Youting Sun, Ulisses Braga-Neto, Edward R Dougherty
{"title":"缺失值输入对DNA微阵列基因表达数据分类的影响——基于模型的研究。","authors":"Youting Sun, Ulisses Braga-Neto, Edward R Dougherty","doi":"10.1155/2009/504069","DOIUrl":null,"url":null,"abstract":"<p><p>Many missing-value (MV) imputation methods have been developed for microarray data, but only a few studies have investigated the relationship between MV imputation and classification accuracy. Furthermore, these studies are problematic in fundamental steps such as MV generation and classifier error estimation. In this work, we carry out a model-based study that addresses some of the issues in previous studies. Six popular imputation algorithms, two feature selection methods, and three classification rules are considered. The results suggest that it is beneficial to apply MV imputation when the noise level is high, variance is small, or gene-cluster correlation is strong, under small to moderate MV rates. In these cases, if data quality metrics are available, then it may be helpful to consider the data point with poor quality as missing and apply one of the most robust imputation algorithms to estimate the true signal based on the available high-quality data points. However, at large MV rates, we conclude that imputation methods are not recommended. Regarding the MV rate, our results indicate the presence of a peaking phenomenon: performance of imputation methods actually improves initially as the MV rate increases, but after an optimum point, performance quickly deteriorates with increasing MV rates.</p>","PeriodicalId":72957,"journal":{"name":"EURASIP journal on bioinformatics & systems biology","volume":"2009 ","pages":"504069"},"PeriodicalIF":0.0000,"publicationDate":"2009-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1155/2009/504069","citationCount":"22","resultStr":"{\"title\":\"Impact of missing value imputation on classification for DNA microarray gene expression data--a model-based study.\",\"authors\":\"Youting Sun, Ulisses Braga-Neto, Edward R Dougherty\",\"doi\":\"10.1155/2009/504069\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Many missing-value (MV) imputation methods have been developed for microarray data, but only a few studies have investigated the relationship between MV imputation and classification accuracy. Furthermore, these studies are problematic in fundamental steps such as MV generation and classifier error estimation. In this work, we carry out a model-based study that addresses some of the issues in previous studies. Six popular imputation algorithms, two feature selection methods, and three classification rules are considered. The results suggest that it is beneficial to apply MV imputation when the noise level is high, variance is small, or gene-cluster correlation is strong, under small to moderate MV rates. In these cases, if data quality metrics are available, then it may be helpful to consider the data point with poor quality as missing and apply one of the most robust imputation algorithms to estimate the true signal based on the available high-quality data points. However, at large MV rates, we conclude that imputation methods are not recommended. Regarding the MV rate, our results indicate the presence of a peaking phenomenon: performance of imputation methods actually improves initially as the MV rate increases, but after an optimum point, performance quickly deteriorates with increasing MV rates.</p>\",\"PeriodicalId\":72957,\"journal\":{\"name\":\"EURASIP journal on bioinformatics & systems biology\",\"volume\":\"2009 \",\"pages\":\"504069\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2009-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1155/2009/504069\",\"citationCount\":\"22\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EURASIP journal on bioinformatics & systems biology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1155/2009/504069\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2010/3/2 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EURASIP journal on bioinformatics & systems biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1155/2009/504069","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2010/3/2 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Impact of missing value imputation on classification for DNA microarray gene expression data--a model-based study.
