{"title":"综合统计和机器学习分析为区分早发性2型糖尿病的关键影响症状提供了见解","authors":"David A. Wood","doi":"10.1002/cdt3.39","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Background</h3>\n \n <p>Being able to predict with confidence the early onset of type 2 diabetes from a suite of signs and symptoms (features) displayed by potential sufferers is desirable to commence treatment promptly. Late or inconclusive diagnosis can result in more serious health consequences for sufferers and higher costs for health care services in the long run.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>A novel integrated methodology is proposed involving correlation, statistical analysis, machine learning, multi-<i>K</i>-fold cross-validation, and confusion matrices to provide a reliable classification of diabetes-positive and -negative individuals from a substantial suite of features. The method also identifies the relative influence of each feature on the diabetes diagnosis and highlights the most important ones. Ten statistical and machine learning methods are utilized to conduct the analysis.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>A published data set involving 520 individuals (Sylthet Diabetes Hospital, Bangladesh) is modeled revealing that a support vector classifier generates the most accurate early-onset type 2 diabetes status predictions with just 11 misclassifications (2.1% error). Polydipsia and polyuria are among the most influential features, whereas obesity and age are assigned low weights by the prediction models.</p>\n </section>\n \n <section>\n \n <h3> Conclusion</h3>\n \n <p>The proposed methodology can rapidly predict early-onset type 2 diabetes with high confidence while providing valuable insight into the key influential features involved in such predictions.</p>\n </section>\n </div>","PeriodicalId":32096,"journal":{"name":"Chronic Diseases and Translational Medicine","volume":"8 4","pages":"281-295"},"PeriodicalIF":0.0000,"publicationDate":"2022-07-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/c5/62/CDT3-8-281.PMC9676132.pdf","citationCount":"0","resultStr":"{\"title\":\"Integrated statistical and machine learning analysis provides insight into key influencing symptoms for distinguishing early-onset type 2 diabetes\",\"authors\":\"David A. Wood\",\"doi\":\"10.1002/cdt3.39\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Background</h3>\\n \\n <p>Being able to predict with confidence the early onset of type 2 diabetes from a suite of signs and symptoms (features) displayed by potential sufferers is desirable to commence treatment promptly. Late or inconclusive diagnosis can result in more serious health consequences for sufferers and higher costs for health care services in the long run.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>A novel integrated methodology is proposed involving correlation, statistical analysis, machine learning, multi-<i>K</i>-fold cross-validation, and confusion matrices to provide a reliable classification of diabetes-positive and -negative individuals from a substantial suite of features. The method also identifies the relative influence of each feature on the diabetes diagnosis and highlights the most important ones. Ten statistical and machine learning methods are utilized to conduct the analysis.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>A published data set involving 520 individuals (Sylthet Diabetes Hospital, Bangladesh) is modeled revealing that a support vector classifier generates the most accurate early-onset type 2 diabetes status predictions with just 11 misclassifications (2.1% error). Polydipsia and polyuria are among the most influential features, whereas obesity and age are assigned low weights by the prediction models.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusion</h3>\\n \\n <p>The proposed methodology can rapidly predict early-onset type 2 diabetes with high confidence while providing valuable insight into the key influential features involved in such predictions.</p>\\n </section>\\n </div>\",\"PeriodicalId\":32096,\"journal\":{\"name\":\"Chronic Diseases and Translational Medicine\",\"volume\":\"8 4\",\"pages\":\"281-295\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-07-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/c5/62/CDT3-8-281.PMC9676132.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Chronic Diseases and Translational Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/cdt3.39\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Chronic Diseases and Translational Medicine","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cdt3.39","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Medicine","Score":null,"Total":0}
Integrated statistical and machine learning analysis provides insight into key influencing symptoms for distinguishing early-onset type 2 diabetes
Background
Being able to predict with confidence the early onset of type 2 diabetes from a suite of signs and symptoms (features) displayed by potential sufferers is desirable to commence treatment promptly. Late or inconclusive diagnosis can result in more serious health consequences for sufferers and higher costs for health care services in the long run.
