Eustasio del Barrio, Hristo Inouzhe, Jean-Michel Loubes
{"title":"吸引-排斥聚类:一种在公平聚类中促进与人口均等相关的多样性的方法","authors":"Eustasio del Barrio, Hristo Inouzhe, Jean-Michel Loubes","doi":"10.1007/s11634-022-00516-4","DOIUrl":null,"url":null,"abstract":"<div><p>We consider the problem of <i>diversity enhancing clustering</i>, i.e, developing clustering methods which produce clusters that favour diversity with respect to a set of protected attributes such as race, sex, age, etc. In the context of <i>fair clustering</i>, diversity plays a major role when fairness is understood as demographic parity. To promote diversity, we introduce perturbations to the distance in the unprotected attributes that account for protected attributes in a way that resembles attraction-repulsion of charged particles in Physics. These perturbations are defined through dissimilarities with a tractable interpretation. Cluster analysis based on attraction-repulsion dissimilarities penalizes homogeneity of the clusters with respect to the protected attributes and leads to an improvement in diversity. An advantage of our approach, which falls into a pre-processing set-up, is its compatibility with a wide variety of clustering methods and whit non-Euclidean data. We illustrate the use of our procedures with both synthetic and real data and provide discussion about the relation between diversity, fairness, and cluster structure.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 4","pages":"859 - 896"},"PeriodicalIF":1.3000,"publicationDate":"2022-10-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-022-00516-4.pdf","citationCount":"0","resultStr":"{\"title\":\"Attraction-repulsion clustering: a way of promoting diversity linked to demographic parity in fair clustering\",\"authors\":\"Eustasio del Barrio, Hristo Inouzhe, Jean-Michel Loubes\",\"doi\":\"10.1007/s11634-022-00516-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We consider the problem of <i>diversity enhancing clustering</i>, i.e, developing clustering methods which produce clusters that favour diversity with respect to a set of protected attributes such as race, sex, age, etc. In the context of <i>fair clustering</i>, diversity plays a major role when fairness is understood as demographic parity. To promote diversity, we introduce perturbations to the distance in the unprotected attributes that account for protected attributes in a way that resembles attraction-repulsion of charged particles in Physics. These perturbations are defined through dissimilarities with a tractable interpretation. Cluster analysis based on attraction-repulsion dissimilarities penalizes homogeneity of the clusters with respect to the protected attributes and leads to an improvement in diversity. An advantage of our approach, which falls into a pre-processing set-up, is its compatibility with a wide variety of clustering methods and whit non-Euclidean data. We illustrate the use of our procedures with both synthetic and real data and provide discussion about the relation between diversity, fairness, and cluster structure.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"17 4\",\"pages\":\"859 - 896\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2022-10-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s11634-022-00516-4.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-022-00516-4\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-022-00516-4","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
Attraction-repulsion clustering: a way of promoting diversity linked to demographic parity in fair clustering
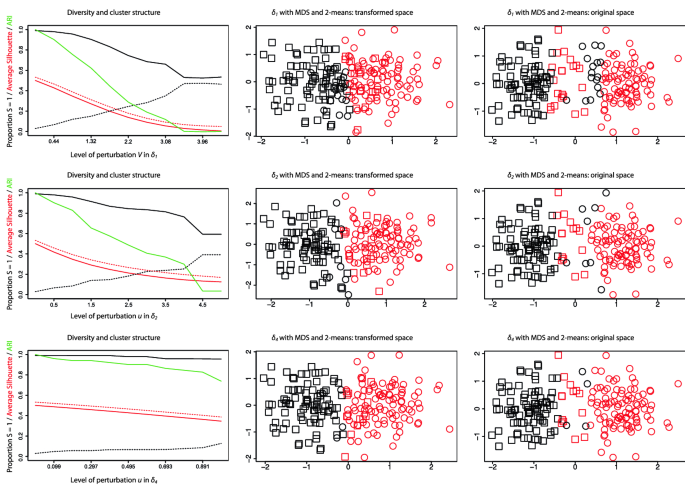
We consider the problem of diversity enhancing clustering, i.e, developing clustering methods which produce clusters that favour diversity with respect to a set of protected attributes such as race, sex, age, etc. In the context of fair clustering, diversity plays a major role when fairness is understood as demographic parity. To promote diversity, we introduce perturbations to the distance in the unprotected attributes that account for protected attributes in a way that resembles attraction-repulsion of charged particles in Physics. These perturbations are defined through dissimilarities with a tractable interpretation. Cluster analysis based on attraction-repulsion dissimilarities penalizes homogeneity of the clusters with respect to the protected attributes and leads to an improvement in diversity. An advantage of our approach, which falls into a pre-processing set-up, is its compatibility with a wide variety of clustering methods and whit non-Euclidean data. We illustrate the use of our procedures with both synthetic and real data and provide discussion about the relation between diversity, fairness, and cluster structure.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
