Mauro Nascimben, Lia Rimondini, Davide Corà, Manolo Venturin
{"title":"膀胱癌肿瘤分期和生存的多基因风险模型。","authors":"Mauro Nascimben, Lia Rimondini, Davide Corà, Manolo Venturin","doi":"10.1186/s13040-022-00306-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Bladder cancer assessment with non-invasive gene expression signatures facilitates the detection of patients at risk and surveillance of their status, bypassing the discomforts given by cystoscopy. To achieve accurate cancer estimation, analysis pipelines for gene expression data (GED) may integrate a sequence of several machine learning and bio-statistical techniques to model complex characteristics of pathological patterns.</p><p><strong>Methods: </strong>Numerical experiments tested the combination of GED preprocessing by discretization with tree ensemble embeddings and nonlinear dimensionality reductions to categorize oncological patients comprehensively. Modeling aimed to identify tumor stage and distinguish survival outcomes in two situations: complete and partial data embedding. This latter experimental condition simulates the addition of new patients to an existing model for rapid monitoring of disease progression. Machine learning procedures were employed to identify the most relevant genes involved in patient prognosis and test the performance of preprocessed GED compared to untransformed data in predicting patient conditions.</p><p><strong>Results: </strong>Data embedding paired with dimensionality reduction produced prognostic maps with well-defined clusters of patients, suitable for medical decision support. A second experiment simulated the addition of new patients to an existing model (partial data embedding): Uniform Manifold Approximation and Projection (UMAP) methodology with uniform data discretization led to better outcomes than other analyzed pipelines. Further exploration of parameter space for UMAP and t-distributed stochastic neighbor embedding (t-SNE) underlined the importance of tuning a higher number of parameters for UMAP rather than t-SNE. Moreover, two different machine learning experiments identified a group of genes valuable for partitioning patients (gene relevance analysis) and showed the higher precision obtained by preprocessed data in predicting tumor outcomes for cancer stage and survival rate (six classes prediction).</p><p><strong>Conclusions: </strong>The present investigation proposed new analysis pipelines for disease outcome modeling from bladder cancer-related biomarkers. Complete and partial data embedding experiments suggested that pipelines employing UMAP had a more accurate predictive ability, supporting the recent literature trends on this methodology. However, it was also found that several UMAP parameters influence experimental results, therefore deriving a recommendation for researchers to pay attention to this aspect of the UMAP technique. Machine learning procedures further demonstrated the effectiveness of the proposed preprocessing in predicting patients' conditions and determined a sub-group of biomarkers significant for forecasting bladder cancer prognosis.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":" ","pages":"23"},"PeriodicalIF":6.1000,"publicationDate":"2022-09-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9523990/pdf/","citationCount":"6","resultStr":"{\"title\":\"Polygenic risk modeling of tumor stage and survival in bladder cancer.\",\"authors\":\"Mauro Nascimben, Lia Rimondini, Davide Corà, Manolo Venturin\",\"doi\":\"10.1186/s13040-022-00306-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Bladder cancer assessment with non-invasive gene expression signatures facilitates the detection of patients at risk and surveillance of their status, bypassing the discomforts given by cystoscopy. To achieve accurate cancer estimation, analysis pipelines for gene expression data (GED) may integrate a sequence of several machine learning and bio-statistical techniques to model complex characteristics of pathological patterns.</p><p><strong>Methods: </strong>Numerical experiments tested the combination of GED preprocessing by discretization with tree ensemble embeddings and nonlinear dimensionality reductions to categorize oncological patients comprehensively. Modeling aimed to identify tumor stage and distinguish survival outcomes in two situations: complete and partial data embedding. This latter experimental condition simulates the addition of new patients to an existing model for rapid monitoring of disease progression. Machine learning procedures were employed to identify the most relevant genes involved in patient prognosis and test the performance of preprocessed GED compared to untransformed data in predicting patient conditions.</p><p><strong>Results: </strong>Data embedding paired with dimensionality reduction produced prognostic maps with well-defined clusters of patients, suitable for medical decision support. A second experiment simulated the addition of new patients to an existing model (partial data embedding): Uniform Manifold Approximation and Projection (UMAP) methodology with uniform data discretization led to better outcomes than other analyzed pipelines. Further exploration of parameter space for UMAP and t-distributed stochastic neighbor embedding (t-SNE) underlined the importance of tuning a higher number of parameters for UMAP rather than t-SNE. Moreover, two different machine learning experiments identified a group of genes valuable for partitioning patients (gene relevance analysis) and showed the higher precision obtained by preprocessed data in predicting tumor outcomes for cancer stage and survival rate (six classes prediction).</p><p><strong>Conclusions: </strong>The present investigation proposed new analysis pipelines for disease outcome modeling from bladder cancer-related biomarkers. Complete and partial data embedding experiments suggested that pipelines employing UMAP had a more accurate predictive ability, supporting the recent literature trends on this methodology. However, it was also found that several UMAP parameters influence experimental results, therefore deriving a recommendation for researchers to pay attention to this aspect of the UMAP technique. Machine learning procedures further demonstrated the effectiveness of the proposed preprocessing in predicting patients' conditions and determined a sub-group of biomarkers significant for forecasting bladder cancer prognosis.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\" \",\"pages\":\"23\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2022-09-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9523990/pdf/\",\"citationCount\":\"6\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-022-00306-w\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00306-w","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Polygenic risk modeling of tumor stage and survival in bladder cancer.
