{"title":"精确计算:COVID-19 rRT-PCR 阳性测试数据集,通过机器学习的文本大数据挖掘进行阶段分类。","authors":"Shalini Ramanathan, Mohan Ramasundaram","doi":"10.1007/s11227-020-03586-3","DOIUrl":null,"url":null,"abstract":"<p><p>In every field of life, advanced technology has become a rapid outcome, particularly in the medical field. The recent epidemic of the coronavirus disease 2019 (COVID-19) has promptly become outbreaks to identify early action from suspected cases at the primary stage over the risk prediction. It is overbearing to progress a control system that will locate the coronavirus. At present, the confirmation of COVID-19 infection by the ideal standard test of reverse transcription-polymerase chain reaction (rRT-PCR) by the extension of RNA viral, although it presents identified from deficiencies of long reversal time to generate results in 2-4 h of corona with a necessity of certified laboratories. In this proposed system, a machine learning (ML) algorithm is used to classify the textual clinical report into four classes by using the textual data mining method. The algorithm of the ensemble ML classifier has performed feature extraction using the advanced techniques of term frequency-inverse document frequency (TF/IDF) which is an effective information retrieval technique from the corona dataset. Humans get infected by coronaviruses in three ways: first, mild respiratory disease which is globally pandemic, and human coronaviruses are caused by HCoV-NL63, HCoV-OC43, HCoV-HKU1, and HCoV-229E; second, the zoonotic Middle East respiratory syndrome coronavirus (MERS-CoV); and finally, higher case casualty rate defined as severe acute respiratory syndrome coronavirus (SARS-CoV). By using the machine learning techniques, the three-way COVID-19 stages are classified by the extraction of the feature using the data retrieval process. The TF/IDF is used to measure and evaluate statistically the text data mining of COVID-19 patient's record list for classification and prediction of the coronavirus. This study established the feasibility of techniques to analyze blood tests and machine learning as an alternative to rRT-PCR for detecting the category of COVID-19-positive patients.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"77 7","pages":"7074-7088"},"PeriodicalIF":2.7000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7781398/pdf/","citationCount":"0","resultStr":"{\"title\":\"Accurate computation: COVID-19 rRT-PCR positive test dataset using stages classification through textual big data mining with machine learning.\",\"authors\":\"Shalini Ramanathan, Mohan Ramasundaram\",\"doi\":\"10.1007/s11227-020-03586-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In every field of life, advanced technology has become a rapid outcome, particularly in the medical field. The recent epidemic of the coronavirus disease 2019 (COVID-19) has promptly become outbreaks to identify early action from suspected cases at the primary stage over the risk prediction. It is overbearing to progress a control system that will locate the coronavirus. At present, the confirmation of COVID-19 infection by the ideal standard test of reverse transcription-polymerase chain reaction (rRT-PCR) by the extension of RNA viral, although it presents identified from deficiencies of long reversal time to generate results in 2-4 h of corona with a necessity of certified laboratories. In this proposed system, a machine learning (ML) algorithm is used to classify the textual clinical report into four classes by using the textual data mining method. The algorithm of the ensemble ML classifier has performed feature extraction using the advanced techniques of term frequency-inverse document frequency (TF/IDF) which is an effective information retrieval technique from the corona dataset. Humans get infected by coronaviruses in three ways: first, mild respiratory disease which is globally pandemic, and human coronaviruses are caused by HCoV-NL63, HCoV-OC43, HCoV-HKU1, and HCoV-229E; second, the zoonotic Middle East respiratory syndrome coronavirus (MERS-CoV); and finally, higher case casualty rate defined as severe acute respiratory syndrome coronavirus (SARS-CoV). By using the machine learning techniques, the three-way COVID-19 stages are classified by the extraction of the feature using the data retrieval process. The TF/IDF is used to measure and evaluate statistically the text data mining of COVID-19 patient's record list for classification and prediction of the coronavirus. This study established the feasibility of techniques to analyze blood tests and machine learning as an alternative to rRT-PCR for detecting the category of COVID-19-positive patients.</p>\",\"PeriodicalId\":50034,\"journal\":{\"name\":\"Journal of Supercomputing\",\"volume\":\"77 7\",\"pages\":\"7074-7088\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2021-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7781398/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Supercomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11227-020-03586-3\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2021/1/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-020-03586-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/1/4 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
Accurate computation: COVID-19 rRT-PCR positive test dataset using stages classification through textual big data mining with machine learning.
