Mohit Shah, Ming Tu, Visar Berisha, Chaitali Chakrabarti, Andreas Spanias
{"title":"发音约束学习在语音情感识别中的应用。","authors":"Mohit Shah, Ming Tu, Visar Berisha, Chaitali Chakrabarti, Andreas Spanias","doi":"10.1186/s13636-019-0157-9","DOIUrl":null,"url":null,"abstract":"<p><p>Speech emotion recognition methods combining articulatory information with acoustic features have been previously shown to improve recognition performance. Collection of articulatory data on a large scale may not be feasible in many scenarios, thus restricting the scope and applicability of such methods. In this paper, a discriminative learning method for emotion recognition using both articulatory and acoustic information is proposed. A traditional <i>ℓ</i> <sub>1</sub>-regularized logistic regression cost function is extended to include additional constraints that enforce the model to reconstruct articulatory data. This leads to sparse and interpretable representations jointly optimized for both tasks simultaneously. Furthermore, the model only requires articulatory features during training; only speech features are required for inference on out-of-sample data. Experiments are conducted to evaluate emotion recognition performance over vowels <i>/AA/,/AE/,/IY/,/UW/</i> and complete utterances. Incorporating articulatory information is shown to significantly improve the performance for valence-based classification. Results obtained for within-corpus and cross-corpus categorical emotion recognition indicate that the proposed method is more effective at distinguishing happiness from other emotions.</p>","PeriodicalId":49202,"journal":{"name":"Eurasip Journal on Audio Speech and Music Processing","volume":"2019 ","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2019-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13636-019-0157-9","citationCount":"9","resultStr":"{\"title\":\"Articulation constrained learning with application to speech emotion recognition.\",\"authors\":\"Mohit Shah, Ming Tu, Visar Berisha, Chaitali Chakrabarti, Andreas Spanias\",\"doi\":\"10.1186/s13636-019-0157-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Speech emotion recognition methods combining articulatory information with acoustic features have been previously shown to improve recognition performance. Collection of articulatory data on a large scale may not be feasible in many scenarios, thus restricting the scope and applicability of such methods. In this paper, a discriminative learning method for emotion recognition using both articulatory and acoustic information is proposed. A traditional <i>ℓ</i> <sub>1</sub>-regularized logistic regression cost function is extended to include additional constraints that enforce the model to reconstruct articulatory data. This leads to sparse and interpretable representations jointly optimized for both tasks simultaneously. Furthermore, the model only requires articulatory features during training; only speech features are required for inference on out-of-sample data. Experiments are conducted to evaluate emotion recognition performance over vowels <i>/AA/,/AE/,/IY/,/UW/</i> and complete utterances. Incorporating articulatory information is shown to significantly improve the performance for valence-based classification. Results obtained for within-corpus and cross-corpus categorical emotion recognition indicate that the proposed method is more effective at distinguishing happiness from other emotions.</p>\",\"PeriodicalId\":49202,\"journal\":{\"name\":\"Eurasip Journal on Audio Speech and Music Processing\",\"volume\":\"2019 \",\"pages\":\"\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2019-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/s13636-019-0157-9\",\"citationCount\":\"9\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Eurasip Journal on Audio Speech and Music Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s13636-019-0157-9\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2019/8/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ACOUSTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Audio Speech and Music Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13636-019-0157-9","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2019/8/20 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
Articulation constrained learning with application to speech emotion recognition.
