{"title":"两个番茄祖先茄(Solanum pinpinellifolium)和茄(Solanum lycopersicum var. cerasiformme)的长读测序从头基因组组装。","authors":"Hitomi Takei, Kenta Shirasawa, Kosuke Kuwabara, Atsushi Toyoda, Yuma Matsuzawa, Shinji Iioka, Tohru Ariizumi","doi":"10.1093/dnares/dsaa029","DOIUrl":null,"url":null,"abstract":"<p><p>The ancestral tomato species are known to possess genes that are valuable for improving traits in breeding. Here, we aimed to construct high-quality de novo genome assemblies of Solanum pimpinellifolium 'LA1670' and S. lycopersicum var. cerasiforme 'LA1673', originating from Peru. The Pacific Biosciences (PacBio) long-read sequences with 110× and 104× coverages were assembled and polished to generate 244 and 202 contigs spanning 808.8 Mbp for 'LA1670' and 804.5 Mbp for 'LA1673', respectively. After chromosome-level scaffolding with reference guiding, 14 scaffold sequences corresponding to 12 tomato chromosomes and 2 unassigned sequences were constructed. High-quality genome assemblies were confirmed using the Benchmarking Universal Single-Copy Orthologs and long terminal repeat assembly index. The protein-coding sequences were then predicted, and their transcriptomes were confirmed. The de novo assembled genomes of S. pimpinellifolium and S. lycopersicum var. cerasiforme were predicted to have 71,945 and 75,230 protein-coding genes, including 29,629 and 29,185 non-redundant genes, respectively, as supported by the transcriptome analysis results. The chromosome-level genome assemblies coupled with transcriptome data sets of the two accessions would be valuable for gaining insights into tomato domestication and understanding genome-scale breeding.</p>","PeriodicalId":51014,"journal":{"name":"DNA Research","volume":"28 1","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2021-01-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1093/dnares/dsaa029","citationCount":"18","resultStr":"{\"title\":\"De novo genome assembly of two tomato ancestors, Solanum pimpinellifolium and Solanum lycopersicum var. cerasiforme, by long-read sequencing.\",\"authors\":\"Hitomi Takei, Kenta Shirasawa, Kosuke Kuwabara, Atsushi Toyoda, Yuma Matsuzawa, Shinji Iioka, Tohru Ariizumi\",\"doi\":\"10.1093/dnares/dsaa029\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The ancestral tomato species are known to possess genes that are valuable for improving traits in breeding. Here, we aimed to construct high-quality de novo genome assemblies of Solanum pimpinellifolium 'LA1670' and S. lycopersicum var. cerasiforme 'LA1673', originating from Peru. The Pacific Biosciences (PacBio) long-read sequences with 110× and 104× coverages were assembled and polished to generate 244 and 202 contigs spanning 808.8 Mbp for 'LA1670' and 804.5 Mbp for 'LA1673', respectively. After chromosome-level scaffolding with reference guiding, 14 scaffold sequences corresponding to 12 tomato chromosomes and 2 unassigned sequences were constructed. High-quality genome assemblies were confirmed using the Benchmarking Universal Single-Copy Orthologs and long terminal repeat assembly index. The protein-coding sequences were then predicted, and their transcriptomes were confirmed. The de novo assembled genomes of S. pimpinellifolium and S. lycopersicum var. cerasiforme were predicted to have 71,945 and 75,230 protein-coding genes, including 29,629 and 29,185 non-redundant genes, respectively, as supported by the transcriptome analysis results. The chromosome-level genome assemblies coupled with transcriptome data sets of the two accessions would be valuable for gaining insights into tomato domestication and understanding genome-scale breeding.</p>\",\"PeriodicalId\":51014,\"journal\":{\"name\":\"DNA Research\",\"volume\":\"28 1\",\"pages\":\"\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2021-01-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1093/dnares/dsaa029\",\"citationCount\":\"18\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"DNA Research\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/dnares/dsaa029\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"GENETICS & HEREDITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"DNA Research","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/dnares/dsaa029","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 18
摘要
已知祖先番茄物种具有在育种中改善性状的有价值的基因。本研究旨在构建源自秘鲁的茄茄(Solanum pimpinellifolium) LA1670和番茄变种(S. lycopersicum var. cerasiformme) LA1673的高质量从头基因组组装。对覆盖110x和104x的PacBio (Pacific Biosciences)长读序列进行组装和优化,得到LA1670和LA1673的长读序列分别为244和202个,长度分别为808.8 Mbp和804.5 Mbp。在参考引导下,构建了12条番茄染色体对应的14条骨架序列和2条未分配序列。使用Benchmarking Universal Single-Copy Orthologs和长末端重复序列组装索引确认高质量的基因组组装。然后预测蛋白质编码序列,并确认其转录组。根据转录组分析结果,新组装的葡萄球菌(S. pimpinellifolium)和葡萄球菌(S. lycopersicum vars . cerasiformme)基因组分别含有71,945个和75,230个蛋白质编码基因,其中非冗余基因分别为29,629个和29,185个。染色体水平的基因组组装与两份材料的转录组数据集相结合,将为深入了解番茄驯化和基因组规模育种提供有价值的信息。
De novo genome assembly of two tomato ancestors, Solanum pimpinellifolium and Solanum lycopersicum var. cerasiforme, by long-read sequencing.
