Feichen Shen, Hongfang Liu, Sunghwan Sohn, David W Larson, Yugyung Lee
{"title":"面向谓词的生物医学知识发现模式分析。","authors":"Feichen Shen, Hongfang Liu, Sunghwan Sohn, David W Larson, Yugyung Lee","doi":"10.4236/iim.2016.83006","DOIUrl":null,"url":null,"abstract":"In the current biomedical data movement, numerous efforts have been made to convert and normalize a large number of traditional structured and unstructured data (e.g., EHRs, reports) to semi-structured data (e.g., RDF, OWL). With the increasing number of semi-structured data coming into the biomedical community, data integration and knowledge discovery from heterogeneous domains become important research problem. In the application level, detection of related concepts among medical ontologies is an important goal of life science research. It is more crucial to figure out how different concepts are related within a single ontology or across multiple ontologies by analysing predicates in different knowledge bases. However, the world today is one of information explosion, and it is extremely difficult for biomedical researchers to find existing or potential predicates to perform linking among cross domain concepts without any support from schema pattern analysis. Therefore, there is a need for a mechanism to do predicate oriented pattern analysis to partition heterogeneous ontologies into closer small topics and do query generation to discover cross domain knowledge from each topic. In this paper, we present such a model that predicates oriented pattern analysis based on their close relationship and generates a similarity matrix. Based on this similarity matrix, we apply an innovated unsupervised learning algorithm to partition large data sets into smaller and closer topics and generate meaningful queries to fully discover knowledge over a set of interlinked data sources. We have implemented a prototype system named BmQGen and evaluate the proposed model with colorectal surgical cohort from the Mayo Clinic.","PeriodicalId":61442,"journal":{"name":"智能信息管理(英文)","volume":"8 3","pages":"66-85"},"PeriodicalIF":0.0000,"publicationDate":"2016-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5626454/pdf/","citationCount":"16","resultStr":"{\"title\":\"Predicate Oriented Pattern Analysis for Biomedical Knowledge Discovery.\",\"authors\":\"Feichen Shen, Hongfang Liu, Sunghwan Sohn, David W Larson, Yugyung Lee\",\"doi\":\"10.4236/iim.2016.83006\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"In the current biomedical data movement, numerous efforts have been made to convert and normalize a large number of traditional structured and unstructured data (e.g., EHRs, reports) to semi-structured data (e.g., RDF, OWL). With the increasing number of semi-structured data coming into the biomedical community, data integration and knowledge discovery from heterogeneous domains become important research problem. In the application level, detection of related concepts among medical ontologies is an important goal of life science research. It is more crucial to figure out how different concepts are related within a single ontology or across multiple ontologies by analysing predicates in different knowledge bases. However, the world today is one of information explosion, and it is extremely difficult for biomedical researchers to find existing or potential predicates to perform linking among cross domain concepts without any support from schema pattern analysis. Therefore, there is a need for a mechanism to do predicate oriented pattern analysis to partition heterogeneous ontologies into closer small topics and do query generation to discover cross domain knowledge from each topic. In this paper, we present such a model that predicates oriented pattern analysis based on their close relationship and generates a similarity matrix. Based on this similarity matrix, we apply an innovated unsupervised learning algorithm to partition large data sets into smaller and closer topics and generate meaningful queries to fully discover knowledge over a set of interlinked data sources. We have implemented a prototype system named BmQGen and evaluate the proposed model with colorectal surgical cohort from the Mayo Clinic.\",\"PeriodicalId\":61442,\"journal\":{\"name\":\"智能信息管理(英文)\",\"volume\":\"8 3\",\"pages\":\"66-85\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2016-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5626454/pdf/\",\"citationCount\":\"16\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"智能信息管理(英文)\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4236/iim.2016.83006\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"智能信息管理(英文)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4236/iim.2016.83006","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Predicate Oriented Pattern Analysis for Biomedical Knowledge Discovery.