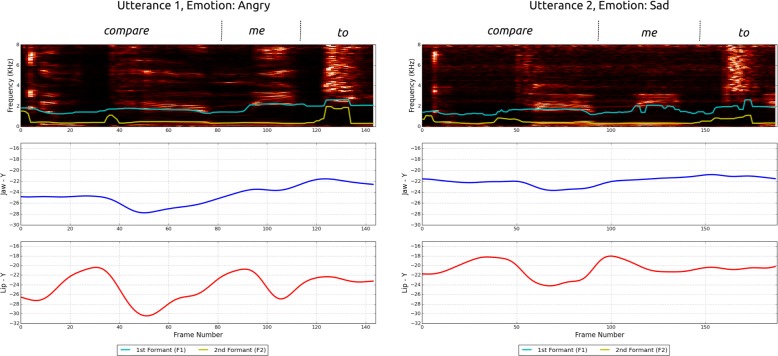
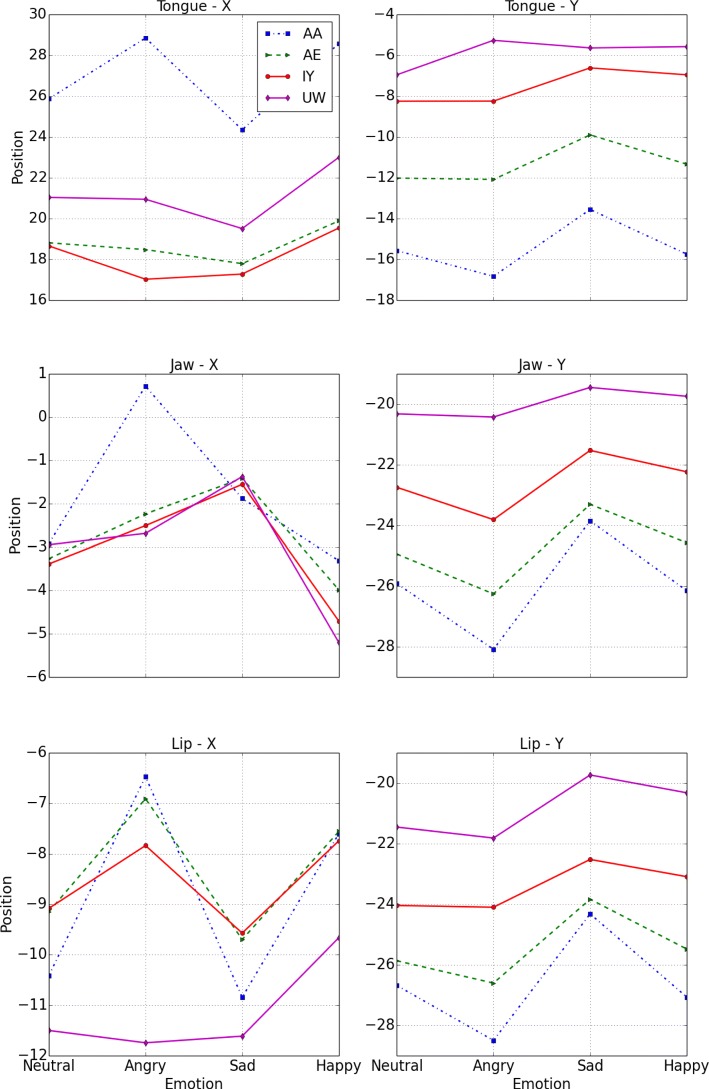
Speech emotion recognition methods combining articulatory information with acoustic features have been previously shown to improve recognition performance. Collection of articulatory data on a large scale may not be feasible in many scenarios, thus restricting the scope and applicability of such methods. In this paper, a discriminative learning method for emotion recognition using both articulatory and acoustic information is proposed. A traditional ℓ1-regularized logistic regression cost function is extended to include additional constraints that enforce the model to reconstruct articulatory data. This leads to sparse and interpretable representations jointly optimized for both tasks simultaneously. Furthermore, the model only requires articulatory features during training; only speech features are required for inference on out-of-sample data. Experiments are conducted to evaluate emotion recognition performance over vowels /AA/,/AE/,/IY/,/UW/ and complete utterances. Incorporating articulatory information is shown to significantly improve the performance for valence-based classification. Results obtained for within-corpus and cross-corpus categorical emotion recognition indicate that the proposed method is more effective at distinguishing happiness from other emotions.
期刊介绍:
The aim of “EURASIP Journal on Audio, Speech, and Music Processing” is to bring together researchers, scientists and engineers working on the theory and applications of the processing of various audio signals, with a specific focus on speech and music. EURASIP Journal on Audio, Speech, and Music Processing will be an interdisciplinary journal for the dissemination of all basic and applied aspects of speech communication and audio processes.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
