{"title":"用于重度抑郁症风险预测的特征工程和预训练的序列自动编码器。","authors":"Barrett W Jones, Warren D Taylor, Colin G Walsh","doi":"10.1093/jamiaopen/ooad086","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>We evaluated autoencoders as a feature engineering and pretraining technique to improve major depressive disorder (MDD) prognostic risk prediction. Autoencoders can represent temporal feature relationships not identified by aggregate features. The predictive performance of autoencoders of multiple sequential structures was evaluated as feature engineering and pretraining strategies on an array of prediction tasks and compared to a restricted Boltzmann machine (RBM) and random forests as a benchmark.</p><p><strong>Materials and methods: </strong>We study MDD patients from Vanderbilt University Medical Center. Autoencoder models with Attention and long-short-term memory (LSTM) layers were trained to create latent representations of the input data. Predictive performance was evaluated temporally by fitting random forest models to predict future outcomes with engineered features as input and using autoencoder weights to initialize neural network layers. We evaluated area under the precision-recall curve (AUPRC) trends and variation over the study population's treatment course.</p><p><strong>Results: </strong>The pretrained LSTM model improved predictive performance over pretrained Attention models and benchmarks in 3 of 4 outcomes including self-harm/suicide attempt (AUPRCs, LSTM pretrained = 0.012, Attention pretrained = 0.010, RBM = 0.009, random forest = 0.005). The use of autoencoders for feature engineering had varied results, with benchmarks outperforming LSTM and Attention encodings on the self-harm/suicide attempt outcome (AUPRCs, LSTM encodings = 0.003, Attention encodings = 0.004, RBM = 0.009, random forest = 0.005).</p><p><strong>Discussion: </strong>Improvement in prediction resulting from pretraining has the potential for increased clinical impact of MDD risk models. We did not find evidence that the use of temporal feature encodings was additive to predictive performance in the study population. This suggests that predictive information retained by model weights may be lost during encoding. LSTM pretrained model predictive performance is shown to be clinically useful and improves over state-of-the-art predictors in the MDD phenotype. LSTM model performance warrants consideration of use in future related studies.</p><p><strong>Conclusion: </strong>LSTM models with pretrained weights from autoencoders were able to outperform the benchmark and a pretrained Attention model. Future researchers developing risk models in MDD may benefit from the use of LSTM autoencoder pretrained weights.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 4","pages":"ooad086"},"PeriodicalIF":3.4000,"publicationDate":"2023-10-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10561992/pdf/","citationCount":"0","resultStr":"{\"title\":\"Sequential autoencoders for feature engineering and pretraining in major depressive disorder risk prediction.\",\"authors\":\"Barrett W Jones, Warren D Taylor, Colin G Walsh\",\"doi\":\"10.1093/jamiaopen/ooad086\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>We evaluated autoencoders as a feature engineering and pretraining technique to improve major depressive disorder (MDD) prognostic risk prediction. Autoencoders can represent temporal feature relationships not identified by aggregate features. The predictive performance of autoencoders of multiple sequential structures was evaluated as feature engineering and pretraining strategies on an array of prediction tasks and compared to a restricted Boltzmann machine (RBM) and random forests as a benchmark.</p><p><strong>Materials and methods: </strong>We study MDD patients from Vanderbilt University Medical Center. Autoencoder models with Attention and long-short-term memory (LSTM) layers were trained to create latent representations of the input data. Predictive performance was evaluated temporally by fitting random forest models to predict future outcomes with engineered features as input and using autoencoder weights to initialize neural network layers. We evaluated area under the precision-recall curve (AUPRC) trends and variation over the study population's treatment course.</p><p><strong>Results: </strong>The pretrained LSTM model improved predictive performance over pretrained Attention models and benchmarks in 3 of 4 outcomes including self-harm/suicide attempt (AUPRCs, LSTM pretrained = 0.012, Attention pretrained = 0.010, RBM = 0.009, random forest = 0.005). The use of autoencoders for feature engineering had varied results, with benchmarks outperforming LSTM and Attention encodings on the self-harm/suicide attempt outcome (AUPRCs, LSTM encodings = 0.003, Attention encodings = 0.004, RBM = 0.009, random forest = 0.005).</p><p><strong>Discussion: </strong>Improvement in prediction resulting from pretraining has the potential for increased clinical impact of MDD risk models. We did not find evidence that the use of temporal feature encodings was additive to predictive performance in the study population. This suggests that predictive information retained by model weights may be lost during encoding. LSTM pretrained model predictive performance is shown to be clinically useful and improves over state-of-the-art predictors in the MDD phenotype. LSTM model performance warrants consideration of use in future related studies.</p><p><strong>Conclusion: </strong>LSTM models with pretrained weights from autoencoders were able to outperform the benchmark and a pretrained Attention model. Future researchers developing risk models in MDD may benefit from the use of LSTM autoencoder pretrained weights.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"6 4\",\"pages\":\"ooad086\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2023-10-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10561992/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooad086\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad086","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/12/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Sequential autoencoders for feature engineering and pretraining in major depressive disorder risk prediction.
Objectives: We evaluated autoencoders as a feature engineering and pretraining technique to improve major depressive disorder (MDD) prognostic risk prediction. Autoencoders can represent temporal feature relationships not identified by aggregate features. The predictive performance of autoencoders of multiple sequential structures was evaluated as feature engineering and pretraining strategies on an array of prediction tasks and compared to a restricted Boltzmann machine (RBM) and random forests as a benchmark.
