T Austin, D Kalra, N C Lea, D L H Patterson, D Ingram
{"title":"分析电子病历系统中用于抗凝管理的临床记录数据。","authors":"T Austin, D Kalra, N C Lea, D L H Patterson, D Ingram","doi":"10.2174/1874431100903010054","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>This paper reports an evaluation of the properties of a generic electronic health record information model that were actually required and used when importing an existing clinical application into a generic EHR repository.</p><p><strong>Method: </strong>A generic EHR repository and system were developed as part of the EU Projects Synapses and SynEx. A Web application to support the management of anticoagulation therapy was developed to interface to the EHR system, and deployed within a north London hospital with five years of cumulative clinical data from the previous existing anticoagulation management application. This offered the opportunity to critique those parts of the generic EHR that were actually needed to represent the legacy data.</p><p><strong>Results: </strong>The anticoagulation records from 3,226 patients were imported and represented using over 900,000 Record Components (i.e. each patient's record contained on average 289 nodes), of which around two thirds were Element Items (i.e. value-containing leaf nodes), the remainder being container nodes (i.e. headings and sub-headings). Each node is capable of incorporating a rich set of context properties, but in reality it was found that many properties were not used at all, and some infrequently (e.g. only around 0.5% of Record Components had ever been revised).</p><p><strong>Conclusions: </strong>The process of developing generic EHR information models, arising from research and embodied within new-generation interoperability standards and specifications, has been strongly driven by requirements. These requirements have been gathered primarily by collecting use cases and examples from clinical communities, and been added to successive generations of these models. A priority setting approach has not to date been pursued - all requirements have been received and almost invariably met. This work has shown how little of the resulting model is actually needed to represent useful and usable clinical data. A wider range of such evaluations, looking at different kinds of existing clinical system, is needed to balance the theoretical requirements gathering processes, in order to result in EHR information models of an ideal level of complexity.</p>","PeriodicalId":88331,"journal":{"name":"The open medical informatics journal","volume":"3 ","pages":"54-64"},"PeriodicalIF":0.0000,"publicationDate":"2009-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/6c/0c/TOMINFOJ-3-54.PMC2737130.pdf","citationCount":"0","resultStr":"{\"title\":\"Analysis of Clinical Record Data for Anticoagulation Management within an EHR System.\",\"authors\":\"T Austin, D Kalra, N C Lea, D L H Patterson, D Ingram\",\"doi\":\"10.2174/1874431100903010054\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>This paper reports an evaluation of the properties of a generic electronic health record information model that were actually required and used when importing an existing clinical application into a generic EHR repository.</p><p><strong>Method: </strong>A generic EHR repository and system were developed as part of the EU Projects Synapses and SynEx. A Web application to support the management of anticoagulation therapy was developed to interface to the EHR system, and deployed within a north London hospital with five years of cumulative clinical data from the previous existing anticoagulation management application. This offered the opportunity to critique those parts of the generic EHR that were actually needed to represent the legacy data.</p><p><strong>Results: </strong>The anticoagulation records from 3,226 patients were imported and represented using over 900,000 Record Components (i.e. each patient's record contained on average 289 nodes), of which around two thirds were Element Items (i.e. value-containing leaf nodes), the remainder being container nodes (i.e. headings and sub-headings). Each node is capable of incorporating a rich set of context properties, but in reality it was found that many properties were not used at all, and some infrequently (e.g. only around 0.5% of Record Components had ever been revised).</p><p><strong>Conclusions: </strong>The process of developing generic EHR information models, arising from research and embodied within new-generation interoperability standards and specifications, has been strongly driven by requirements. These requirements have been gathered primarily by collecting use cases and examples from clinical communities, and been added to successive generations of these models. A priority setting approach has not to date been pursued - all requirements have been received and almost invariably met. This work has shown how little of the resulting model is actually needed to represent useful and usable clinical data. A wider range of such evaluations, looking at different kinds of existing clinical system, is needed to balance the theoretical requirements gathering processes, in order to result in EHR information models of an ideal level of complexity.</p>\",\"PeriodicalId\":88331,\"journal\":{\"name\":\"The open medical informatics journal\",\"volume\":\"3 \",\"pages\":\"54-64\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2009-08-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/6c/0c/TOMINFOJ-3-54.PMC2737130.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The open medical informatics journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2174/1874431100903010054\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The open medical informatics journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2174/1874431100903010054","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Analysis of Clinical Record Data for Anticoagulation Management within an EHR System.
