{"title":"采用半参数混合模型对具有不可忽略缺失的数据进行聚类","authors":"Marie du Roy de Chaumaray, Matthieu Marbac","doi":"10.1007/s11634-023-00534-w","DOIUrl":null,"url":null,"abstract":"<div><p>We propose a semi-parametric clustering model assuming conditional independence given the component. One advantage is that this model can handle non-ignorable missingness. The model defines each component as a product of univariate probability distributions but makes no assumption on the form of each univariate density. Note that the mixture model is used for clustering but not for estimating the density of the full variables (observed and unobserved). Estimation is performed by maximizing an extension of the smoothed likelihood allowing missingness. This optimization is achieved by a Majorization-Minorization algorithm. We illustrate the relevance of our approach by numerical experiments conducted on simulated data. Under mild assumptions, we show the identifiability of the model defining the distribution of the observed data and the monotonicity of the algorithm. We also propose an extension of this new method to the case of mixed-type data that we illustrate on a real data set. The proposed method is implemented in the R package <span>MNARclust</span> available on CRAN.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 4","pages":"1081 - 1122"},"PeriodicalIF":1.3000,"publicationDate":"2023-02-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Clustering data with non-ignorable missingness using semi-parametric mixture models assuming independence within components\",\"authors\":\"Marie du Roy de Chaumaray, Matthieu Marbac\",\"doi\":\"10.1007/s11634-023-00534-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We propose a semi-parametric clustering model assuming conditional independence given the component. One advantage is that this model can handle non-ignorable missingness. The model defines each component as a product of univariate probability distributions but makes no assumption on the form of each univariate density. Note that the mixture model is used for clustering but not for estimating the density of the full variables (observed and unobserved). Estimation is performed by maximizing an extension of the smoothed likelihood allowing missingness. This optimization is achieved by a Majorization-Minorization algorithm. We illustrate the relevance of our approach by numerical experiments conducted on simulated data. Under mild assumptions, we show the identifiability of the model defining the distribution of the observed data and the monotonicity of the algorithm. We also propose an extension of this new method to the case of mixed-type data that we illustrate on a real data set. The proposed method is implemented in the R package <span>MNARclust</span> available on CRAN.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"17 4\",\"pages\":\"1081 - 1122\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2023-02-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-023-00534-w\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-023-00534-w","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
Clustering data with non-ignorable missingness using semi-parametric mixture models assuming independence within components
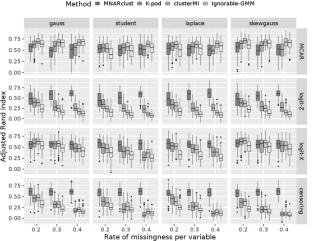
We propose a semi-parametric clustering model assuming conditional independence given the component. One advantage is that this model can handle non-ignorable missingness. The model defines each component as a product of univariate probability distributions but makes no assumption on the form of each univariate density. Note that the mixture model is used for clustering but not for estimating the density of the full variables (observed and unobserved). Estimation is performed by maximizing an extension of the smoothed likelihood allowing missingness. This optimization is achieved by a Majorization-Minorization algorithm. We illustrate the relevance of our approach by numerical experiments conducted on simulated data. Under mild assumptions, we show the identifiability of the model defining the distribution of the observed data and the monotonicity of the algorithm. We also propose an extension of this new method to the case of mixed-type data that we illustrate on a real data set. The proposed method is implemented in the R package MNARclust available on CRAN.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
