{"title":"goSTAG:基因本体子树,用于标记和注释一组基因。","authors":"Brian D Bennett, Pierre R Bushel","doi":"10.1186/s13029-017-0066-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Over-representation analysis (ORA) detects enrichment of genes within biological categories. Gene Ontology (GO) domains are commonly used for gene/gene-product annotation. When ORA is employed, often times there are hundreds of statistically significant GO terms per gene set. Comparing enriched categories between a large number of analyses and identifying the term within the GO hierarchy with the most connections is challenging. Furthermore, ascertaining biological themes representative of the samples can be highly subjective from the interpretation of the enriched categories.</p><p><strong>Results: </strong>We developed goSTAG for utilizing GO Subtrees to Tag and Annotate Genes that are part of a set. Given gene lists from microarray, RNA sequencing (RNA-Seq) or other genomic high-throughput technologies, goSTAG performs GO enrichment analysis and clusters the GO terms based on the <i>p</i>-values from the significance tests. GO subtrees are constructed for each cluster, and the term that has the most paths to the root within the subtree is used to tag and annotate the cluster as the biological theme. We tested goSTAG on a microarray gene expression data set of samples acquired from the bone marrow of rats exposed to cancer therapeutic drugs to determine whether the combination or the order of administration influenced bone marrow toxicity at the level of gene expression. Several clusters were labeled with GO biological processes (BPs) from the subtrees that are indicative of some of the prominent pathways modulated in bone marrow from animals treated with an oxaliplatin/topotecan combination. In particular, negative regulation of MAP kinase activity was the biological theme exclusively in the cluster associated with enrichment at 6 h after treatment with oxaliplatin followed by control. However, nucleoside triphosphate catabolic process was the GO BP labeled exclusively at 6 h after treatment with topotecan followed by control.</p><p><strong>Conclusions: </strong>goSTAG converts gene lists from genomic analyses into biological themes by enriching biological categories and constructing GO subtrees from over-represented terms in the clusters. The terms with the most paths to the root in the subtree are used to represent the biological themes. goSTAG is developed in R as a Bioconductor package and is available at https://bioconductor.org/packages/goSTAG.</p>","PeriodicalId":35052,"journal":{"name":"Source Code for Biology and Medicine","volume":"12 ","pages":"6"},"PeriodicalIF":0.0000,"publicationDate":"2017-04-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13029-017-0066-1","citationCount":"7","resultStr":"{\"title\":\"goSTAG: gene ontology subtrees to tag and annotate genes within a set.\",\"authors\":\"Brian D Bennett, Pierre R Bushel\",\"doi\":\"10.1186/s13029-017-0066-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Over-representation analysis (ORA) detects enrichment of genes within biological categories. Gene Ontology (GO) domains are commonly used for gene/gene-product annotation. When ORA is employed, often times there are hundreds of statistically significant GO terms per gene set. Comparing enriched categories between a large number of analyses and identifying the term within the GO hierarchy with the most connections is challenging. Furthermore, ascertaining biological themes representative of the samples can be highly subjective from the interpretation of the enriched categories.</p><p><strong>Results: </strong>We developed goSTAG for utilizing GO Subtrees to Tag and Annotate Genes that are part of a set. Given gene lists from microarray, RNA sequencing (RNA-Seq) or other genomic high-throughput technologies, goSTAG performs GO enrichment analysis and clusters the GO terms based on the <i>p</i>-values from the significance tests. GO subtrees are constructed for each cluster, and the term that has the most paths to the root within the subtree is used to tag and annotate the cluster as the biological theme. We tested goSTAG on a microarray gene expression data set of samples acquired from the bone marrow of rats exposed to cancer therapeutic drugs to determine whether the combination or the order of administration influenced bone marrow toxicity at the level of gene expression. Several clusters were labeled with GO biological processes (BPs) from the subtrees that are indicative of some of the prominent pathways modulated in bone marrow from animals treated with an oxaliplatin/topotecan combination. In particular, negative regulation of MAP kinase activity was the biological theme exclusively in the cluster associated with enrichment at 6 h after treatment with oxaliplatin followed by control. However, nucleoside triphosphate catabolic process was the GO BP labeled exclusively at 6 h after treatment with topotecan followed by control.</p><p><strong>Conclusions: </strong>goSTAG converts gene lists from genomic analyses into biological themes by enriching biological categories and constructing GO subtrees from over-represented terms in the clusters. The terms with the most paths to the root in the subtree are used to represent the biological themes. goSTAG is developed in R as a Bioconductor package and is available at https://bioconductor.org/packages/goSTAG.</p>\",\"PeriodicalId\":35052,\"journal\":{\"name\":\"Source Code for Biology and Medicine\",\"volume\":\"12 \",\"pages\":\"6\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2017-04-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/s13029-017-0066-1\",\"citationCount\":\"7\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Source Code for Biology and Medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s13029-017-0066-1\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2017/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"Decision Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Source Code for Biology and Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s13029-017-0066-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Decision Sciences","Score":null,"Total":0}
goSTAG: gene ontology subtrees to tag and annotate genes within a set.
