{"title":"遗传性疾病患者全外显子组测序数据中单核苷酸变异的诊断:使用AI变异优先排序(预印本)","authors":"Yu-Shan Huang, Ching Hsu, Yu-Chang Chune, I-Cheng Liao, Hsin Wang, Yi-Lin Lin, Wuh-Liang Hwu, Ni-Chung Lee, Feipei Lai","doi":"10.2196/37701","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In recent years, thanks to the rapid development of next-generation sequencing (NGS) technology, an entire human genome can be sequenced in a short period. As a result, NGS technology is now being widely introduced into clinical diagnosis practice, especially for diagnosis of hereditary disorders. Although the exome data of single-nucleotide variant (SNV) can be generated using these approaches, processing the DNA sequence data of a patient requires multiple tools and complex bioinformatics pipelines.</p><p><strong>Objective: </strong>This study aims to assist physicians to automatically interpret the genetic variation information generated by NGS in a short period. To determine the true causal variants of a patient with genetic disease, currently, physicians often need to view numerous features on every variant manually and search for literature in different databases to understand the effect of genetic variation.</p><p><strong>Methods: </strong>We constructed a machine learning model for predicting disease-causing variants in exome data. We collected sequencing data from whole-exome sequencing (WES) and gene panel as training set, and then integrated variant annotations from multiple genetic databases for model training. The model built ranked SNVs and output the most possible disease-causing candidates. For model testing, we collected WES data from 108 patients with rare genetic disorders in National Taiwan University Hospital. We applied sequencing data and phenotypic information automatically extracted by a keyword extraction tool from patient's electronic medical records into our machine learning model.</p><p><strong>Results: </strong>We succeeded in locating 92.5% (124/134) of the causative variant in the top 10 ranking list among an average of 741 candidate variants per person after filtering. AI Variant Prioritizer was able to assign the target gene to the top rank for around 61.1% (66/108) of the patients, followed by Variant Prioritizer, which assigned it for 44.4% (48/108) of the patients. The cumulative rank result revealed that our AI Variant Prioritizer has the highest accuracy at ranks 1, 5, 10, and 20. It also shows that AI Variant Prioritizer presents better performance than other tools. After adopting the Human Phenotype Ontology (HPO) terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108).</p><p><strong>Conclusions: </strong>We successfully applied sequencing data from WES and free-text phenotypic information of patient's disease automatically extracted by the keyword extraction tool for model training and testing. By interpreting our model, we identified which features of variants are important. Besides, we achieved a satisfactory result on finding the target variant in our testing data set. After adopting the HPO terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108). The performance of the model is similar to that of manual analysis, and it has been used to help National Taiwan University Hospital with a genetic diagnosis.</p>","PeriodicalId":73552,"journal":{"name":"JMIR bioinformatics and biotechnology","volume":" ","pages":"e37701"},"PeriodicalIF":0.0000,"publicationDate":"2022-09-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11168239/pdf/","citationCount":"0","resultStr":"{\"title\":\"Diagnosis of a Single-Nucleotide Variant in Whole-Exome Sequencing Data for Patients With Inherited Diseases: Machine Learning Study Using Artificial Intelligence Variant Prioritization.\",\"authors\":\"Yu-Shan Huang, Ching Hsu, Yu-Chang Chune, I-Cheng Liao, Hsin Wang, Yi-Lin Lin, Wuh-Liang Hwu, Ni-Chung Lee, Feipei Lai\",\"doi\":\"10.2196/37701\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In recent years, thanks to the rapid development of next-generation sequencing (NGS) technology, an entire human genome can be sequenced in a short period. As a result, NGS technology is now being widely introduced into clinical diagnosis practice, especially for diagnosis of hereditary disorders. Although the exome data of single-nucleotide variant (SNV) can be generated using these approaches, processing the DNA sequence data of a patient requires multiple tools and complex bioinformatics pipelines.</p><p><strong>Objective: </strong>This study aims to assist physicians to automatically interpret the genetic variation information generated by NGS in a short period. To determine the true causal variants of a patient with genetic disease, currently, physicians often need to view numerous features on every variant manually and search for literature in different databases to understand the effect of genetic variation.