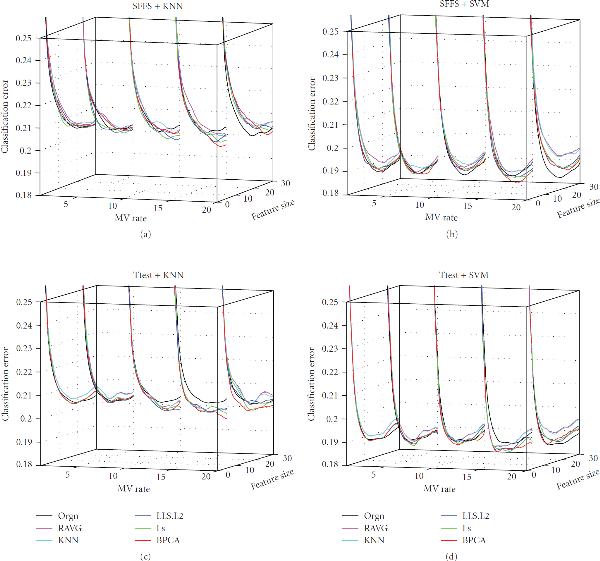
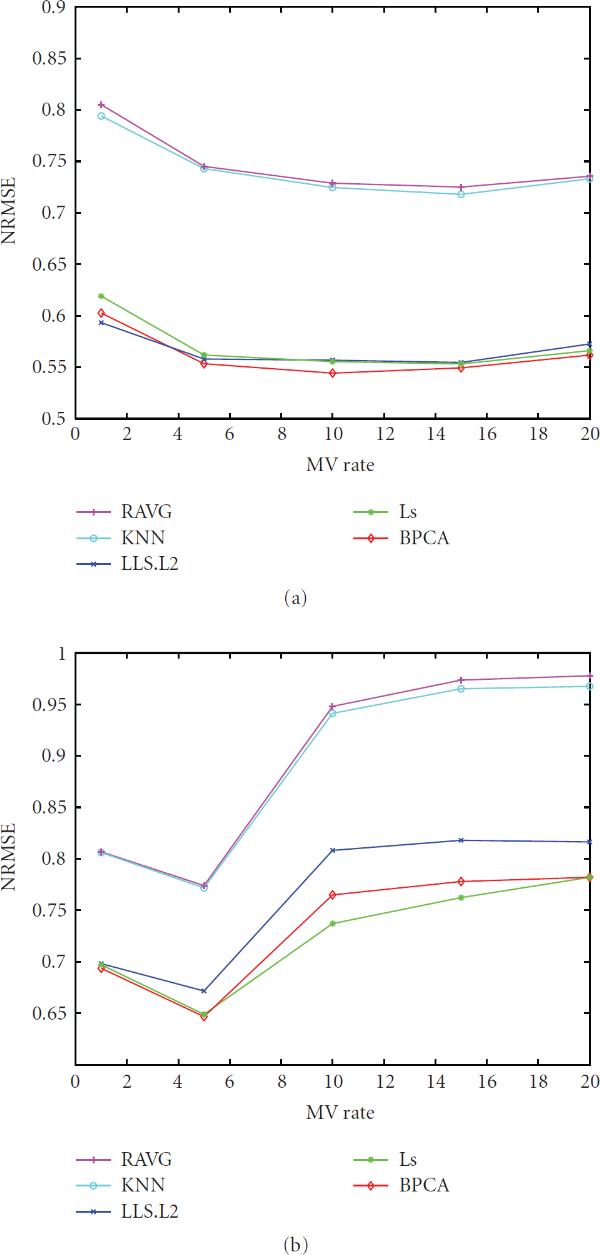
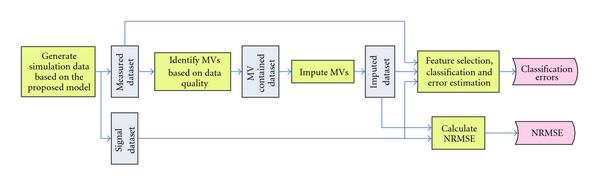
Many missing-value (MV) imputation methods have been developed for microarray data, but only a few studies have investigated the relationship between MV imputation and classification accuracy. Furthermore, these studies are problematic in fundamental steps such as MV generation and classifier error estimation. In this work, we carry out a model-based study that addresses some of the issues in previous studies. Six popular imputation algorithms, two feature selection methods, and three classification rules are considered. The results suggest that it is beneficial to apply MV imputation when the noise level is high, variance is small, or gene-cluster correlation is strong, under small to moderate MV rates. In these cases, if data quality metrics are available, then it may be helpful to consider the data point with poor quality as missing and apply one of the most robust imputation algorithms to estimate the true signal based on the available high-quality data points. However, at large MV rates, we conclude that imputation methods are not recommended. Regarding the MV rate, our results indicate the presence of a peaking phenomenon: performance of imputation methods actually improves initially as the MV rate increases, but after an optimum point, performance quickly deteriorates with increasing MV rates.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
