{"title":"一种用于医学图像模式分类的强制块对角低秩表示方法。","authors":"Ishfaq Majeed Sheikh, Manzoor Ahmad Chachoo","doi":"10.1007/s41870-021-00841-5","DOIUrl":null,"url":null,"abstract":"<p><p>Low-rank representation based methods have been used on a variety of medical imaging databases for the segmentation and classification of biomedical images. The subspace segmentation of the data is performed by generating the block diagonal coefficient matrix. Whereas, the data is classified by performing the partitioning of the low-rank representation matrix. There exist several such methods for analysing medical images. The major difference between them lies in the construction of the data dictionary. Most of the time, the input data pattern is used as the dictionary for learning the representation matrix. The direct use of the input data for learning the representation degrades the performance of the model because medical images are subjected to outliers of multiple types, which include environmental lighting, image appearance and varying illumination. These types of errors induce noise in the data. It has been observed that the representation-based model is robust when the training data is clean. If the training data contains corrupted subsamples, the performance of the model drops down. We have addressed the mentioned problem by adopting a class-wise dictionary learning approach. In which the pattern of each class is learnt as the set of tuples in the dictionary. The model has been evaluated on several medical imaging datasets, which includes the Break-his dataset, ALL-IDB, biomedical images, covid CT and chest X-ray. The classification performance of the model is best for the biomedical database (99.16%) followed by the Covid dataset (94%), ALL-IDB database (93.47%) and Break-his dataset (93%).</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":"14 3","pages":"1221-1228"},"PeriodicalIF":0.0000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8769777/pdf/","citationCount":"2","resultStr":"{\"title\":\"An enforced block diagonal low-rank representation method for the classification of medical image patterns.\",\"authors\":\"Ishfaq Majeed Sheikh, Manzoor Ahmad Chachoo\",\"doi\":\"10.1007/s41870-021-00841-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Low-rank representation based methods have been used on a variety of medical imaging databases for the segmentation and classification of biomedical images. The subspace segmentation of the data is performed by generating the block diagonal coefficient matrix. Whereas, the data is classified by performing the partitioning of the low-rank representation matrix. There exist several such methods for analysing medical images. The major difference between them lies in the construction of the data dictionary. Most of the time, the input data pattern is used as the dictionary for learning the representation matrix. The direct use of the input data for learning the representation degrades the performance of the model because medical images are subjected to outliers of multiple types, which include environmental lighting, image appearance and varying illumination. These types of errors induce noise in the data. It has been observed that the representation-based model is robust when the training data is clean. If the training data contains corrupted subsamples, the performance of the model drops down. We have addressed the mentioned problem by adopting a class-wise dictionary learning approach. In which the pattern of each class is learnt as the set of tuples in the dictionary. The model has been evaluated on several medical imaging datasets, which includes the Break-his dataset, ALL-IDB, biomedical images, covid CT and chest X-ray. The classification performance of the model is best for the biomedical database (99.16%) followed by the Covid dataset (94%), ALL-IDB database (93.47%) and Break-his dataset (93%).</p>\",\"PeriodicalId\":73455,\"journal\":{\"name\":\"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management\",\"volume\":\"14 3\",\"pages\":\"1221-1228\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8769777/pdf/\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s41870-021-00841-5\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/1/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-021-00841-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/20 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
An enforced block diagonal low-rank representation method for the classification of medical image patterns.
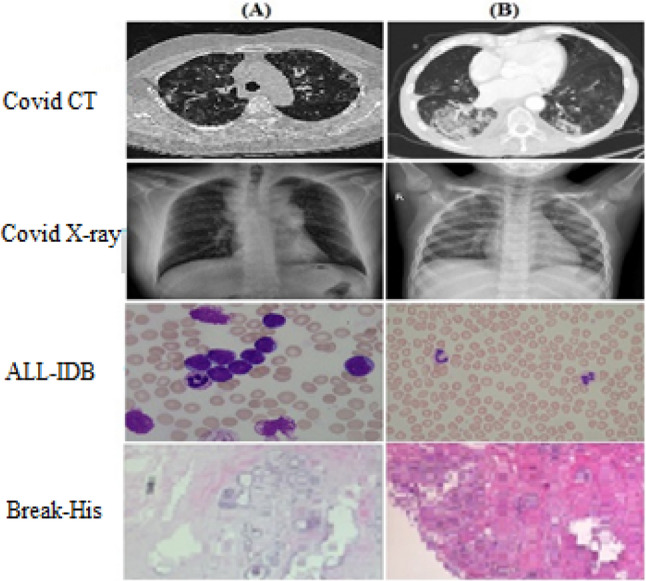
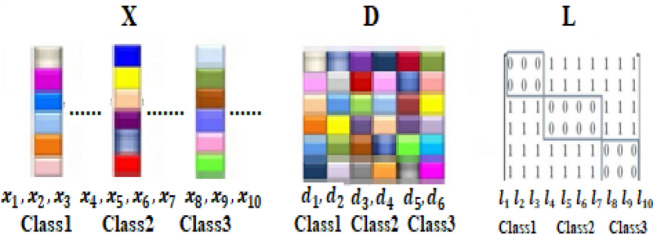
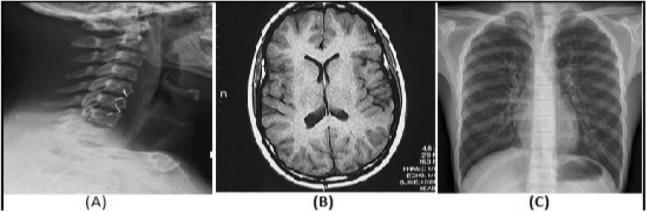
Low-rank representation based methods have been used on a variety of medical imaging databases for the segmentation and classification of biomedical images. The subspace segmentation of the data is performed by generating the block diagonal coefficient matrix. Whereas, the data is classified by performing the partitioning of the low-rank representation matrix. There exist several such methods for analysing medical images. The major difference between them lies in the construction of the data dictionary. Most of the time, the input data pattern is used as the dictionary for learning the representation matrix. The direct use of the input data for learning the representation degrades the performance of the model because medical images are subjected to outliers of multiple types, which include environmental lighting, image appearance and varying illumination. These types of errors induce noise in the data. It has been observed that the representation-based model is robust when the training data is clean. If the training data contains corrupted subsamples, the performance of the model drops down. We have addressed the mentioned problem by adopting a class-wise dictionary learning approach. In which the pattern of each class is learnt as the set of tuples in the dictionary. The model has been evaluated on several medical imaging datasets, which includes the Break-his dataset, ALL-IDB, biomedical images, covid CT and chest X-ray. The classification performance of the model is best for the biomedical database (99.16%) followed by the Covid dataset (94%), ALL-IDB database (93.47%) and Break-his dataset (93%).


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