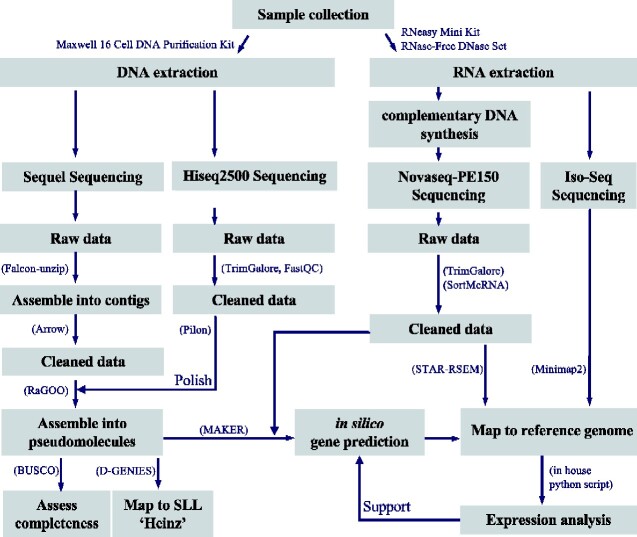
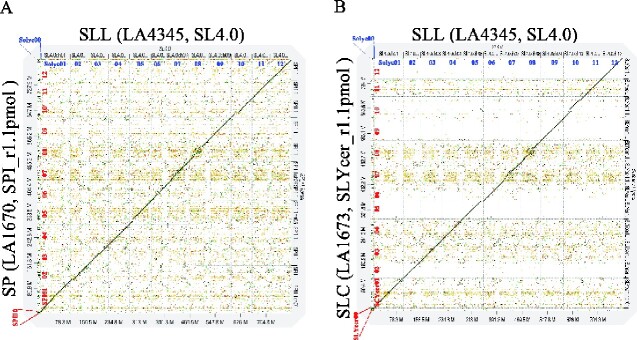
The ancestral tomato species are known to possess genes that are valuable for improving traits in breeding. Here, we aimed to construct high-quality de novo genome assemblies of Solanum pimpinellifolium 'LA1670' and S. lycopersicum var. cerasiforme 'LA1673', originating from Peru. The Pacific Biosciences (PacBio) long-read sequences with 110× and 104× coverages were assembled and polished to generate 244 and 202 contigs spanning 808.8 Mbp for 'LA1670' and 804.5 Mbp for 'LA1673', respectively. After chromosome-level scaffolding with reference guiding, 14 scaffold sequences corresponding to 12 tomato chromosomes and 2 unassigned sequences were constructed. High-quality genome assemblies were confirmed using the Benchmarking Universal Single-Copy Orthologs and long terminal repeat assembly index. The protein-coding sequences were then predicted, and their transcriptomes were confirmed. The de novo assembled genomes of S. pimpinellifolium and S. lycopersicum var. cerasiforme were predicted to have 71,945 and 75,230 protein-coding genes, including 29,629 and 29,185 non-redundant genes, respectively, as supported by the transcriptome analysis results. The chromosome-level genome assemblies coupled with transcriptome data sets of the two accessions would be valuable for gaining insights into tomato domestication and understanding genome-scale breeding.
期刊介绍:
DNA Research is an internationally peer-reviewed journal which aims at publishing papers of highest quality in broad aspects of DNA and genome-related research. Emphasis will be made on the following subjects: 1) Sequencing and characterization of genomes/important genomic regions, 2) Comprehensive analysis of the functions of genes, gene families and genomes, 3) Techniques and equipments useful for structural and functional analysis of genes, gene families and genomes, 4) Computer algorithms and/or their applications relevant to structural and functional analysis of genes and genomes. The journal also welcomes novel findings in other scientific disciplines related to genomes.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
