Fahmi Y Al-Ashwal, Mohammed Zawiah, Lobna Gharaibeh, Rana Abu-Farha, Ahmad Naoras Bitar
{"title":"评估ChatGPT-3.5、ChatGPT-4、Bing AI和Bard对抗常规药物相互作用临床工具的敏感性、特异性和准确性。","authors":"Fahmi Y Al-Ashwal, Mohammed Zawiah, Lobna Gharaibeh, Rana Abu-Farha, Ahmad Naoras Bitar","doi":"10.2147/DHPS.S425858","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>AI platforms are equipped with advanced algorithms that have the potential to offer a wide range of applications in healthcare services. However, information about the accuracy of AI chatbots against conventional drug-drug interaction tools is limited. This study aimed to assess the sensitivity, specificity, and accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard in predicting drug-drug interactions.</p><p><strong>Methods: </strong>AI-based chatbots (ie, ChatGPT-3.5, ChatGPT-4, Microsoft Bing AI, and Google Bard) were compared for their abilities to detect clinically relevant DDIs for 255 drug pairs. Descriptive statistics, such as specificity, sensitivity, accuracy, negative predictive value (NPV), and positive predictive value (PPV), were calculated for each tool.</p><p><strong>Results: </strong>When a subscription tool was used as a reference, the specificity ranged from a low of 0.372 (ChatGPT-3.5) to a high of 0.769 (Microsoft Bing AI). Also, Microsoft Bing AI had the highest performance with an accuracy score of 0.788, with ChatGPT-3.5 having the lowest accuracy rate of 0.469. There was an overall improvement in performance for all the programs when the reference tool switched to a free DDI source, but still, ChatGPT-3.5 had the lowest specificity (0.392) and accuracy (0.525), and Microsoft Bing AI demonstrated the highest specificity (0.892) and accuracy (0.890). When assessing the consistency of accuracy across two different drug classes, ChatGPT-3.5 and ChatGPT-4 showed the highest variability in accuracy. In addition, ChatGPT-3.5, ChatGPT-4, and Bard exhibited the highest fluctuations in specificity when analyzing two medications belonging to the same drug class.</p><p><strong>Conclusion: </strong>Bing AI had the highest accuracy and specificity, outperforming Google's Bard, ChatGPT-3.5, and ChatGPT-4. The findings highlight the significant potential these AI tools hold in transforming patient care. While the current AI platforms evaluated are not without limitations, their ability to quickly analyze potentially significant interactions with good sensitivity suggests a promising step towards improved patient safety.</p>","PeriodicalId":11377,"journal":{"name":"Drug, Healthcare and Patient Safety","volume":"15 ","pages":"137-147"},"PeriodicalIF":3.4000,"publicationDate":"2023-09-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/18/c7/dhps-15-137.PMC10518176.pdf","citationCount":"0","resultStr":"{\"title\":\"Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools.\",\"authors\":\"Fahmi Y Al-Ashwal, Mohammed Zawiah, Lobna Gharaibeh, Rana Abu-Farha, Ahmad Naoras Bitar\",\"doi\":\"10.2147/DHPS.S425858\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>AI platforms are equipped with advanced algorithms that have the potential to offer a wide range of applications in healthcare services. However, information about the accuracy of AI chatbots against conventional drug-drug interaction tools is limited. This study aimed to assess the sensitivity, specificity, and accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard in predicting drug-drug interactions.</p><p><strong>Methods: </strong>AI-based chatbots (ie, ChatGPT-3.5, ChatGPT-4, Microsoft Bing AI, and Google Bard) were compared for their abilities to detect clinically relevant DDIs for 255 drug pairs. Descriptive statistics, such as specificity, sensitivity, accuracy, negative predictive value (NPV), and positive predictive value (PPV), were calculated for each tool.