{"title":"基于 SLI 和遗传算法的微阵列数据集混合特征选择。","authors":"Sedighe Abasabadi, Hossein Nematzadeh, Homayun Motameni, Ebrahim Akbari","doi":"10.1007/s11227-022-04650-w","DOIUrl":null,"url":null,"abstract":"<p><p>One of the major problems in microarray datasets is the large number of features, which causes the issue of \"the curse of dimensionality\" when machine learning is applied to these datasets. Feature selection refers to the process of finding optimal feature set by removing irrelevant and redundant features. It has a significant role in pattern recognition, classification, and machine learning. In this study, a new and efficient hybrid feature selection method, called Ga<sub>rank&rand</sub>, is presented. The method combines a wrapper feature selection algorithm based on the genetic algorithm (GA) with a proposed filter feature selection method, SLI-<i>γ</i>. In Ga<sub>rank&rand</sub>, some initial solutions are built regarding the most relevant features based on SLI-<i>γ</i>, and the remaining ones are only the random features. Eleven high-dimensional and standard datasets were used for the accuracy evaluation of the proposed SLI-<i>γ</i>. Additionally, four high-dimensional well-known datasets of microarray experiments were used to carry out an extensive experimental study for the performance evaluation of Ga<sub>rank&rand</sub>. This experimental analysis showed the robustness of the method as well as its ability to obtain highly accurate solutions at the earlier stages of the GA evolutionary process. Finally, the performance of Ga<sub>rank&rand</sub> was also compared to the results of GA to highlight its competitiveness and its ability to successfully reduce the original feature set size and execution time.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"78 18","pages":"19725-19753"},"PeriodicalIF":2.7000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9244444/pdf/","citationCount":"0","resultStr":"{\"title\":\"Hybrid feature selection based on SLI and genetic algorithm for microarray datasets.\",\"authors\":\"Sedighe Abasabadi, Hossein Nematzadeh, Homayun Motameni, Ebrahim Akbari\",\"doi\":\"10.1007/s11227-022-04650-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>One of the major problems in microarray datasets is the large number of features, which causes the issue of \\\"the curse of dimensionality\\\" when machine learning is applied to these datasets. Feature selection refers to the process of finding optimal feature set by removing irrelevant and redundant features. It has a significant role in pattern recognition, classification, and machine learning. In this study, a new and efficient hybrid feature selection method, called Ga<sub>rank&rand</sub>, is presented. The method combines a wrapper feature selection algorithm based on the genetic algorithm (GA) with a proposed filter feature selection method, SLI-<i>γ</i>. In Ga<sub>rank&rand</sub>, some initial solutions are built regarding the most relevant features based on SLI-<i>γ</i>, and the remaining ones are only the random features. Eleven high-dimensional and standard datasets were used for the accuracy evaluation of the proposed SLI-<i>γ</i>. Additionally, four high-dimensional well-known datasets of