Objectives: This paper reports an evaluation of the properties of a generic electronic health record information model that were actually required and used when importing an existing clinical application into a generic EHR repository.
Method: A generic EHR repository and system were developed as part of the EU Projects Synapses and SynEx. A Web application to support the management of anticoagulation therapy was developed to interface to the EHR system, and deployed within a north London hospital with five years of cumulative clinical data from the previous existing anticoagulation management application. This offered the opportunity to critique those parts of the generic EHR that were actually needed to represent the legacy data.
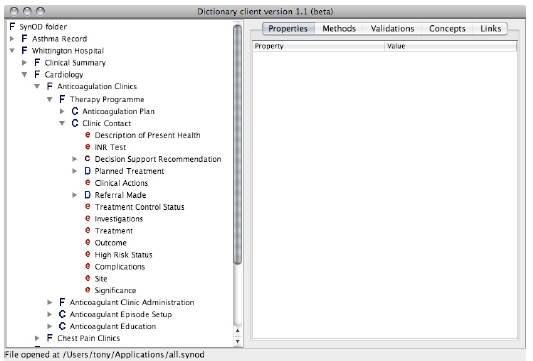
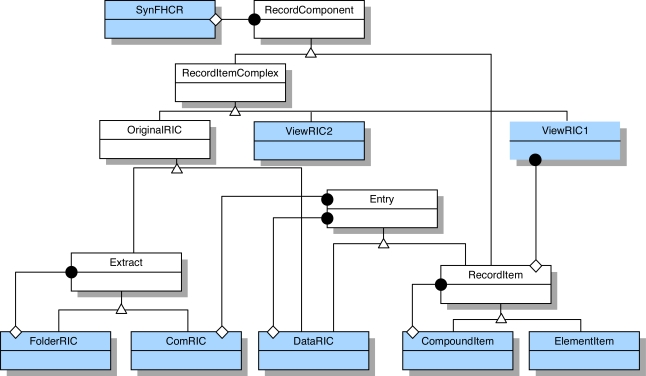
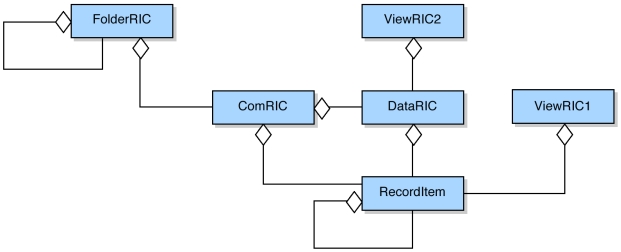
Results: The anticoagulation records from 3,226 patients were imported and represented using over 900,000 Record Components (i.e. each patient's record contained on average 289 nodes), of which around two thirds were Element Items (i.e. value-containing leaf nodes), the remainder being container nodes (i.e. headings and sub-headings). Each node is capable of incorporating a rich set of context properties, but in reality it was found that many properties were not used at all, and some infrequently (e.g. only around 0.5% of Record Components had ever been revised).
Conclusions: The process of developing generic EHR information models, arising from research and embodied within new-generation interoperability standards and specifications, has been strongly driven by requirements. These requirements have been gathered primarily by collecting use cases and examples from clinical communities, and been added to successive generations of these models. A priority setting approach has not to date been pursued - all requirements have been received and almost invariably met. This work has shown how little of the resulting model is actually needed to represent useful and usable clinical data. A wider range of such evaluations, looking at different kinds of existing clinical system, is needed to balance the theoretical requirements gathering processes, in order to result in EHR information models of an ideal level of complexity.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