</p><p><strong>Results: </strong>When a subscription tool was used as a reference, the specificity ranged from a low of 0.372 (ChatGPT-3.5) to a high of 0.769 (Microsoft Bing AI). Also, Microsoft Bing AI had the highest performance with an accuracy score of 0.788, with ChatGPT-3.5 having the lowest accuracy rate of 0.469. There was an overall improvement in performance for all the programs when the reference tool switched to a free DDI source, but still, ChatGPT-3.5 had the lowest specificity (0.392) and accuracy (0.525), and Microsoft Bing AI demonstrated the highest specificity (0.892) and accuracy (0.890). When assessing the consistency of accuracy across two different drug classes, ChatGPT-3.5 and ChatGPT-4 showed the highest variability in accuracy. In addition, ChatGPT-3.5, ChatGPT-4, and Bard exhibited the highest fluctuations in specificity when analyzing two medications belonging to the same drug class.</p><p><strong>Conclusion: </strong>Bing AI had the highest accuracy and specificity, outperforming Google's Bard, ChatGPT-3.5, and ChatGPT-4. The findings highlight the significant potential these AI tools hold in transforming patient care. While the current AI platforms evaluated are not without limitations, their ability to quickly analyze potentially significant interactions with good sensitivity suggests a promising step towards improved patient safety.</p>\",\"PeriodicalId\":11377,\"journal\":{\"name\":\"Drug, Healthcare and Patient Safety\",\"volume\":\"15 \",\"pages\":\"137-147\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2023-09-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/18/c7/dhps-15-137.PMC10518176.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Drug, Healthcare and Patient Safety\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2147/DHPS.S425858\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Drug, Healthcare and Patient Safety","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2147/DHPS.S425858","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools.
Background: AI platforms are equipped with advanced algorithms that have the potential to offer a wide range of applications in healthcare services. However, information about the accuracy of AI chatbots against conventional drug-drug interaction tools is limited. This study aimed to assess the sensitivity, specificity, and accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard in predicting drug-drug interactions.
Methods: AI-based chatbots (ie, ChatGPT-3.5, ChatGPT-4, Microsoft Bing AI, and Google Bard) were compared for their abilities to detect clinically relevant DDIs for 255 drug pairs. Descriptive statistics, such as specificity, sensitivity, accuracy, negative predictive value (NPV), and positive predictive value (PPV), were calculated for each tool.
Results: When a subscription tool was used as a reference, the specificity ranged from a low of 0.372 (ChatGPT-3.5) to a high of 0.769 (Microsoft Bing AI). Also, Microsoft Bing AI had the highest performance with an accuracy score of 0.788, with ChatGPT-3.5 having the lowest accuracy rate of 0.469. There was an overall improvement in performance for all the programs when the reference tool switched to a free DDI source, but still, ChatGPT-3.5 had the lowest specificity (0.392) and accuracy (0.525), and Microsoft Bing AI demonstrated the highest specificity (0.892) and accuracy (0.890). When assessing the consistency of accuracy across two different drug classes, ChatGPT-3.5 and ChatGPT-4 showed the highest variability in accuracy. In addition, ChatGPT-3.5, ChatGPT-4, and Bard exhibited the highest fluctuations in specificity when analyzing two medications belonging to the same drug class.
Conclusion: Bing AI had the highest accuracy and specificity, outperforming Google's Bard, ChatGPT-3.5, and ChatGPT-4. The findings highlight the significant potential these AI tools hold in transforming patient care. While the current AI platforms evaluated are not without limitations, their ability to quickly analyze potentially significant interactions with good sensitivity suggests a promising step towards improved patient safety.
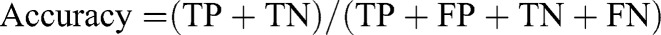
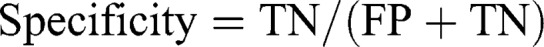
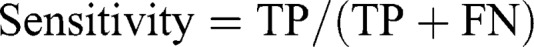



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
