical base representations of the MNIST and MNIST-C datasets. This performance data can be further analysed by the research community to uncover trends in model performance against the numerical base of its data. This dataset can be used to produce more research of the same nature, testing cross-base data encoding on machine learning training and testing data for a wide range of real-world applications.
期刊介绍:
Data in Brief provides a way for researchers to easily share and reuse each other''s datasets by publishing data articles that: -Thoroughly describe your data, facilitating reproducibility. -Make your data, which is often buried in supplementary material, easier to find. -Increase traffic towards associated research articles and data, leading to more citations. -Open up doors for new collaborations. Because you never know what data will be useful to someone else, Data in Brief welcomes submissions that describe data from all research areas.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
