David Dora, Timea Dora, Gabor Szegvari, Csongor Gerdán, Zoltan Lohinai
{"title":"EZCancerTarget:一个开放获取的药物再利用和数据收集工具,用于加强靶向验证和优化针对高度进展性癌症的国际研究工作。","authors":"David Dora, Timea Dora, Gabor Szegvari, Csongor Gerdán, Zoltan Lohinai","doi":"10.1186/s13040-022-00307-9","DOIUrl":null,"url":null,"abstract":"<p><p>The expanding body of potential therapeutic targets requires easily accessible, structured, and transparent real-time interpretation of molecular data. Open-access genomic, proteomic and drug-repurposing databases transformed the landscape of cancer research, but most of them are difficult and time-consuming for casual users. Furthermore, to conduct systematic searches and data retrieval on multiple targets, researchers need the help of an expert bioinformatician, who is not always readily available for smaller research teams. We invite research teams to join and aim to enhance the cooperative work of more experienced groups to harmonize international efforts to overcome devastating malignancies. Here, we integrate available fundamental data and present a novel, open access, data-aggregating, drug repurposing platform, deriving our searches from the entries of Clue.io. We show how we integrated our previous expertise in small-cell lung cancer (SCLC) to initiate a new platform to overcome highly progressive cancers such as triple-negative breast and pancreatic cancer with data-aggregating approaches. Through the front end, the current content of the platform can be further expanded or replaced and users can create their drug-target list to select the clinically most relevant targets for further functional validation assays or drug trials. EZCancerTarget integrates searches from publicly available databases, such as PubChem, DrugBank, PubMed, and EMA, citing up-to-date and relevant literature of every target. Moreover, information on compounds is complemented with biological background information on eligible targets using entities like UniProt, String, and GeneCards, presenting relevant pathways, molecular- and biological function and subcellular localizations of these molecules. Cancer drug discovery requires a convergence of complex, often disparate fields. We present a simple, transparent, and user-friendly drug repurposing software to facilitate the efforts of research groups in the field of cancer research.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":" ","pages":"25"},"PeriodicalIF":6.1000,"publicationDate":"2022-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9526900/pdf/","citationCount":"0","resultStr":"{\"title\":\"EZCancerTarget: an open-access drug repurposing and data-collection tool to enhance target validation and optimize international research efforts against highly progressive cancers.\",\"authors\":\"David Dora, Timea Dora, Gabor Szegvari, Csongor Gerdán, Zoltan Lohinai\",\"doi\":\"10.1186/s13040-022-00307-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The expanding body of potential therapeutic targets requires easily accessible, structured, and transparent real-time interpretation of molecular data. Open-access genomic, proteomic and drug-repurposing databases transformed the landscape of cancer research, but most of them are difficult and time-consuming for casual users. Furthermore, to conduct systematic searches and data retrieval on multiple targets, researchers need the help of an expert bioinformatician, who is not always readily available for smaller research teams. We invite research teams to join and aim to enhance the cooperative work of more experienced groups to harmonize international efforts to overcome devastating malignancies. Here, we integrate available fundamental data and present a novel, open access, data-aggregating, drug repurposing platform, deriving our searches from the entries of Clue.io. We show how we integrated our previous expertise in small-cell lung cancer (SCLC) to initiate a new platform to overcome highly progressive cancers such as triple-negative breast and pancreatic cancer with data-aggregating approaches. Through the front end, the current content of the platform can be further expanded or replaced and users can create their drug-target list to select the clinically most relevant targets for further functional validation assays or drug trials. EZCancerTarget integrates searches from publicly available databases, such as PubChem, DrugBank, PubMed, and EMA, citing up-to-date and relevant literature of every target. Moreover, information on compounds is complemented with biological background information on eligible targets using entities like UniProt, String, and GeneCards, presenting relevant pathways, molecular- and biological function and subcellular localizations of these molecules. Cancer drug discovery requires a convergence of complex, often disparate fields. We present a simple, transparent, and user-friendly drug repurposing software to facilitate the efforts of research groups in the field of cancer research.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\" \",\"pages\":\"25\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2022-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9526900/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-022-00307-9\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00307-9","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
EZCancerTarget: an open-access drug repurposing and data-collection tool to enhance target validation and optimize international research efforts against highly progressive cancers.