Introduction: Bladder cancer assessment with non-invasive gene expression signatures facilitates the detection of patients at risk and surveillance of their status, bypassing the discomforts given by cystoscopy. To achieve accurate cancer estimation, analysis pipelines for gene expression data (GED) may integrate a sequence of several machine learning and bio-statistical techniques to model complex characteristics of pathological patterns.
Methods: Numerical experiments tested the combination of GED preprocessing by discretization with tree ensemble embeddings and nonlinear dimensionality reductions to categorize oncological patients comprehensively. Modeling aimed to identify tumor stage and distinguish survival outcomes in two situations: complete and partial data embedding. This latter experimental condition simulates the addition of new patients to an existing model for rapid monitoring of disease progression. Machine learning procedures were employed to identify the most relevant genes involved in patient prognosis and test the performance of preprocessed GED compared to untransformed data in predicting patient conditions.
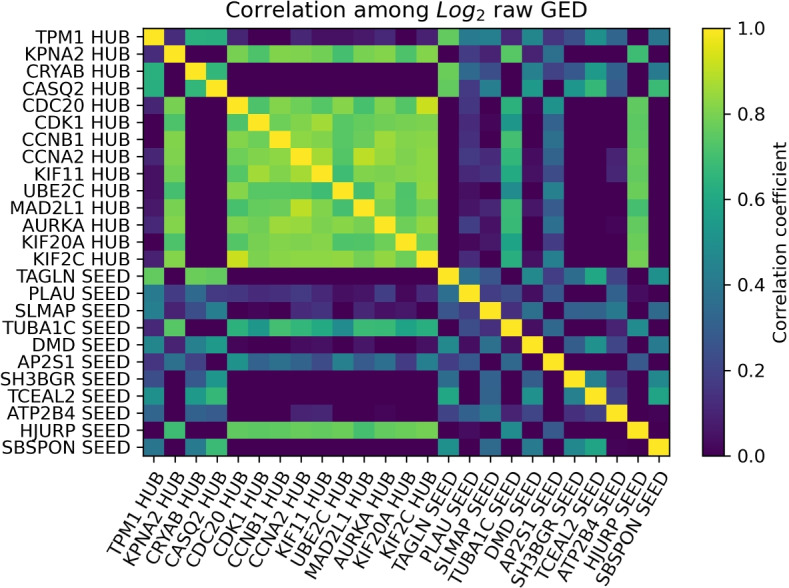
Results: Data embedding paired with dimensionality reduction produced prognostic maps with well-defined clusters of patients, suitable for medical decision support. A second experiment simulated the addition of new patients to an existing model (partial data embedding): Uniform Manifold Approximation and Projection (UMAP) methodology with uniform data discretization led to better outcomes than other analyzed pipelines. Further exploration of parameter space for UMAP and t-distributed stochastic neighbor embedding (t-SNE) underlined the importance of tuning a higher number of parameters for UMAP rather than t-SNE. Moreover, two different machine learning experiments identified a group of genes valuable for partitioning patients (gene relevance analysis) and showed the higher precision obtained by preprocessed data in predicting tumor outcomes for cancer stage and survival rate (six classes prediction).
Conclusions: The present investigation proposed new analysis pipelines for disease outcome modeling from bladder cancer-related biomarkers. Complete and partial data embedding experiments suggested that pipelines employing UMAP had a more accurate predictive ability, supporting the recent literature trends on this methodology. However, it was also found that several UMAP parameters influence experimental results, therefore deriving a recommendation for researchers to pay attention to this aspect of the UMAP technique. Machine learning procedures further demonstrated the effectiveness of the proposed preprocessing in predicting patients' conditions and determined a sub-group of biomarkers significant for forecasting bladder cancer prognosis.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
