{"title":"精密电子元件量产过程中的不良率预测和故障原因诊断","authors":"Hiromasa Kaneko","doi":"10.1002/ansa.202300019","DOIUrl":null,"url":null,"abstract":"<p>Many defects occur during the mass production of precision electrical components. To control and manage them, process variables (PVs), such as the temperature, pressure, flow rate, and liquid level, are measured and time-series data analyzed. However, identification of point of defects is difficult as any operation can cause defects and multiple equipment units are used in parallel for some operations. This study considers the combination of unfavourable conditions between operations to predict the defect rate (DR) of products. A dataset measured in an actual mass-production process for precision electrical components is analysed to predict the DR of the products. Data analysis is performed on a dataset generated from an actual mass-production process for precision electrical components, and machine learning models. are constructed using ensemble learning methods, such as random forests, the gradient boosting decision tree, XGBoost, and LightGBM. Conventional univariate analyses only show a maximum correlation coefficient of 0.17 with a DR and process variables (PVs). In this study, we improved the correlation coefficient to 0.73 using a multivariate analysis, including the data of PVs that are not considered important in the process, and appropriately transformed PVs based on the domain knowledge of the process. Furthermore, PVs that were closely related to the DR could be diagnosed based on the feature importance of the constructed machine-learning models. This study confirms the importance of using domain knowledge to improve the prediction ability of machine learning models and the interpretation of constructed models.</p>","PeriodicalId":93411,"journal":{"name":"Analytical science advances","volume":"4 9-10","pages":"312-318"},"PeriodicalIF":4.1000,"publicationDate":"2023-05-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ansa.202300019","citationCount":"0","resultStr":"{\"title\":\"Defect rate prediction and failure-cause diagnosis in a mass-production process for precision electric components\",\"authors\":\"Hiromasa Kaneko\",\"doi\":\"10.1002/ansa.202300019\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Many defects occur during the mass production of precision electrical components. To control and manage them, process variables (PVs), such as the temperature, pressure, flow rate, and liquid level, are measured and time-series data analyzed. However, identification of point of defects is difficult as any operation can cause defects and multiple equipment units are used in parallel for some operations. This study considers the combination of unfavourable conditions between operations to predict the defect rate (DR) of products. A dataset measured in an actual mass-production process for precision electrical components is analysed to predict the DR of the products. Data analysis is performed on a dataset generated from an actual mass-production process for precision electrical components, and machine learning models. are constructed using ensemble learning methods, such as random forests, the gradient boosting decision tree, XGBoost, and LightGBM. Conventional univariate analyses only show a maximum correlation coefficient of 0.17 with a DR and process variables (PVs). In this study, we improved the correlation coefficient to 0.73 using a multivariate analysis, including the data of PVs that are not considered important in the process, and appropriately transformed PVs based on the domain knowledge of the process. Furthermore, PVs that were closely related to the DR could be diagnosed based on the feature importance of the constructed machine-learning models. This study confirms the importance of using domain knowledge to improve the prediction ability of machine learning models and the interpretation of constructed models.</p>\",\"PeriodicalId\":93411,\"journal\":{\"name\":\"Analytical science advances\",\"volume\":\"4 9-10\",\"pages\":\"312-318\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2023-05-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ansa.202300019\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Analytical science advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ansa.202300019\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, ANALYTICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Analytical science advances","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ansa.202300019","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
Defect rate prediction and failure-cause diagnosis in a mass-production process for precision electric components
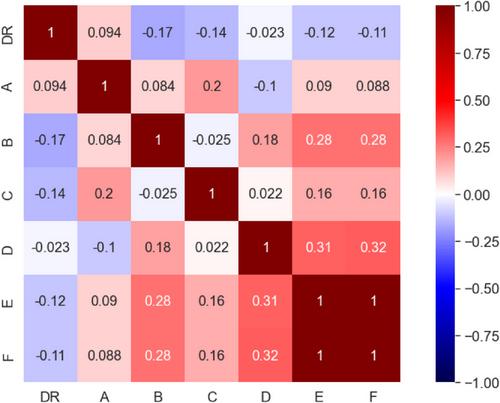
Many defects occur during the mass production of precision electrical components. To control and manage them, process variables (PVs), such as the temperature, pressure, flow rate, and liquid level, are measured and time-series data analyzed. However, identification of point of defects is difficult as any operation can cause defects and multiple equipment units are used in parallel for some operations. This study considers the combination of unfavourable conditions between operations to predict the defect rate (DR) of products. A dataset measured in an actual mass-production process for precision electrical components is analysed to predict the DR of the products. Data analysis is performed on a dataset generated from an actual mass-production process for precision electrical components, and machine learning models. are constructed using ensemble learning methods, such as random forests, the gradient boosting decision tree, XGBoost, and LightGBM. Conventional univariate analyses only show a maximum correlation coefficient of 0.17 with a DR and process variables (PVs). In this study, we improved the correlation coefficient to 0.73 using a multivariate analysis, including the data of PVs that are not considered important in the process, and appropriately transformed PVs based on the domain knowledge of the process. Furthermore, PVs that were closely related to the DR could be diagnosed based on the feature importance of the constructed machine-learning models. This study confirms the importance of using domain knowledge to improve the prediction ability of machine learning models and the interpretation of constructed models.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