Background: Over-representation analysis (ORA) detects enrichment of genes within biological categories. Gene Ontology (GO) domains are commonly used for gene/gene-product annotation. When ORA is employed, often times there are hundreds of statistically significant GO terms per gene set. Comparing enriched categories between a large number of analyses and identifying the term within the GO hierarchy with the most connections is challenging. Furthermore, ascertaining biological themes representative of the samples can be highly subjective from the interpretation of the enriched categories.
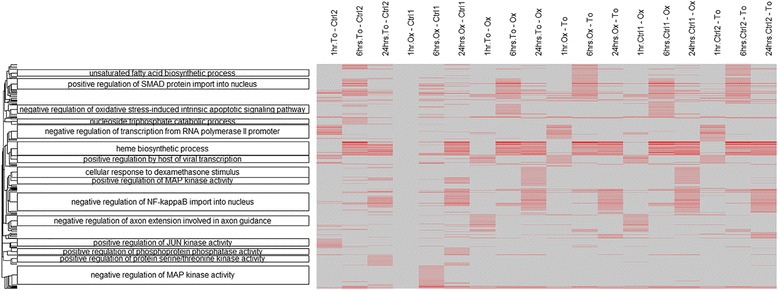
Results: We developed goSTAG for utilizing GO Subtrees to Tag and Annotate Genes that are part of a set. Given gene lists from microarray, RNA sequencing (RNA-Seq) or other genomic high-throughput technologies, goSTAG performs GO enrichment analysis and clusters the GO terms based on the p-values from the significance tests. GO subtrees are constructed for each cluster, and the term that has the most paths to the root within the subtree is used to tag and annotate the cluster as the biological theme. We tested goSTAG on a microarray gene expression data set of samples acquired from the bone marrow of rats exposed to cancer therapeutic drugs to determine whether the combination or the order of administration influenced bone marrow toxicity at the level of gene expression. Several clusters were labeled with GO biological processes (BPs) from the subtrees that are indicative of some of the prominent pathways modulated in bone marrow from animals treated with an oxaliplatin/topotecan combination. In particular, negative regulation of MAP kinase activity was the biological theme exclusively in the cluster associated with enrichment at 6 h after treatment with oxaliplatin followed by control. However, nucleoside triphosphate catabolic process was the GO BP labeled exclusively at 6 h after treatment with topotecan followed by control.
Conclusions: goSTAG converts gene lists from genomic analyses into biological themes by enriching biological categories and constructing GO subtrees from over-represented terms in the clusters. The terms with the most paths to the root in the subtree are used to represent the biological themes. goSTAG is developed in R as a Bioconductor package and is available at https://bioconductor.org/packages/goSTAG.
期刊介绍:
Source Code for Biology and Medicine is a peer-reviewed open access, online journal that publishes articles on source code employed over a wide range of applications in biology and medicine. The journal"s aim is to publish source code for distribution and use in the public domain in order to advance biological and medical research. Through this dissemination, it may be possible to shorten the time required for solving certain computational problems for which there is limited source code availability or resources.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
