Zahid Halim , Gohar Khan , Babar Shah , Rabia Naseer , Sajid Anwar , Ahsan Shah
{"title":"父母历史数据在自闭症谱系障碍病因调查中的应用:基于数据挖掘的框架","authors":"Zahid Halim , Gohar Khan , Babar Shah , Rabia Naseer , Sajid Anwar , Ahsan Shah","doi":"10.1016/j.irbm.2023.100780","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>Autism Spectrum Disorder (ASD) is acknowledged as a challenge that influences the learning ability of adolescents and also negatively impacts their families. Autism may be caused due to environmental exposure or genetically inherited disorder, however, no definitive or universally customary reasons are known. This makes the issue fairly challenging.</p></div><div><h3>Material and methods</h3><p><span>This work focuses on identifying the reasons of ASD utilizing computational methods. For this, data is collected that focuses on parental history for finding the trigged features by reviewing antenatal, perinatal, and infant hazard factors of ASD. Afterwards, ML techniques are applied on the collected instances to develop a predictive model and identify the reasons to ASD. While collecting the data, samples are obtained for ASD and non-ASD individuals both. A total of 115 features are obtained from each subject. The collected dataset has 47% samples of the subjects with ASD. Dimensionality reduction, and four feature selection methods are applied on the data to eliminate noise and least valued features. The data is verified using two clustering techniques, i.e., </span><em>k</em>-means and <em>k</em>-medoid. To validate the clustering results five clustering validation indices are used. Later, three classifiers, i.e. <em>k</em>-nearest neighbor (<em>k</em><span><span>-NN), Support Vector Machine (SVM), and </span>Artificial Neural Network (ANN) are trained to predict cases with ASD. The frequent items mining technique and the descriptive analysis of the clustered data are utilized to identify the factors that may cause ASD.</span></p></div><div><h3>Results</h3><p>The proposed framework enables to identify the features that may contribute towards ASD. Whereas, for the classification part, SVM classifier performs better than others do with an average accuracy of 98.34% in predicting the ASD cases.</p></div><div><h3>Conclusion</h3><p><span>The results identified stress as the dominant feature and environmental factors, like frequent use of canned food and plastic/steel bottles during </span>fertilization period that may contribute towards ASD.</p></div>","PeriodicalId":14605,"journal":{"name":"Irbm","volume":"44 4","pages":"Article 100780"},"PeriodicalIF":4.2000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"1","resultStr":"{\"title\":\"On the Utility of Parents' Historical Data to Investigate the Causes of Autism Spectrum Disorder: A Data Mining-Based Framework\",\"authors\":\"Zahid Halim , Gohar Khan , Babar Shah , Rabia Naseer , Sajid Anwar , Ahsan Shah\",\"doi\":\"10.1016/j.irbm.2023.100780\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>Autism Spectrum Disorder (ASD) is acknowledged as a challenge that influences the learning ability of adolescents and also negatively impacts their families. Autism may be caused due to environmental exposure or genetically inherited disorder, however, no definitive or universally customary reasons are known. This makes the issue fairly challenging.</p></div><div><h3>Material and methods</h3><p><span>This work focuses on identifying the reasons of ASD utilizing computational methods. For this, data is collected that focuses on parental history for finding the trigged features by reviewing antenatal, perinatal, and infant hazard factors of ASD. Afterwards, ML techniques are applied on the collected instances to develop a predictive model and identify the reasons to ASD. While collecting the data, samples are obtained for ASD and non-ASD individuals both. A total of 115 features are obtained from each subject. The collected dataset has 47% samples of the subjects with ASD. Dimensionality reduction, and four feature selection methods are applied on the data to eliminate noise and least valued features. The data is verified using two clustering techniques, i.e., </span><em>k</em>-means and <em>k</em>-medoid. To validate the clustering results five clustering validation indices are used. Later, three classifiers, i.e. <em>k</em>-nearest neighbor (<em>k</em><span><span>-NN), Support Vector Machine (SVM), and </span>Artificial Neural Network (ANN) are trained to predict cases with ASD. The frequent items mining technique and the descriptive analysis of the clustered data are utilized to identify the factors that may cause ASD.