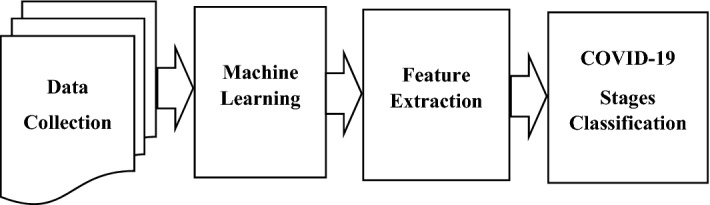
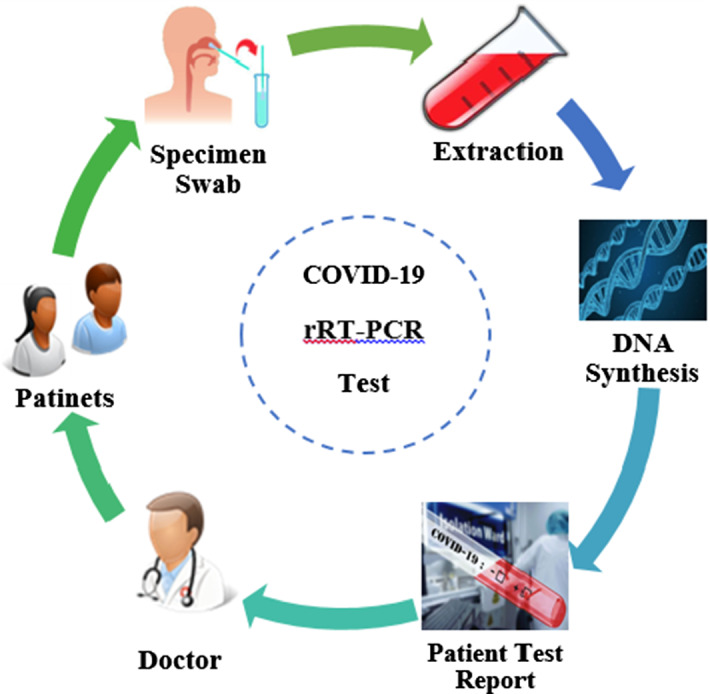
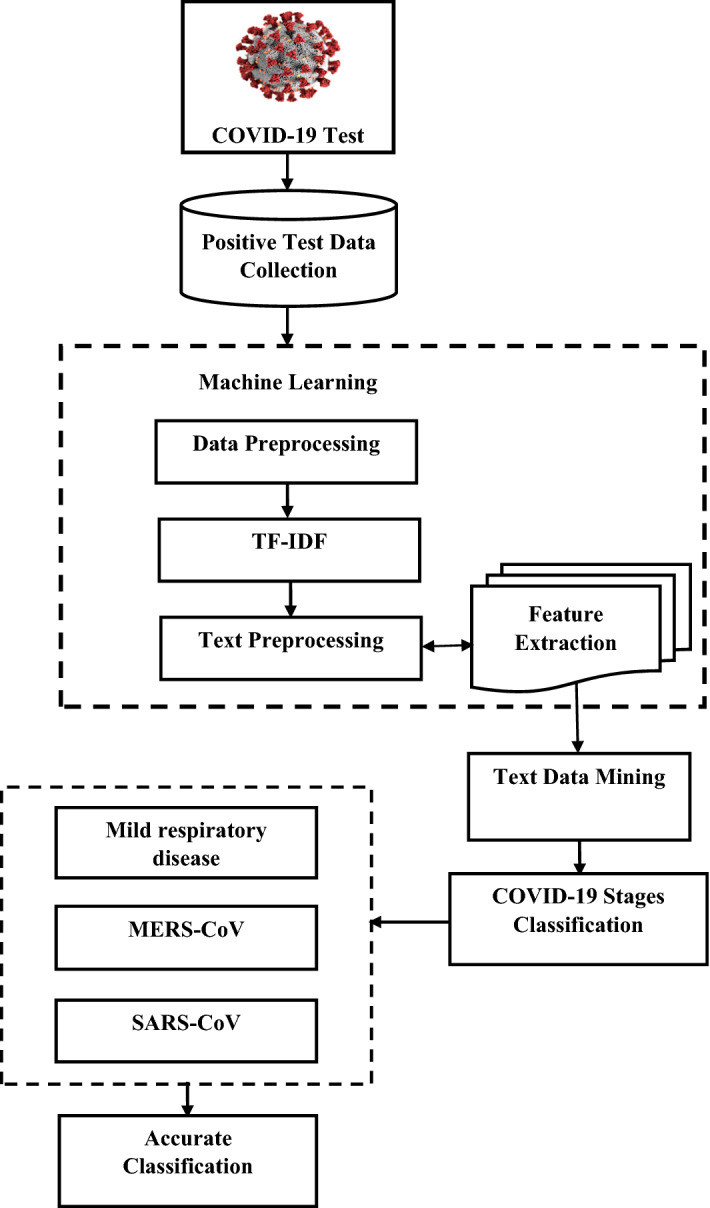
In every field of life, advanced technology has become a rapid outcome, particularly in the medical field. The recent epidemic of the coronavirus disease 2019 (COVID-19) has promptly become outbreaks to identify early action from suspected cases at the primary stage over the risk prediction. It is overbearing to progress a control system that will locate the coronavirus. At present, the confirmation of COVID-19 infection by the ideal standard test of reverse transcription-polymerase chain reaction (rRT-PCR) by the extension of RNA viral, although it presents identified from deficiencies of long reversal time to generate results in 2-4 h of corona with a necessity of certified laboratories. In this proposed system, a machine learning (ML) algorithm is used to classify the textual clinical report into four classes by using the textual data mining method. The algorithm of the ensemble ML classifier has performed feature extraction using the advanced techniques of term frequency-inverse document frequency (TF/IDF) which is an effective information retrieval technique from the corona dataset. Humans get infected by coronaviruses in three ways: first, mild respiratory disease which is globally pandemic, and human coronaviruses are caused by HCoV-NL63, HCoV-OC43, HCoV-HKU1, and HCoV-229E; second, the zoonotic Middle East respiratory syndrome coronavirus (MERS-CoV); and finally, higher case casualty rate defined as severe acute respiratory syndrome coronavirus (SARS-CoV). By using the machine learning techniques, the three-way COVID-19 stages are classified by the extraction of the feature using the data retrieval process. The TF/IDF is used to measure and evaluate statistically the text data mining of COVID-19 patient's record list for classification and prediction of the coronavirus. This study established the feasibility of techniques to analyze blood tests and machine learning as an alternative to rRT-PCR for detecting the category of COVID-19-positive patients.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