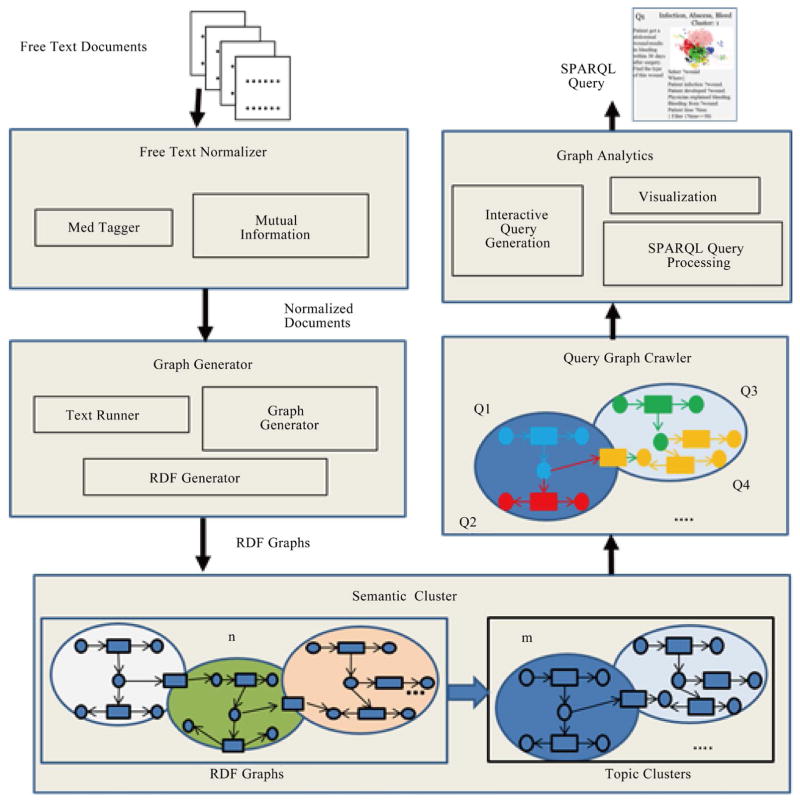
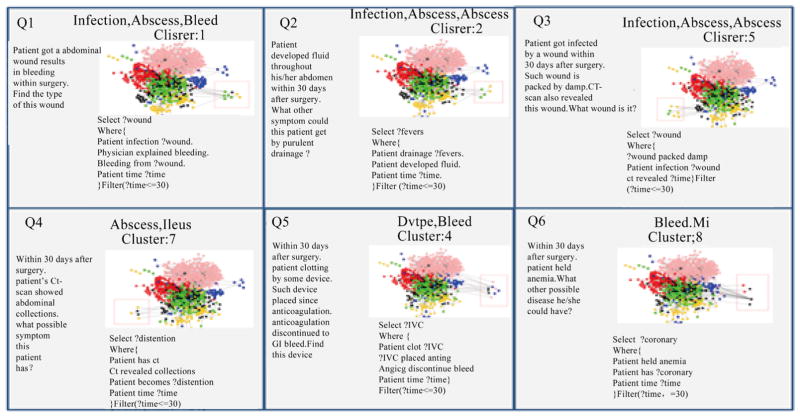
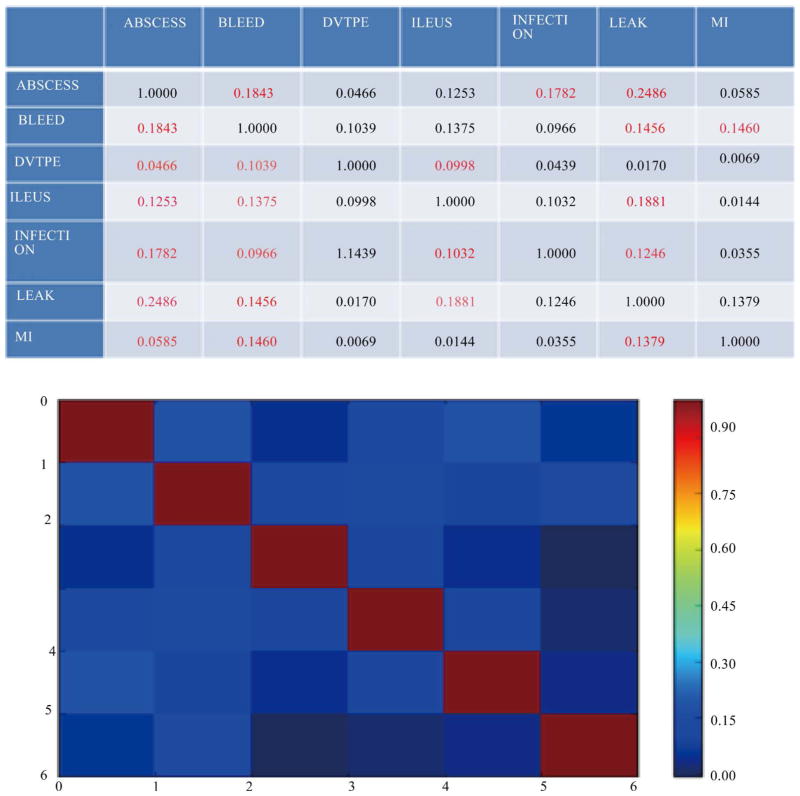
In the current biomedical data movement, numerous efforts have been made to convert and normalize a large number of traditional structured and unstructured data (e.g., EHRs, reports) to semi-structured data (e.g., RDF, OWL). With the increasing number of semi-structured data coming into the biomedical community, data integration and knowledge discovery from heterogeneous domains become important research problem. In the application level, detection of related concepts among medical ontologies is an important goal of life science research. It is more crucial to figure out how different concepts are related within a single ontology or across multiple ontologies by analysing predicates in different knowledge bases. However, the world today is one of information explosion, and it is extremely difficult for biomedical researchers to find existing or potential predicates to perform linking among cross domain concepts without any support from schema pattern analysis. Therefore, there is a need for a mechanism to do predicate oriented pattern analysis to partition heterogeneous ontologies into closer small topics and do query generation to discover cross domain knowledge from each topic. In this paper, we present such a model that predicates oriented pattern analysis based on their close relationship and generates a similarity matrix. Based on this similarity matrix, we apply an innovated unsupervised learning algorithm to partition large data sets into smaller and closer topics and generate meaningful queries to fully discover knowledge over a set of interlinked data sources. We have implemented a prototype system named BmQGen and evaluate the proposed model with colorectal surgical cohort from the Mayo Clinic.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