microarray experiments were used to carry out an extensive experimental study for the performance evaluation of Ga<sub>rank&rand</sub>. This experimental analysis showed the robustness of the method as well as its ability to obtain highly accurate solutions at the earlier stages of the GA evolutionary process. Finally, the performance of Ga<sub>rank&rand</sub> was also compared to the results of GA to highlight its competitiveness and its ability to successfully reduce the original feature set size and execution time.</p>\",\"PeriodicalId\":50034,\"journal\":{\"name\":\"Journal of Supercomputing\",\"volume\":\"78 18\",\"pages\":\"19725-19753\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9244444/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Supercomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11227-022-04650-w\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/6/30 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-022-04650-w","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/6/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 0
摘要
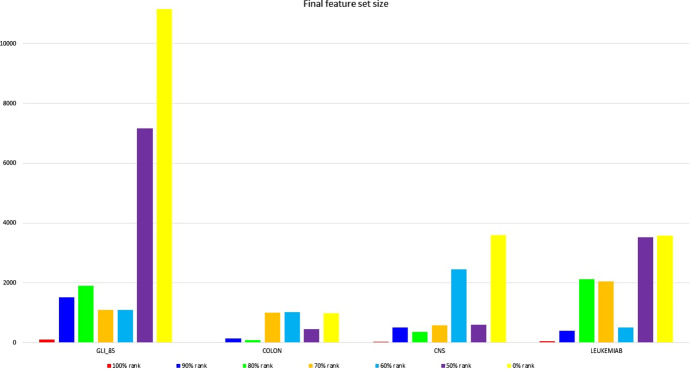
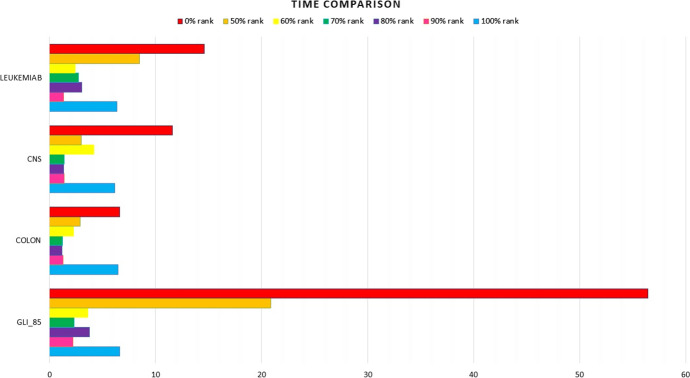
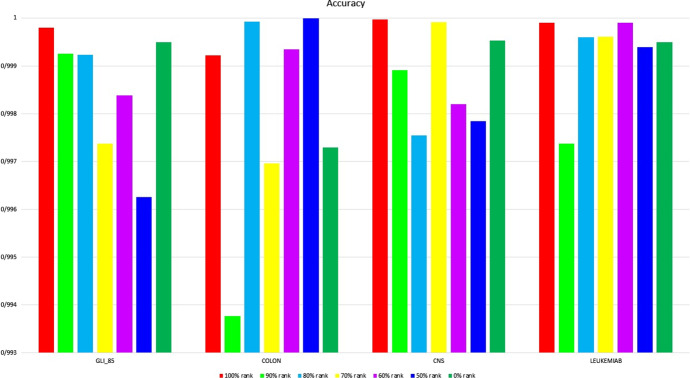
微阵列数据集的主要问题之一是特征数量庞大,这导致机器学习应用于这些数据集时出现 "维度诅咒 "问题。特征选择是指通过去除无关特征和冗余特征来找到最佳特征集的过程。它在模式识别、分类和机器学习中发挥着重要作用。本研究提出了一种名为 Garank&rand 的新型高效混合特征选择方法。该方法结合了基于遗传算法(GA)的包装特征选择算法和建议的过滤特征选择方法 SLI-γ。在 Garank&rand 中,根据 SLI-γ 建立了一些与最相关特征有关的初始解,其余的只是随机特征。11 个高维标准数据集用于评估 SLI-γ 的准确性。此外,还使用了四个著名的高维微阵列实验数据集,对 Garank&rand 的性能评估进行了广泛的实验研究。实验分析表明了该方法的鲁棒性以及在 GA 进化过程的早期阶段获得高精度解的能力。最后,Garank&rand 的性能还与 GA 的结果进行了比较,以突出其竞争力及其成功减少原始特征集大小和执行时间的能力。
Hybrid feature selection based on SLI and genetic algorithm for microarray datasets.
One of the major problems in microarray datasets is the large number of features, which causes the issue of "the curse of dimensionality" when machine learning is applied to these datasets. Feature selection refers to the process of finding optimal feature set by removing irrelevant and redundant features. It has a significant role in pattern recognition, classification, and machine learning. In this study, a new and efficient hybrid feature selection method, called Garank&rand, is presented. The method combines a wrapper feature selection algorithm based on the genetic algorithm (GA) with a proposed filter feature selection method, SLI-γ. In Garank&rand, some initial solutions are built regarding the most relevant features based on SLI-γ, and the remaining ones are only the random features. Eleven high-dimensional and standard datasets were used for the accuracy evaluation of the proposed SLI-γ. Additionally, four high-dimensional well-known datasets of microarray experiments were used to carry out an extensive experimental study for the performance evaluation of Garank&rand. This experimental analysis showed the robustness of the method as well as its ability to obtain highly accurate solutions at the earlier stages of the GA evolutionary process. Finally, the performance of Garank&rand was also compared to the results of GA to highlight its competitiveness and its ability to successfully reduce the original feature set size and execution time.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
