Xiaoqiang Zhu, Xinsheng Yao, Junjie Zhang, Mengyao Zhu, Lihua You, Xiaosong Yang, Jianjun Zhang, He Zhao, Dan Zeng
{"title":"TMSDNet:用于单视图和多视图三维重建的多尺度密集网络变压器","authors":"Xiaoqiang Zhu, Xinsheng Yao, Junjie Zhang, Mengyao Zhu, Lihua You, Xiaosong Yang, Jianjun Zhang, He Zhao, Dan Zeng","doi":"10.1002/cav.2201","DOIUrl":null,"url":null,"abstract":"<p>3D reconstruction is a long-standing problem. Recently, a number of studies have emerged that utilize transformers for 3D reconstruction, and these approaches have demonstrated strong performance. However, transformer-based 3D reconstruction methods tend to establish the transformation relationship between the 2D image and the 3D voxel space directly using transformers or rely solely on the powerful feature extraction capabilities of transformers. They ignore the crucial role played by deep multi-scale representation of the object in the voxel feature domain, which can provide extensive global shape and local detail information about the object in a multi-scale manner. In this article, we propose a novel framework TMSDNet (transformer with multi-scale dense network) for single-view and multi-view 3D reconstruction with transformer to solve this problem. Based on our well-designed combined-transformer Block, which is canonical encoder–decoder architecture, voxel features with spatial order can be extracted from the input image, which are used to further extract multi-scale global features in parallel using a multi-scale residual attention module. Furthermore, a residual dense attention block is introduced for deep local features extraction and adaptive fusion. Finally, the reconstructed objects are produced with the voxel reconstruction block. Experiment results on the benchmarks such as ShapeNet and Pix3D datasets demonstrate that TMSDNet outperforms the existing state-of-the-art reconstruction methods substantially.</p>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"35 1","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2023-08-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"TMSDNet: Transformer with multi-scale dense network for single and multi-view 3D reconstruction\",\"authors\":\"Xiaoqiang Zhu, Xinsheng Yao, Junjie Zhang, Mengyao Zhu, Lihua You, Xiaosong Yang, Jianjun Zhang, He Zhao, Dan Zeng\",\"doi\":\"10.1002/cav.2201\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>3D reconstruction is a long-standing problem. Recently, a number of studies have emerged that utilize transformers for 3D reconstruction, and these approaches have demonstrated strong performance. However, transformer-based 3D reconstruction methods tend to establish the transformation relationship between the 2D image and the 3D voxel space directly using transformers or rely solely on the powerful feature extraction capabilities of transformers. They ignore the crucial role played by deep multi-scale representation of the object in the voxel feature domain, which can provide extensive global shape and local detail information about the object in a multi-scale manner. In this article, we propose a novel framework TMSDNet (transformer with multi-scale dense network) for single-view and multi-view 3D reconstruction with transformer to solve this problem. Based on our well-designed combined-transformer Block, which is canonical encoder–decoder architecture, voxel features with spatial order can be extracted from the input image, which are used to further extract multi-scale global features in parallel using a multi-scale residual attention module. Furthermore, a residual dense attention block is introduced for deep local features extraction and adaptive fusion. Finally, the reconstructed objects are produced with the voxel reconstruction block. Experiment results on the benchmarks such as ShapeNet and Pix3D datasets demonstrate that TMSDNet outperforms the existing state-of-the-art reconstruction methods substantially.</p>\",\"PeriodicalId\":50645,\"journal\":{\"name\":\"Computer Animation and Virtual Worlds\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":1.7000,\"publicationDate\":\"2023-08-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Animation and Virtual Worlds\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/cav.2201\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.2201","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
TMSDNet: Transformer with multi-scale dense network for single and multi-view 3D reconstruction
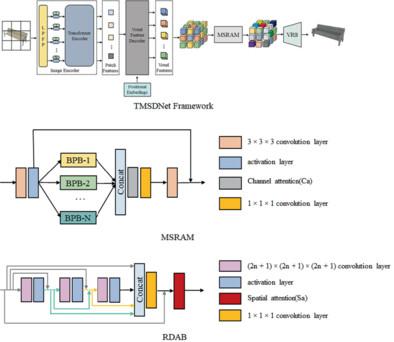
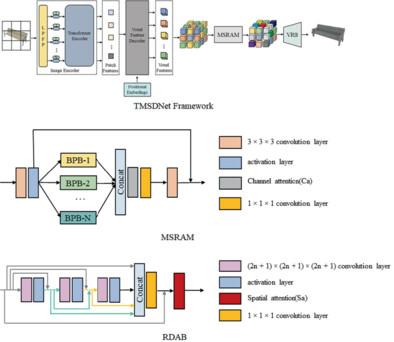
3D reconstruction is a long-standing problem. Recently, a number of studies have emerged that utilize transformers for 3D reconstruction, and these approaches have demonstrated strong performance. However, transformer-based 3D reconstruction methods tend to establish the transformation relationship between the 2D image and the 3D voxel space directly using transformers or rely solely on the powerful feature extraction capabilities of transformers. They ignore the crucial role played by deep multi-scale representation of the object in the voxel feature domain, which can provide extensive global shape and local detail information about the object in a multi-scale manner. In this article, we propose a novel framework TMSDNet (transformer with multi-scale dense network) for single-view and multi-view 3D reconstruction with transformer to solve this problem. Based on our well-designed combined-transformer Block, which is canonical encoder–decoder architecture, voxel features with spatial order can be extracted from the input image, which are used to further extract multi-scale global features in parallel using a multi-scale residual attention module. Furthermore, a residual dense attention block is introduced for deep local features extraction and adaptive fusion. Finally, the reconstructed objects are produced with the voxel reconstruction block. Experiment results on the benchmarks such as ShapeNet and Pix3D datasets demonstrate that TMSDNet outperforms the existing state-of-the-art reconstruction methods substantially.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