</p><p><strong>Methods: </strong>We constructed a machine learning model for predicting disease-causing variants in exome data. We collected sequencing data from whole-exome sequencing (WES) and gene panel as training set, and then integrated variant annotations from multiple genetic databases for model training. The model built ranked SNVs and output the most possible disease-causing candidates. For model testing, we collected WES data from 108 patients with rare genetic disorders in National Taiwan University Hospital. We applied sequencing data and phenotypic information automatically extracted by a keyword extraction tool from patient's electronic medical records into our machine learning model.</p><p><strong>Results: </strong>We succeeded in locating 92.5% (124/134) of the causative variant in the top 10 ranking list among an average of 741 candidate variants per person after filtering. AI Variant Prioritizer was able to assign the target gene to the top rank for around 61.1% (66/108) of the patients, followed by Variant Prioritizer, which assigned it for 44.4% (48/108) of the patients. The cumulative rank result revealed that our AI Variant Prioritizer has the highest accuracy at ranks 1, 5, 10, and 20. It also shows that AI Variant Prioritizer presents better performance than other tools. After adopting the Human Phenotype Ontology (HPO) terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108).</p><p><strong>Conclusions: </strong>We successfully applied sequencing data from WES and free-text phenotypic information of patient's disease automatically extracted by the keyword extraction tool for model training and testing. By interpreting our model, we identified which features of variants are important. Besides, we achieved a satisfactory result on finding the target variant in our testing data set. After adopting the HPO terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108). The performance of the model is similar to that of manual analysis, and it has been used to help National Taiwan University Hospital with a genetic diagnosis.</p>\",\"PeriodicalId\":73552,\"journal\":{\"name\":\"JMIR bioinformatics and biotechnology\",\"volume\":\" \",\"pages\":\"e37701\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-09-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11168239/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR bioinformatics and biotechnology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/37701\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR bioinformatics and biotechnology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/37701","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Diagnosis of a Single-Nucleotide Variant in Whole-Exome Sequencing Data for Patients With Inherited Diseases: Machine Learning Study Using Artificial Intelligence Variant Prioritization.
Background: In recent years, thanks to the rapid development of next-generation sequencing (NGS) technology, an entire human genome can be sequenced in a short period. As a result, NGS technology is now being widely introduced into clinical diagnosis practice, especially for diagnosis of hereditary disorders. Although the exome data of single-nucleotide variant (SNV) can be generated using these approaches, processing the DNA sequence data of a patient requires multiple tools and complex bioinformatics pipelines.
Objective: This study aims to assist physicians to automatically interpret the genetic variation information generated by NGS in a short period. To determine the true causal variants of a patient with genetic disease, currently, physicians often need to view numerous features on every variant manually and search for literature in different databases to understand the effect of genetic variation.
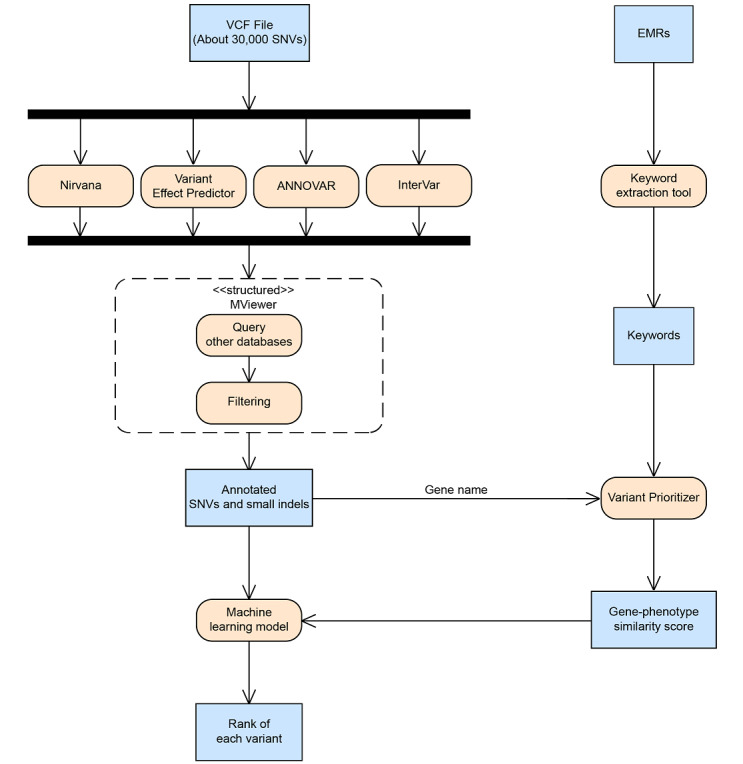
Methods: We constructed a machine learning model for predicting disease-causing variants in exome data. We collected sequencing data from whole-exome sequencing (WES) and gene panel as training set, and then integrated variant annotations from multiple genetic databases for model training. The model built ranked SNVs and output the most possible disease-causing candidates. For model testing, we collected WES data from 108 patients with rare genetic disorders in National Taiwan University Hospital. We applied sequencing data and phenotypic information automatically extracted by a keyword extraction tool from patient's electronic medical records into our machine learning model.