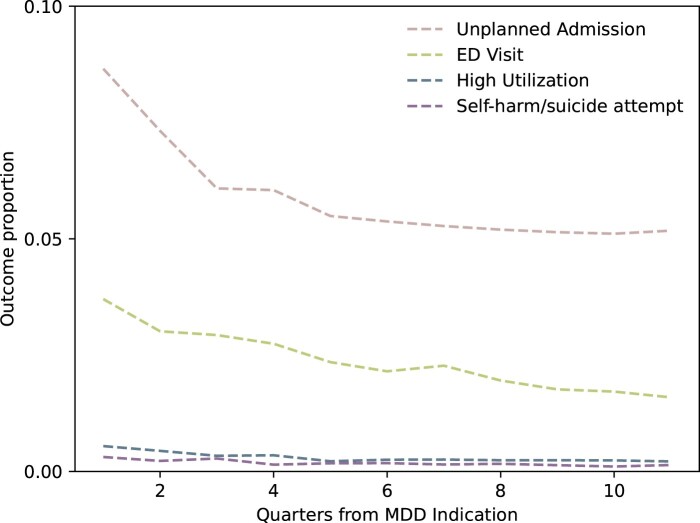
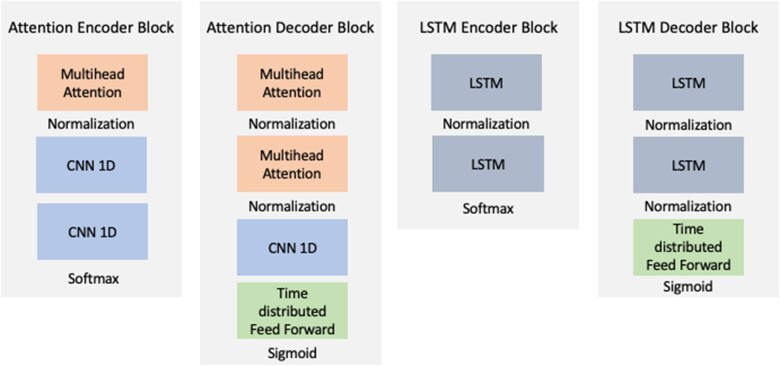
Materials and methods: We study MDD patients from Vanderbilt University Medical Center. Autoencoder models with Attention and long-short-term memory (LSTM) layers were trained to create latent representations of the input data. Predictive performance was evaluated temporally by fitting random forest models to predict future outcomes with engineered features as input and using autoencoder weights to initialize neural network layers. We evaluated area under the precision-recall curve (AUPRC) trends and variation over the study population's treatment course.
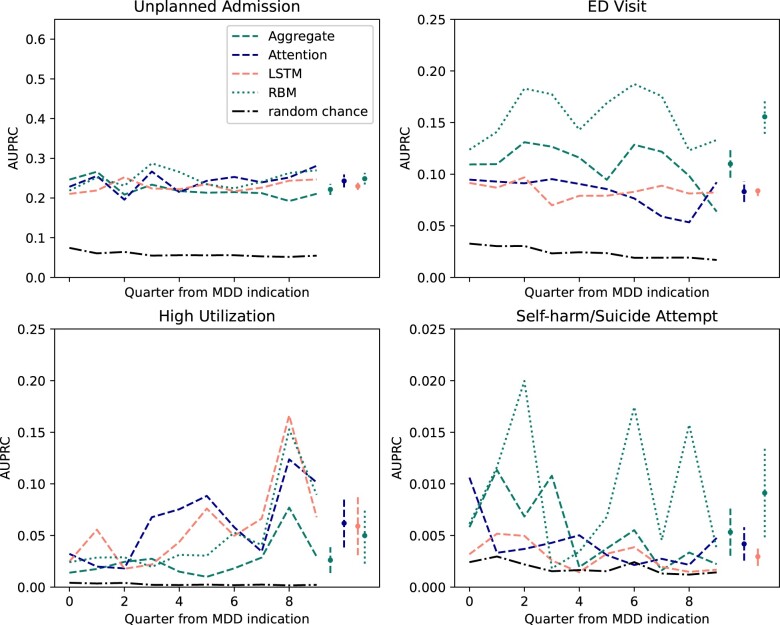
Results: The pretrained LSTM model improved predictive performance over pretrained Attention models and benchmarks in 3 of 4 outcomes including self-harm/suicide attempt (AUPRCs, LSTM pretrained = 0.012, Attention pretrained = 0.010, RBM = 0.009, random forest = 0.005). The use of autoencoders for feature engineering had varied results, with benchmarks outperforming LSTM and Attention encodings on the self-harm/suicide attempt outcome (AUPRCs, LSTM encodings = 0.003, Attention encodings = 0.004, RBM = 0.009, random forest = 0.005).
Discussion: Improvement in prediction resulting from pretraining has the potential for increased clinical impact of MDD risk models. We did not find evidence that the use of temporal feature encodings was additive to predictive performance in the study population. This suggests that predictive information retained by model weights may be lost during encoding. LSTM pretrained model predictive performance is shown to be clinically useful and improves over state-of-the-art predictors in the MDD phenotype. LSTM model performance warrants consideration of use in future related studies.
Conclusion: LSTM models with pretrained weights from autoencoders were able to outperform the benchmark and a pretrained Attention model. Future researchers developing risk models in MDD may benefit from the use of LSTM autoencoder pretrained weights.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
