{"title":"基于规则的自然语言处理从脑卒中患者的放射学报告中提取大血管闭塞和脑水肿的特征","authors":"Zohair Siddiqui , Kunal Bhatia , Aaron Corbin , Rajat Dhar","doi":"10.1016/j.neuri.2023.100129","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><p>Large vessel occlusion (LVO) stroke research is limited regarding high-risk patient groups for complications including cerebral edema. Large, well-phenotyped cohorts hold potential insights, but identifying cohorts and manually extracting outcomes is impractical. Natural language processing (NLP) software has previously extracted stroke characteristics from radiology reports, but there has not been an integrated extraction of both LVO classification and acute stroke outcomes.</p></div><div><h3>Methods</h3><p>We constructed a rules-based NLP pipeline that extracted presence/location of arterial occlusion and core/penumbral volumes from multimodal CT reports, along with presence of edema and midline shift on follow-up CTs. The algorithm flagged inconsistent reports for manual adjudication. We validated performance over two cohorts and analyzed the associations between NLP-extracted variables and clinical edema outcomes.</p></div><div><h3>Results</h3><p>The algorithm identified occlusions in the development (<span><math><mi>n</mi><mo>=</mo><mn>577</mn></math></span>) and test cohorts (<span><math><mi>n</mi><mo>=</mo><mn>442</mn></math></span>) with 94% and 85% recall, increasing to 97% and 93% after review of flagged reports. It could distinguish proximal ICA/M1 from distal occlusions with 96% recall and correctly extracted 98% of core/penumbral volumes. NLP recall was 93% and 86% for identifying edema and midline shift from follow-up reports of 213 patients with ICA/MCA occlusions. NLP-extracted radiographic edema captured 89% of those who developed clinical cerebral edema, which was more likely in those with NLP-identified proximal vs distal occlusions and associated with significantly higher core/penumbral volumes.</p></div><div><h3>Conclusion</h3><p>A rules-based NLP pipeline can accurately identify and phenotype an LVO cohort, yielding clinical associations with stroke research implications.</p></div>","PeriodicalId":74295,"journal":{"name":"Neuroscience informatics","volume":"3 2","pages":"Article 100129"},"PeriodicalIF":0.0000,"publicationDate":"2023-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Rules-based natural language processing to extract features of large vessel occlusion and cerebral edema from radiology reports in stroke patients\",\"authors\":\"Zohair Siddiqui , Kunal Bhatia , Aaron Corbin , Rajat Dhar\",\"doi\":\"10.1016/j.neuri.2023.100129\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background</h3><p>Large vessel occlusion (LVO) stroke research is limited regarding high-risk patient groups for complications including cerebral edema. Large, well-phenotyped cohorts hold potential insights, but identifying cohorts and manually extracting outcomes is impractical. Natural language processing (NLP) software has previously extracted stroke characteristics from radiology reports, but there has not been an integrated extraction of both LVO classification and acute stroke outcomes.</p></div><div><h3>Methods</h3><p>We constructed a rules-based NLP pipeline that extracted presence/location of arterial occlusion and core/penumbral volumes from multimodal CT reports, along with presence of edema and midline shift on follow-up CTs. The algorithm flagged inconsistent reports for manual adjudication. We validated performance over two cohorts and analyzed the associations between NLP-extracted variables and clinical edema outcomes.</p></div><div><h3>Results</h3><p>The algorithm identified occlusions in the development (<span><math><mi>n</mi><mo>=</mo><mn>577</mn></math></span>) and test cohorts (<span><math><mi>n</mi><mo>=</mo><mn>442</mn></math></span>) with 94% and 85% recall, increasing to 97% and 93% after review of flagged reports. It could distinguish proximal ICA/M1 from distal occlusions with 96% recall and correctly extracted 98% of core/penumbral volumes. NLP recall was 93% and 86% for identifying edema and midline shift from follow-up reports of 213 patients with ICA/MCA occlusions. NLP-extracted radiographic edema captured 89% of those who developed clinical cerebral edema, which was more likely in those with NLP-identified proximal vs distal occlusions and associated with significantly higher core/penumbral volumes.</p></div><div><h3>Conclusion</h3><p>A rules-based NLP pipeline can accurately identify and phenotype an LVO cohort, yielding clinical associations with stroke research implications.</p></div>\",\"PeriodicalId\":74295,\"journal\":{\"name\":\"Neuroscience informatics\",\"volume\":\"3 2\",\"pages\":\"Article 100129\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neuroscience informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2772528623000146\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/4/19 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neuroscience informatics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2772528623000146","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/4/19 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Rules-based natural language processing to extract features of large vessel occlusion and cerebral edema from radiology reports in stroke patients
Background
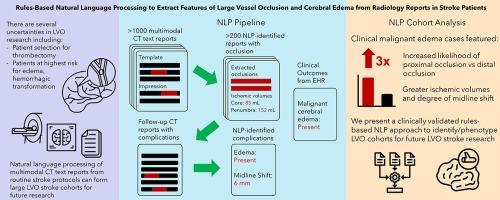
Large vessel occlusion (LVO) stroke research is limited regarding high-risk patient groups for complications including cerebral edema. Large, well-phenotyped cohorts hold potential insights, but identifying cohorts and manually extracting outcomes is impractical. Natural language processing (NLP) software has previously extracted stroke characteristics from radiology reports, but there has not been an integrated extraction of both LVO classification and acute stroke outcomes.
Methods
We constructed a rules-based NLP pipeline that extracted presence/location of arterial occlusion and core/penumbral volumes from multimodal CT reports, along with presence of edema and midline shift on follow-up CTs. The algorithm flagged inconsistent reports for manual adjudication. We validated performance over two cohorts and analyzed the associations between NLP-extracted variables and clinical edema outcomes.
Results
The algorithm identified occlusions in the development () and test cohorts () with 94% and 85% recall, increasing to 97% and 93% after review of flagged reports. It could distinguish proximal ICA/M1 from distal occlusions with 96% recall and correctly extracted 98% of core/penumbral volumes. NLP recall was 93% and 86% for identifying edema and midline shift from follow-up reports of 213 patients with ICA/MCA occlusions. NLP-extracted radiographic edema captured 89% of those who developed clinical cerebral edema, which was more likely in those with NLP-identified proximal vs distal occlusions and associated with significantly higher core/penumbral volumes.
Conclusion
A rules-based NLP pipeline can accurately identify and phenotype an LVO cohort, yielding clinical associations with stroke research implications.
Neuroscience informaticsSurgery, Radiology and Imaging, Information Systems, Neurology, Artificial Intelligence, Computer Science Applications, Signal Processing, Critical Care and Intensive Care Medicine, Health Informatics, Clinical Neurology, Pathology and Medical Technology




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