Methods
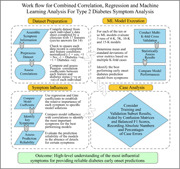
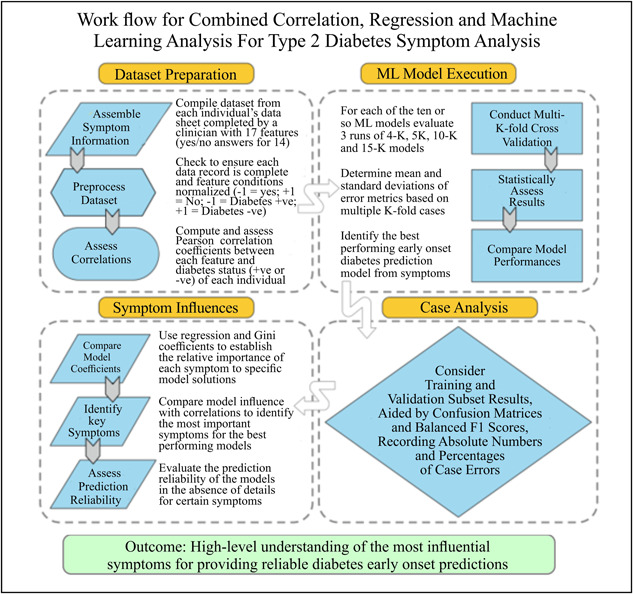
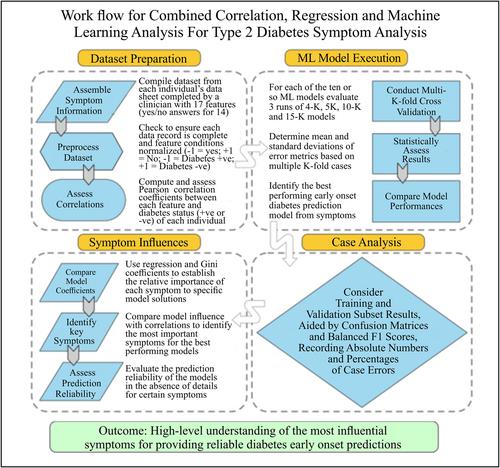
A novel integrated methodology is proposed involving correlation, statistical analysis, machine learning, multi-K-fold cross-validation, and confusion matrices to provide a reliable classification of diabetes-positive and -negative individuals from a substantial suite of features. The method also identifies the relative influence of each feature on the diabetes diagnosis and highlights the most important ones. Ten statistical and machine learning methods are utilized to conduct the analysis.
Results
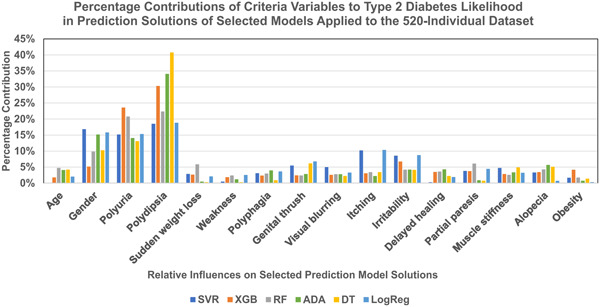
A published data set involving 520 individuals (Sylthet Diabetes Hospital, Bangladesh) is modeled revealing that a support vector classifier generates the most accurate early-onset type 2 diabetes status predictions with just 11 misclassifications (2.1% error). Polydipsia and polyuria are among the most influential features, whereas obesity and age are assigned low weights by the prediction models.
Conclusion
The proposed methodology can rapidly predict early-onset type 2 diabetes with high confidence while providing valuable insight into the key influential features involved in such predictions.
期刊介绍:
This journal aims to promote progress from basic research to clinical practice and to provide a forum for communication among basic, translational, and clinical research practitioners and physicians from all relevant disciplines. Chronic diseases such as cardiovascular diseases, cancer, diabetes, stroke, chronic respiratory diseases (such as asthma and COPD), chronic kidney diseases, and related translational research. Topics of interest for Chronic Diseases and Translational Medicine include Research and commentary on models of chronic diseases with significant implications for disease diagnosis and treatment Investigative studies of human biology with an emphasis on disease Perspectives and reviews on research topics that discuss the implications of findings from the viewpoints of basic science and clinical practic.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