</span></p></div><div><h3>Results</h3><p>The proposed framework enables to identify the features that may contribute towards ASD. Whereas, for the classification part, SVM classifier performs better than others do with an average accuracy of 98.34% in predicting the ASD cases.</p></div><div><h3>Conclusion</h3><p><span>The results identified stress as the dominant feature and environmental factors, like frequent use of canned food and plastic/steel bottles during </span>fertilization period that may contribute towards ASD.</p></div>\",\"PeriodicalId\":14605,\"journal\":{\"name\":\"Irbm\",\"volume\":\"44 4\",\"pages\":\"Article 100780\"},\"PeriodicalIF\":4.2000,\"publicationDate\":\"2023-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Irbm\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1959031823000295\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"ENGINEERING, BIOMEDICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Irbm","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1959031823000295","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
On the Utility of Parents' Historical Data to Investigate the Causes of Autism Spectrum Disorder: A Data Mining-Based Framework
Objective
Autism Spectrum Disorder (ASD) is acknowledged as a challenge that influences the learning ability of adolescents and also negatively impacts their families. Autism may be caused due to environmental exposure or genetically inherited disorder, however, no definitive or universally customary reasons are known. This makes the issue fairly challenging.
Material and methods
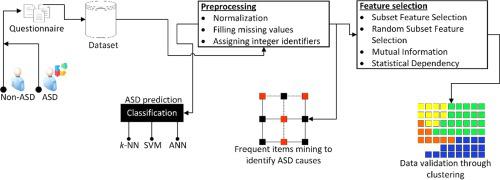
This work focuses on identifying the reasons of ASD utilizing computational methods. For this, data is collected that focuses on parental history for finding the trigged features by reviewing antenatal, perinatal, and infant hazard factors of ASD. Afterwards, ML techniques are applied on the collected instances to develop a predictive model and identify the reasons to ASD. While collecting the data, samples are obtained for ASD and non-ASD individuals both. A total of 115 features are obtained from each subject. The collected dataset has 47% samples of the subjects with ASD. Dimensionality reduction, and four feature selection methods are applied on the data to eliminate noise and least valued features. The data is verified using two clustering techniques, i.e., k-means and k-medoid. To validate the clustering results five clustering validation indices are used. Later, three classifiers, i.e. k-nearest neighbor (k-NN), Support Vector Machine (SVM), and Artificial Neural Network (ANN) are trained to predict cases with ASD. The frequent items mining technique and the descriptive analysis of the clustered data are utilized to identify the factors that may cause ASD.
Results
The proposed framework enables to identify the features that may contribute towards ASD. Whereas, for the classification part, SVM classifier performs better than others do with an average accuracy of 98.34% in predicting the ASD cases.
Conclusion
The results identified stress as the dominant feature and environmental factors, like frequent use of canned food and plastic/steel bottles during fertilization period that may contribute towards ASD.
期刊介绍:
IRBM is the journal of the AGBM (Alliance for engineering in Biology an Medicine / Alliance pour le génie biologique et médical) and the SFGBM (BioMedical Engineering French Society / Société française de génie biologique médical) and the AFIB (French Association of Biomedical Engineers / Association française des ingénieurs biomédicaux).
As a vehicle of information and knowledge in the field of biomedical technologies, IRBM is devoted to fundamental as well as clinical research. Biomedical engineering and use of new technologies are the cornerstones of IRBM, providing authors and users with the latest information. Its six issues per year propose reviews (state-of-the-art and current knowledge), original articles directed at fundamental research and articles focusing on biomedical engineering. All articles are submitted to peer reviewers acting as guarantors for IRBM''s scientific and medical content. The field covered by IRBM includes all the discipline of Biomedical engineering. Thereby, the type of papers published include those that cover the technological and methodological development in:
-Physiological and Biological Signal processing (EEG, MEG, ECG…)-
Medical Image processing-
Biomechanics-
Biomaterials-
Medical Physics-
Biophysics-
Physiological and Biological Sensors-
Information technologies in healthcare-
Disability research-
Computational physiology-
…




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