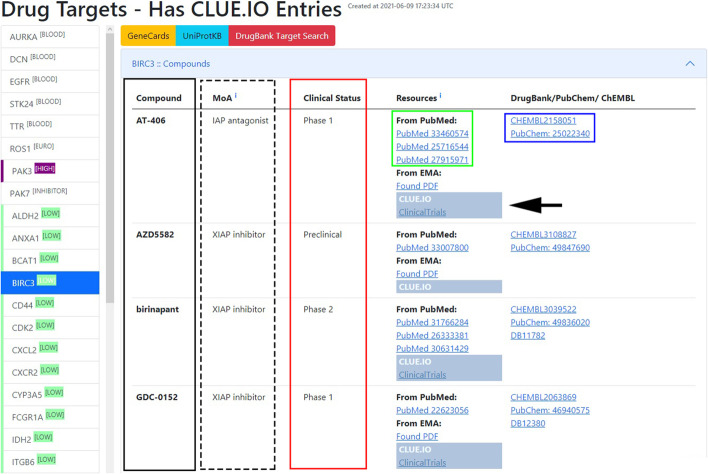
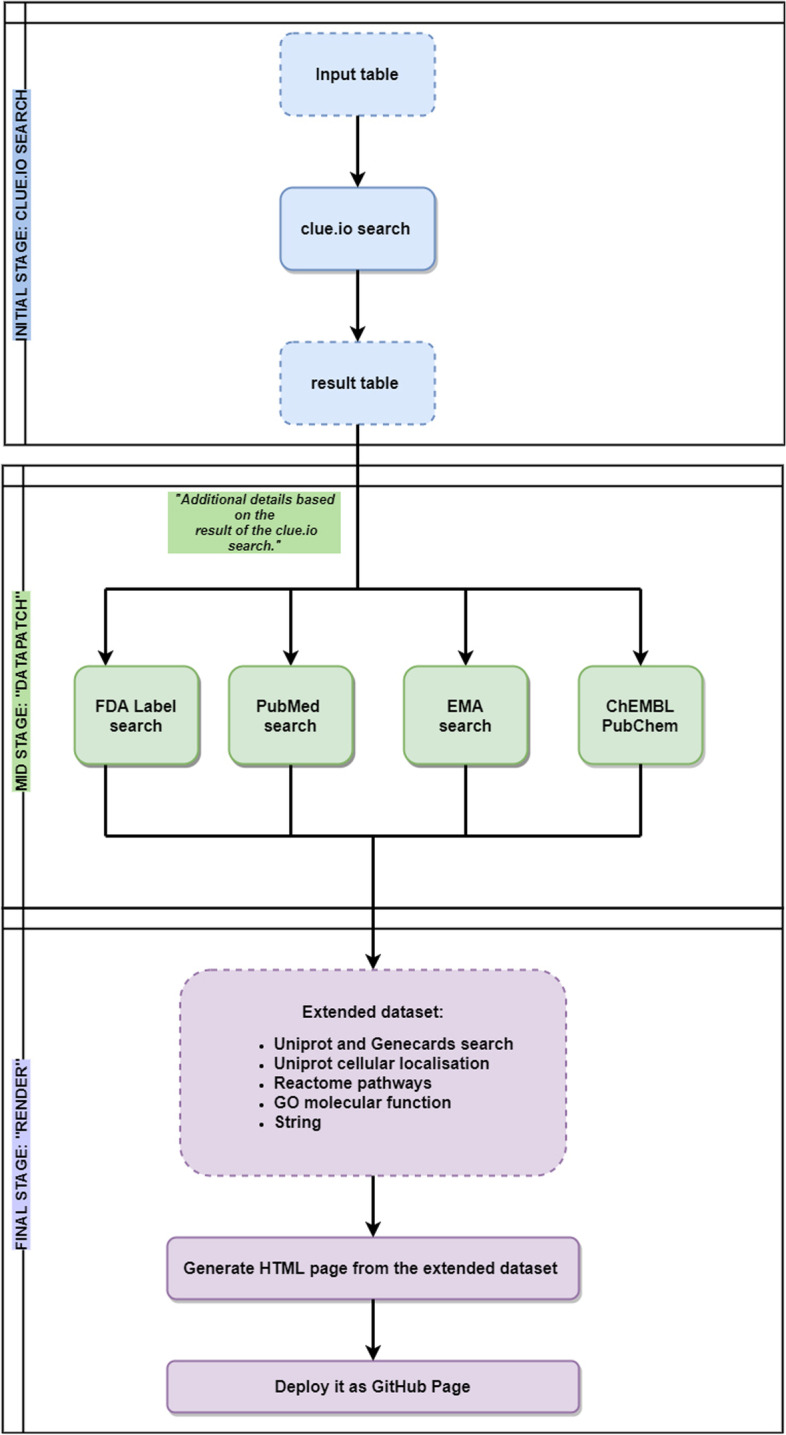
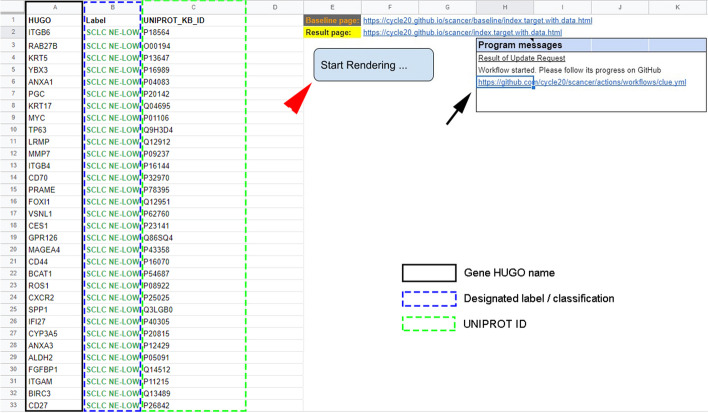
The expanding body of potential therapeutic targets requires easily accessible, structured, and transparent real-time interpretation of molecular data. Open-access genomic, proteomic and drug-repurposing databases transformed the landscape of cancer research, but most of them are difficult and time-consuming for casual users. Furthermore, to conduct systematic searches and data retrieval on multiple targets, researchers need the help of an expert bioinformatician, who is not always readily available for smaller research teams. We invite research teams to join and aim to enhance the cooperative work of more experienced groups to harmonize international efforts to overcome devastating malignancies. Here, we integrate available fundamental data and present a novel, open access, data-aggregating, drug repurposing platform, deriving our searches from the entries of Clue.io. We show how we integrated our previous expertise in small-cell lung cancer (SCLC) to initiate a new platform to overcome highly progressive cancers such as triple-negative breast and pancreatic cancer with data-aggregating approaches. Through the front end, the current content of the platform can be further expanded or replaced and users can create their drug-target list to select the clinically most relevant targets for further functional validation assays or drug trials. EZCancerTarget integrates searches from publicly available databases, such as PubChem, DrugBank, PubMed, and EMA, citing up-to-date and relevant literature of every target. Moreover, information on compounds is complemented with biological background information on eligible targets using entities like UniProt, String, and GeneCards, presenting relevant pathways, molecular- and biological function and subcellular localizations of these molecules. Cancer drug discovery requires a convergence of complex, often disparate fields. We present a simple, transparent, and user-friendly drug repurposing software to facilitate the efforts of research groups in the field of cancer research.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