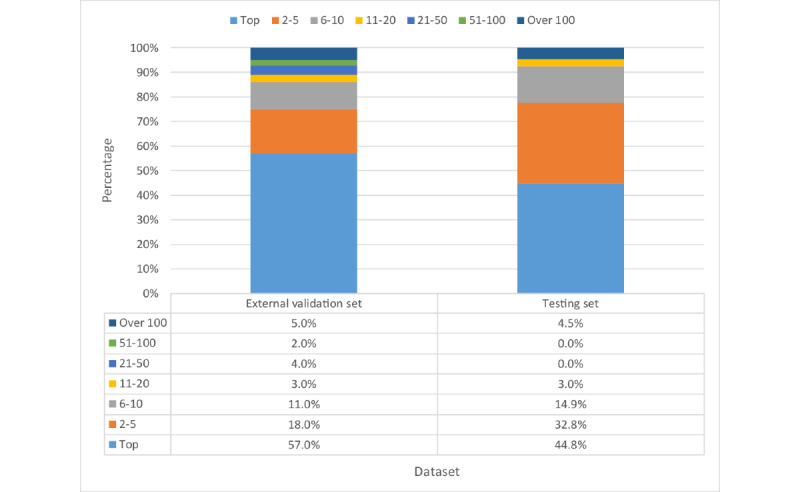
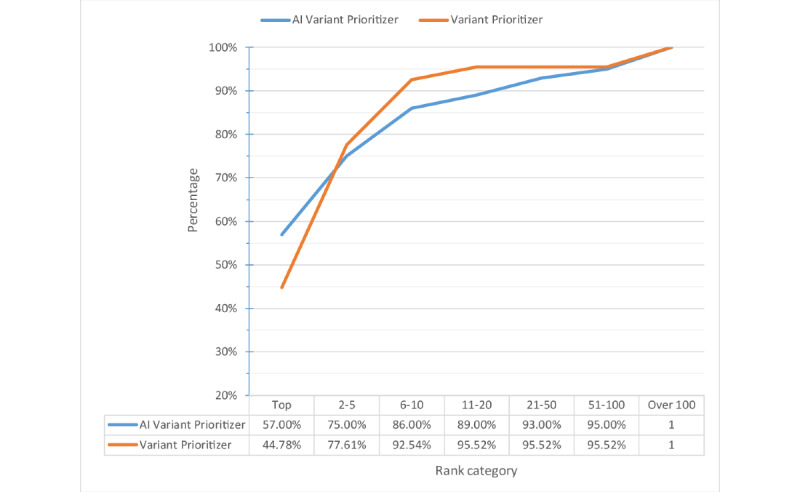
Results: We succeeded in locating 92.5% (124/134) of the causative variant in the top 10 ranking list among an average of 741 candidate variants per person after filtering. AI Variant Prioritizer was able to assign the target gene to the top rank for around 61.1% (66/108) of the patients, followed by Variant Prioritizer, which assigned it for 44.4% (48/108) of the patients. The cumulative rank result revealed that our AI Variant Prioritizer has the highest accuracy at ranks 1, 5, 10, and 20. It also shows that AI Variant Prioritizer presents better performance than other tools. After adopting the Human Phenotype Ontology (HPO) terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108).
Conclusions: We successfully applied sequencing data from WES and free-text phenotypic information of patient's disease automatically extracted by the keyword extraction tool for model training and testing. By interpreting our model, we identified which features of variants are important. Besides, we achieved a satisfactory result on finding the target variant in our testing data set. After adopting the HPO terms by looking up the databases, the top 10 ranking list can be increased to 93.5% (101/108). The performance of the model is similar to that of manual analysis, and it has been used to help National Taiwan University Hospital with a genetic diagnosis.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
