{"title":"ScienceQA:一个新颖的学术文章问答资源。","authors":"Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, Pushpak Bhattacharyya","doi":"10.1007/s00799-022-00329-y","DOIUrl":null,"url":null,"abstract":"<p><p>Machine Reading Comprehension (MRC) of a document is a challenging problem that requires discourse-level understanding. Information extraction from scholarly articles nowadays is a critical use case for researchers to understand the underlying research quickly and move forward, especially in this age of infodemic. MRC on research articles can also provide helpful information to the reviewers and editors. However, the main bottleneck in building such models is the availability of human-annotated data. In this paper, firstly, we introduce a dataset to facilitate question answering (QA) on scientific articles. We prepare the dataset in a semi-automated fashion having more than 100k human-annotated context-question-answer triples. Secondly, we implement one baseline QA model based on Bidirectional Encoder Representations from Transformers (BERT). Additionally, we implement two models: the first one is based on Science BERT (SciBERT), and the second is the combination of SciBERT and Bi-Directional Attention Flow (Bi-DAF). The best model (i.e., SciBERT) obtains an F1 score of 75.46%. Our dataset is novel, and our work opens up a new avenue for scholarly document processing research by providing a benchmark QA dataset and standard baseline. We make our dataset and codes available here at https://github.com/TanikSaikh/Scientific-Question-Answering.</p>","PeriodicalId":44974,"journal":{"name":"International Journal on Digital Libraries","volume":" ","pages":"289-301"},"PeriodicalIF":1.7000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9297303/pdf/","citationCount":"10","resultStr":"{\"title\":\"<i>ScienceQA</i>: a novel resource for question answering on scholarly articles.\",\"authors\":\"Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, Pushpak Bhattacharyya\",\"doi\":\"10.1007/s00799-022-00329-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Machine Reading Comprehension (MRC) of a document is a challenging problem that requires discourse-level understanding. Information extraction from scholarly articles nowadays is a critical use case for researchers to understand the underlying research quickly and move forward, especially in this age of infodemic. MRC on research articles can also provide helpful information to the reviewers and editors. However, the main bottleneck in building such models is the availability of human-annotated data. In this paper, firstly, we introduce a dataset to facilitate question answering (QA) on scientific articles. We prepare the dataset in a semi-automated fashion having more than 100k human-annotated context-question-answer triples. Secondly, we implement one baseline QA model based on Bidirectional Encoder Representations from Transformers (BERT). Additionally, we implement two models: the first one is based on Science BERT (SciBERT), and the second is the combination of SciBERT and Bi-Directional Attention Flow (Bi-DAF). The best model (i.e., SciBERT) obtains an F1 score of 75.46%. Our dataset is novel, and our work opens up a new avenue for scholarly document processing research by providing a benchmark QA dataset and standard baseline. We make our dataset and codes available here at https://github.com/TanikSaikh/Scientific-Question-Answering.</p>\",\"PeriodicalId\":44974,\"journal\":{\"name\":\"International Journal on Digital Libraries\",\"volume\":\" \",\"pages\":\"289-301\"},\"PeriodicalIF\":1.7000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9297303/pdf/\",\"citationCount\":\"10\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal on Digital Libraries\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s00799-022-00329-y\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/7/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"INFORMATION SCIENCE & LIBRARY SCIENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal on Digital Libraries","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00799-022-00329-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/7/20 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"INFORMATION SCIENCE & LIBRARY SCIENCE","Score":null,"Total":0}
ScienceQA: a novel resource for question answering on scholarly articles.
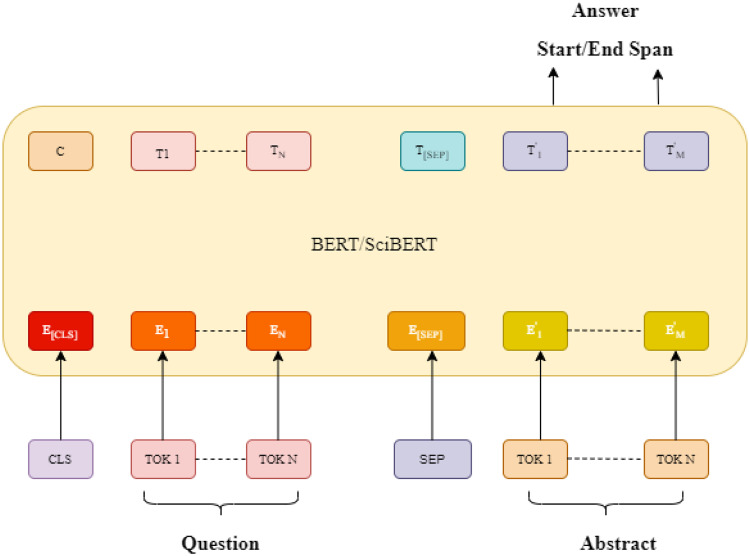
Machine Reading Comprehension (MRC) of a document is a challenging problem that requires discourse-level understanding. Information extraction from scholarly articles nowadays is a critical use case for researchers to understand the underlying research quickly and move forward, especially in this age of infodemic. MRC on research articles can also provide helpful information to the reviewers and editors. However, the main bottleneck in building such models is the availability of human-annotated data. In this paper, firstly, we introduce a dataset to facilitate question answering (QA) on scientific articles. We prepare the dataset in a semi-automated fashion having more than 100k human-annotated context-question-answer triples. Secondly, we implement one baseline QA model based on Bidirectional Encoder Representations from Transformers (BERT). Additionally, we implement two models: the first one is based on Science BERT (SciBERT), and the second is the combination of SciBERT and Bi-Directional Attention Flow (Bi-DAF). The best model (i.e., SciBERT) obtains an F1 score of 75.46%. Our dataset is novel, and our work opens up a new avenue for scholarly document processing research by providing a benchmark QA dataset and standard baseline. We make our dataset and codes available here at https://github.com/TanikSaikh/Scientific-Question-Answering.
期刊介绍:
The International Journal on Digital Libraries (IJDL) examines the theory and practice of acquisition definition organization management preservation and dissemination of digital information via global networking. It covers all aspects of digital libraries (DLs) from large-scale heterogeneous data and information management & access to linking and connectivity to security privacy and policies to its application use and evaluation.The scope of IJDL includes but is not limited to: The FAIR principle and the digital libraries infrastructure Findable: Information access and retrieval; semantic search; data and information exploration; information navigation; smart indexing and searching; resource discovery Accessible: visualization and digital collections; user interfaces; interfaces for handicapped users; HCI and UX in DLs; Security and privacy in DLs; multimodal access Interoperable: metadata (definition management curation integration); syntactic and semantic interoperability; linked data Reusable: reproducibility; Open Science; sustainability profitability repeatability of research results; confidentiality and privacy issues in DLs Digital Library Architectures including heterogeneous and dynamic data management; data and repositories Acquisition of digital information: authoring environments for digital objects; digitization of traditional content Digital Archiving and Preservation Digital Preservation and curation Digital archiving Web Archiving Archiving and preservation Strategies AI for Digital Libraries Machine Learning for DLs Data Mining in DLs NLP for DLs Applications of Digital Libraries Digital Humanities Open Data and their reuse Scholarly DLs (incl. bibliometrics altmetrics) Epigraphy and Paleography Digital Museums Future trends in Digital Libraries Definition of DLs in a ubiquitous digital library world Datafication of digital collections Interaction and user experience (UX) in DLs Information visualization Collection understanding Privacy and security Multimodal user interfaces Accessibility (or "Access for users with disabilities") UX studies




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
