Roland Albert A Romero, Mariefel Nicole Y Deypalan, Suchit Mehrotra, John Titus Jungao, Natalie E Sheils, Elisabetta Manduchi, Jason H Moore
{"title":"使用医疗索赔进行疾病预测的AutoML框架的基准测试。","authors":"Roland Albert A Romero, Mariefel Nicole Y Deypalan, Suchit Mehrotra, John Titus Jungao, Natalie E Sheils, Elisabetta Manduchi, Jason H Moore","doi":"10.1186/s13040-022-00300-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Ascertain and compare the performances of Automated Machine Learning (AutoML) tools on large, highly imbalanced healthcare datasets.</p><p><strong>Materials and methods: </strong>We generated a large dataset using historical de-identified administrative claims including demographic information and flags for disease codes in four different time windows prior to 2019. We then trained three AutoML tools on this dataset to predict six different disease outcomes in 2019 and evaluated model performances on several metrics.</p><p><strong>Results: </strong>The AutoML tools showed improvement from the baseline random forest model but did not differ significantly from each other. All models recorded low area under the precision-recall curve and failed to predict true positives while keeping the true negative rate high. Model performance was not directly related to prevalence. We provide a specific use-case to illustrate how to select a threshold that gives the best balance between true and false positive rates, as this is an important consideration in medical applications.</p><p><strong>Discussion: </strong>Healthcare datasets present several challenges for AutoML tools, including large sample size, high imbalance, and limitations in the available features. Improvements in scalability, combinations of imbalance-learning resampling and ensemble approaches, and curated feature selection are possible next steps to achieve better performance.</p><p><strong>Conclusion: </strong>Among the three explored, no AutoML tool consistently outperforms the rest in terms of predictive performance. The performances of the models in this study suggest that there may be room for improvement in handling medical claims data. Finally, selection of the optimal prediction threshold should be guided by the specific practical application.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":" ","pages":"15"},"PeriodicalIF":6.1000,"publicationDate":"2022-07-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9327416/pdf/","citationCount":"8","resultStr":"{\"title\":\"Benchmarking AutoML frameworks for disease prediction using medical claims.\",\"authors\":\"Roland Albert A Romero, Mariefel Nicole Y Deypalan, Suchit Mehrotra, John Titus Jungao, Natalie E Sheils, Elisabetta Manduchi, Jason H Moore\",\"doi\":\"10.1186/s13040-022-00300-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>Ascertain and compare the performances of Automated Machine Learning (AutoML) tools on large, highly imbalanced healthcare datasets.</p><p><strong>Materials and methods: </strong>We generated a large dataset using historical de-identified administrative claims including demographic information and flags for disease codes in four different time windows prior to 2019. We then trained three AutoML tools on this dataset to predict six different disease outcomes in 2019 and evaluated model performances on several metrics.</p><p><strong>Results: </strong>The AutoML tools showed improvement from the baseline random forest model but did not differ significantly from each other. All models recorded low area under the precision-recall curve and failed to predict true positives while keeping the true negative rate high. Model performance was not directly related to prevalence. We provide a specific use-case to illustrate how to select a threshold that gives the best balance between true and false positive rates, as this is an important consideration in medical applications.</p><p><strong>Discussion: </strong>Healthcare datasets present several challenges for AutoML tools, including large sample size, high imbalance, and limitations in the available features. Improvements in scalability, combinations of imbalance-learning resampling and ensemble approaches, and curated feature selection are possible next steps to achieve better performance.</p><p><strong>Conclusion: </strong>Among the three explored, no AutoML tool consistently outperforms the rest in terms of predictive performance. The performances of the models in this study suggest that there may be room for improvement in handling medical claims data. Finally, selection of the optimal prediction threshold should be guided by the specific practical application.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\" \",\"pages\":\"15\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2022-07-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9327416/pdf/\",\"citationCount\":\"8\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-022-00300-2\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-022-00300-2","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Benchmarking AutoML frameworks for disease prediction using medical claims.
Objectives: Ascertain and compare the performances of Automated Machine Learning (AutoML) tools on large, highly imbalanced healthcare datasets.
