Frank Popham, Elise Whitley, Oarabile Molaodi, Linsay Gray
{"title":"在加强管理数据集方面,对调查数据进行标准的多重代入并不比简单的代入表现得更好:以英国的自评健康为例。","authors":"Frank Popham, Elise Whitley, Oarabile Molaodi, Linsay Gray","doi":"10.1186/s12982-021-00099-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Health surveys provide a rich array of information but on relatively small numbers of individuals and evidence suggests that they are becoming less representative as response levels fall. Routinely collected administrative data offer more extensive population coverage but typically comprise fewer health topics. We explore whether data combination and multiple imputation of health variables from survey data is a simple and robust way of generating these variables in the general population.</p><p><strong>Methods: </strong>We use the UK Integrated Household Survey and the English 2011 population census both of which included self-rated general health. Setting aside the census self-rated health data we multiply imputed self-rated health responses for the census using the survey data and compared these with the actual census results in 576 unique groups defined by age, sex, housing tenure and geographic region.</p><p><strong>Results: </strong>Compared with original census data across the groups, multiply imputed proportions of bad or very bad self-rated health were not a markedly better fit than those simply derived from the survey proportions.</p><p><strong>Conclusion: </strong>While multiple imputation may have the potential to augment population data with information from surveys, further testing and refinement is required.</p>","PeriodicalId":39896,"journal":{"name":"Emerging Themes in Epidemiology","volume":"18 1","pages":"9"},"PeriodicalIF":4.1000,"publicationDate":"2021-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8310590/pdf/","citationCount":"0","resultStr":"{\"title\":\"Standard multiple imputation of survey data didn't perform better than simple substitution in enhancing an administrative dataset: the example of self-rated health in England.\",\"authors\":\"Frank Popham, Elise Whitley, Oarabile Molaodi, Linsay Gray\",\"doi\":\"10.1186/s12982-021-00099-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Health surveys provide a rich array of information but on relatively small numbers of individuals and evidence suggests that they are becoming less representative as response levels fall. Routinely collected administrative data offer more extensive population coverage but typically comprise fewer health topics. We explore whether data combination and multiple imputation of health variables from survey data is a simple and robust way of generating these variables in the general population.</p><p><strong>Methods: </strong>We use the UK Integrated Household Survey and the English 2011 population census both of which included self-rated general health. Setting aside the census self-rated health data we multiply imputed self-rated health responses for the census using the survey data and compared these with the actual census results in 576 unique groups defined by age, sex, housing tenure and geographic region.</p><p><strong>Results: </strong>Compared with original census data across the groups, multiply imputed proportions of bad or very bad self-rated health were not a markedly better fit than those simply derived from the survey proportions.</p><p><strong>Conclusion: </strong>While multiple imputation may have the potential to augment population data with information from surveys, further testing and refinement is required.</p>\",\"PeriodicalId\":39896,\"journal\":{\"name\":\"Emerging Themes in Epidemiology\",\"volume\":\"18 1\",\"pages\":\"9\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2021-07-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8310590/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Emerging Themes in Epidemiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s12982-021-00099-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Emerging Themes in Epidemiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s12982-021-00099-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
Standard multiple imputation of survey data didn't perform better than simple substitution in enhancing an administrative dataset: the example of self-rated health in England.
Background: Health surveys provide a rich array of information but on relatively small numbers of individuals and evidence suggests that they are becoming less representative as response levels fall. Routinely collected administrative data offer more extensive population coverage but typically comprise fewer health topics. We explore whether data combination and multiple imputation of health variables from survey data is a simple and robust way of generating these variables in the general population.
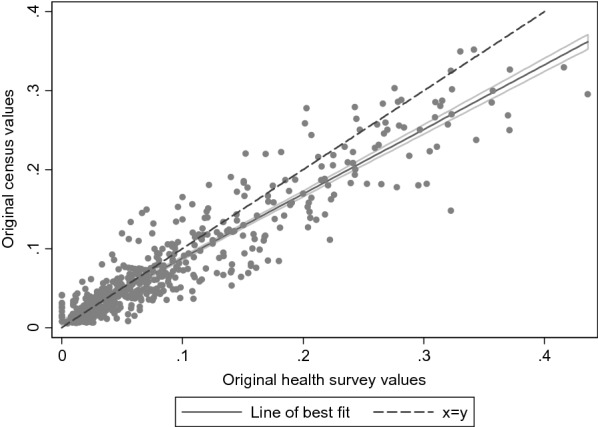
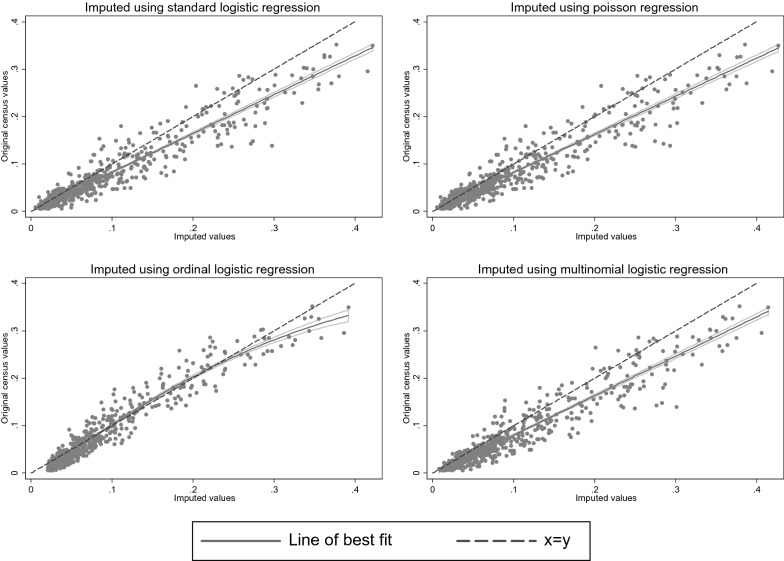
Methods: We use the UK Integrated Household Survey and the English 2011 population census both of which included self-rated general health. Setting aside the census self-rated health data we multiply imputed self-rated health responses for the census using the survey data and compared these with the actual census results in 576 unique groups defined by age, sex, housing tenure and geographic region.
Results: Compared with original census data across the groups, multiply imputed proportions of bad or very bad self-rated health were not a markedly better fit than those simply derived from the survey proportions.
Conclusion: While multiple imputation may have the potential to augment population data with information from surveys, further testing and refinement is required.
期刊介绍:
Emerging Themes in Epidemiology is an open access, peer-reviewed, online journal that aims to promote debate and discussion on practical and theoretical aspects of epidemiology. Combining statistical approaches with an understanding of the biology of disease, epidemiologists seek to elucidate the social, environmental and host factors related to adverse health outcomes. Although research findings from epidemiologic studies abound in traditional public health journals, little publication space is devoted to discussion of the practical and theoretical concepts that underpin them. Because of its immediate impact on public health, an openly accessible forum is needed in the field of epidemiology to foster such discussion.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
