{"title":"视网膜成像中的判别、生成人工智能和基础模型。","authors":"Paisan Ruamviboonsuk, Niracha Arjkongharn, Nattaporn Vongsa, Pawin Pakaymaskul, Natsuda Kaothanthong","doi":"10.4103/tjo.TJO-D-24-00064","DOIUrl":null,"url":null,"abstract":"<p><p>Recent advances of artificial intelligence (AI) in retinal imaging found its application in two major categories: discriminative and generative AI. For discriminative tasks, conventional convolutional neural networks (CNNs) are still major AI techniques. Vision transformers (ViT), inspired by the transformer architecture in natural language processing, has emerged as useful techniques for discriminating retinal images. ViT can attain excellent results when pretrained at sufficient scale and transferred to specific tasks with fewer images, compared to conventional CNN. Many studies found better performance of ViT, compared to CNN, for common tasks such as diabetic retinopathy screening on color fundus photographs (CFP) and segmentation of retinal fluid on optical coherence tomography (OCT) images. Generative Adversarial Network (GAN) is the main AI technique in generative AI in retinal imaging. Novel images generated by GAN can be applied for training AI models in imbalanced or inadequate datasets. Foundation models are also recent advances in retinal imaging. They are pretrained with huge datasets, such as millions of CFP and OCT images and fine-tuned for downstream tasks with much smaller datasets. A foundation model, RETFound, which was self-supervised and found to discriminate many eye and systemic diseases better than supervised models. Large language models are foundation models that may be applied for text-related tasks, like reports of retinal angiography. Whereas AI technology moves forward fast, real-world use of AI models moves slowly, making the gap between development and deployment even wider. Strong evidence showing AI models can prevent visual loss may be required to close this gap.</p>","PeriodicalId":44978,"journal":{"name":"Taiwan Journal of Ophthalmology","volume":"14 4","pages":"473-485"},"PeriodicalIF":1.2000,"publicationDate":"2024-11-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11717344/pdf/","citationCount":"0","resultStr":"{\"title\":\"Discriminative, generative artificial intelligence, and foundation models in retina imaging.\",\"authors\":\"Paisan Ruamviboonsuk, Niracha Arjkongharn, Nattaporn Vongsa, Pawin Pakaymaskul, Natsuda Kaothanthong\",\"doi\":\"10.4103/tjo.TJO-D-24-00064\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recent advances of artificial intelligence (AI) in retinal imaging found its application in two major categories: discriminative and generative AI. For discriminative tasks, conventional convolutional neural networks (CNNs) are still major AI techniques. Vision transformers (ViT), inspired by the transformer architecture in natural language processing, has emerged as useful techniques for discriminating retinal images. ViT can attain excellent results when pretrained at sufficient scale and transferred to specific tasks with fewer images, compared to conventional CNN. Many studies found better performance of ViT, compared to CNN, for common tasks such as diabetic retinopathy screening on color fundus photographs (CFP) and segmentation of retinal fluid on optical coherence tomography (OCT) images. Generative Adversarial Network (GAN) is the main AI technique in generative AI in retinal imaging. Novel images generated by GAN can be applied for training AI models in imbalanced or inadequate datasets. Foundation models are also recent advances in retinal imaging. They are pretrained with huge datasets, such as millions of CFP and OCT images and fine-tuned for downstream tasks with much smaller datasets. A foundation model, RETFound, which was self-supervised and found to discriminate many eye and systemic diseases better than supervised models. Large language models are foundation models that may be applied for text-related tasks, like reports of retinal angiography. Whereas AI technology moves forward fast, real-world use of AI models moves slowly, making the gap between development and deployment even wider. Strong evidence showing AI models can prevent visual loss may be required to close this gap.</p>\",\"PeriodicalId\":44978,\"journal\":{\"name\":\"Taiwan Journal of Ophthalmology\",\"volume\":\"14 4\",\"pages\":\"473-485\"},\"PeriodicalIF\":1.2000,\"publicationDate\":\"2024-11-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11717344/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Taiwan Journal of Ophthalmology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4103/tjo.TJO-D-24-00064\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q4\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Taiwan Journal of Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4103/tjo.TJO-D-24-00064","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Discriminative, generative artificial intelligence, and foundation models in retina imaging.
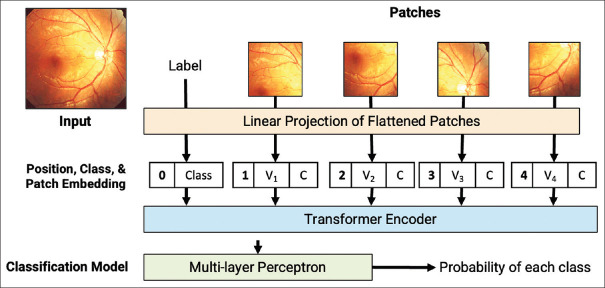
Recent advances of artificial intelligence (AI) in retinal imaging found its application in two major categories: discriminative and generative AI. For discriminative tasks, conventional convolutional neural networks (CNNs) are still major AI techniques. Vision transformers (ViT), inspired by the transformer architecture in natural language processing, has emerged as useful techniques for discriminating retinal images. ViT can attain excellent results when pretrained at sufficient scale and transferred to specific tasks with fewer images, compared to conventional CNN. Many studies found better performance of ViT, compared to CNN, for common tasks such as diabetic retinopathy screening on color fundus photographs (CFP) and segmentation of retinal fluid on optical coherence tomography (OCT) images. Generative Adversarial Network (GAN) is the main AI technique in generative AI in retinal imaging. Novel images generated by GAN can be applied for training AI models in imbalanced or inadequate datasets. Foundation models are also recent advances in retinal imaging. They are pretrained with huge datasets, such as millions of CFP and OCT images and fine-tuned for downstream tasks with much smaller datasets. A foundation model, RETFound, which was self-supervised and found to discriminate many eye and systemic diseases better than supervised models. Large language models are foundation models that may be applied for text-related tasks, like reports of retinal angiography. Whereas AI technology moves forward fast, real-world use of AI models moves slowly, making the gap between development and deployment even wider. Strong evidence showing AI models can prevent visual loss may be required to close this gap.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