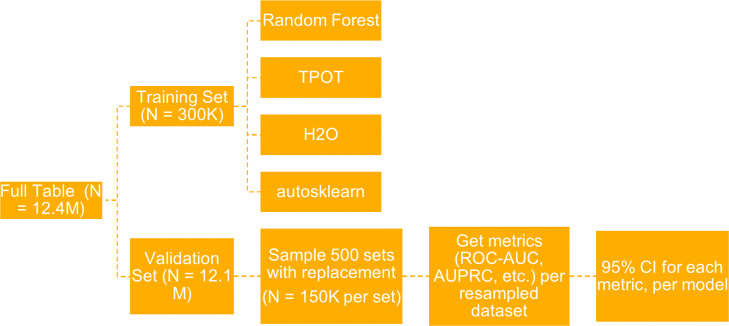
Materials and methods: We generated a large dataset using historical de-identified administrative claims including demographic information and flags for disease codes in four different time windows prior to 2019. We then trained three AutoML tools on this dataset to predict six different disease outcomes in 2019 and evaluated model performances on several metrics.
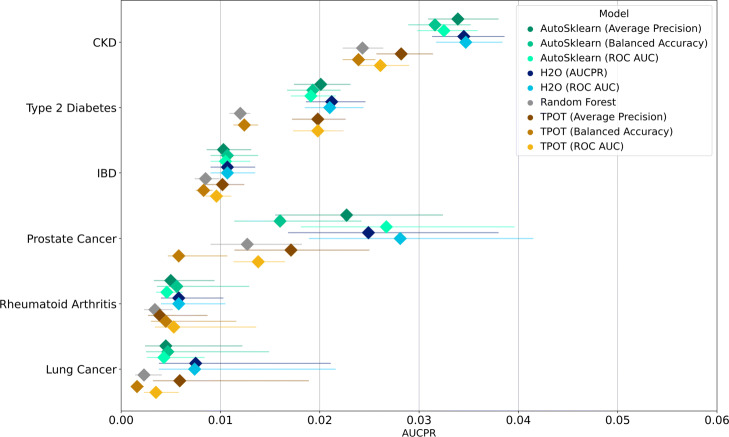
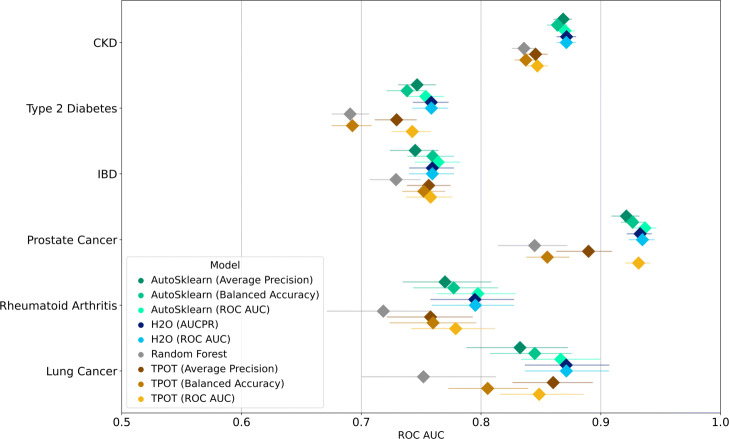
Results: The AutoML tools showed improvement from the baseline random forest model but did not differ significantly from each other. All models recorded low area under the precision-recall curve and failed to predict true positives while keeping the true negative rate high. Model performance was not directly related to prevalence. We provide a specific use-case to illustrate how to select a threshold that gives the best balance between true and false positive rates, as this is an important consideration in medical applications.
Discussion: Healthcare datasets present several challenges for AutoML tools, including large sample size, high imbalance, and limitations in the available features. Improvements in scalability, combinations of imbalance-learning resampling and ensemble approaches, and curated feature selection are possible next steps to achieve better performance.
Conclusion: Among the three explored, no AutoML tool consistently outperforms the rest in terms of predictive performance. The performances of the models in this study suggest that there may be room for improvement in handling medical claims data. Finally, selection of the optimal prediction threshold should be guided by the specific practical application.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
