Samir Khan Townsley, Debraj Basu, Jayneel Vora, Ted Wun, Chen-Nee Chuah, Prabhu R. V. Shankar
{"title":"利用机器学习预测癌症患者的静脉血栓栓塞(VTE)风险","authors":"Samir Khan Townsley, Debraj Basu, Jayneel Vora, Ted Wun, Chen-Nee Chuah, Prabhu R. V. Shankar","doi":"10.1002/hcs2.55","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Background</h3>\n \n <p>The association between cancer and venous thromboembolism (VTE) is well-established with cancer patients accounting for approximately 20% of all VTE incidents. In this paper, we have performed a comparison of machine learning (ML) methods to traditional clinical scoring models for predicting the occurrence of VTE in a cancer patient population, identified important features (clinical biomarkers) for ML model predictions, and examined how different approaches to reducing the number of features used in the model impact model performance.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>We have developed an ML pipeline including three separate feature selection processes and applied it to routine patient care data from the electronic health records of 1910 cancer patients at the University of California Davis Medical Center.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>Our ML-based prediction model achieved an area under the receiver operating characteristic curve of 0.778 ± 0.006 (mean ± SD) when trained on a set of 15 features. This result is comparable with the model performance when trained on all features in our feature pool [0.779 ± 0.006 (mean ± SD) with 29 features]. Our result surpasses the most validated clinical scoring system for VTE risk assessment in cancer patients by 16.1%. We additionally found cancer stage information to be a useful predictor after all performed feature selection processes despite not being used in existing score-based approaches.</p>\n </section>\n \n <section>\n \n <h3> Conclusion</h3>\n \n <p>From these findings, we observe that ML can offer new insights and a significant improvement over the most validated clinical VTE risk scoring systems in cancer patients. The results of this study also allowed us to draw insight into our feature pool and identify the features that could have the most utility in the context of developing an efficient ML classifier. While a model trained on our entire feature pool of 29 features significantly outperformed the traditionally used clinical scoring system, we were able to achieve an equivalent performance using a subset of only 15 features through strategic feature selection methods. These results are encouraging for potential applications of ML to predicting cancer-associated VTE in clinical settings such as in bedside decision support systems where feature availability may be limited.</p>\n </section>\n </div>","PeriodicalId":100601,"journal":{"name":"Health Care Science","volume":"2 4","pages":"205-222"},"PeriodicalIF":3.3000,"publicationDate":"2023-07-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/hcs2.55","citationCount":"0","resultStr":"{\"title\":\"Predicting venous thromboembolism (VTE) risk in cancer patients using machine learning\",\"authors\":\"Samir Khan Townsley, Debraj Basu, Jayneel Vora, Ted Wun, Chen-Nee Chuah, Prabhu R. V. Shankar\",\"doi\":\"10.1002/hcs2.55\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Background</h3>\\n \\n <p>The association between cancer and venous thromboembolism (VTE) is well-established with cancer patients accounting for approximately 20% of all VTE incidents. In this paper, we have performed a comparison of machine learning (ML) methods to traditional clinical scoring models for predicting the occurrence of VTE in a cancer patient population, identified important features (clinical biomarkers) for ML model predictions, and examined how different approaches to reducing the number of features used in the model impact model performance.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>We have developed an ML pipeline including three separate feature selection processes and applied it to routine patient care data from the electronic health records of 1910 cancer patients at the University of California Davis Medical Center.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>Our ML-based prediction model achieved an area under the receiver operating characteristic curve of 0.778 ± 0.006 (mean ± SD) when trained on a set of 15 features. This result is comparable with the model performance when trained on all features in our feature pool [0.779 ± 0.006 (mean ± SD) with 29 features]. Our result surpasses the most validated clinical scoring system for VTE risk assessment in cancer patients by 16.1%. We additionally found cancer stage information to be a useful predictor after all performed feature selection processes despite not being used in existing score-based approaches.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusion</h3>\\n \\n <p>From these findings, we observe that ML can offer new insights and a significant improvement over the most validated clinical VTE risk scoring systems in cancer patients. The results of this study also allowed us to draw insight into our feature pool and identify the features that could have the most utility in the context of developing an efficient ML classifier. While a model trained on our entire feature pool of 29 features significantly outperformed the traditionally used clinical scoring system, we were able to achieve an equivalent performance using a subset of only 15 features through strategic feature selection methods. These results are encouraging for potential applications of ML to predicting cancer-associated VTE in clinical settings such as in bedside decision support systems where feature availability may be limited.</p>\\n </section>\\n </div>\",\"PeriodicalId\":100601,\"journal\":{\"name\":\"Health Care Science\",\"volume\":\"2 4\",\"pages\":\"205-222\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2023-07-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/hcs2.55\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Health Care Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/hcs2.55\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health Care Science","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/hcs2.55","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Predicting venous thromboembolism (VTE) risk in cancer patients using machine learning
Background
The association between cancer and venous thromboembolism (VTE) is well-established with cancer patients accounting for approximately 20% of all VTE incidents. In this paper, we have performed a comparison of machine learning (ML) methods to traditional clinical scoring models for predicting the occurrence of VTE in a cancer patient population, identified important features (clinical biomarkers) for ML model predictions, and examined how different approaches to reducing the number of features used in the model impact model performance.
Methods
We have developed an ML pipeline including three separate feature selection processes and applied it to routine patient care data from the electronic health records of 1910 cancer patients at the University of California Davis Medical Center.
Results
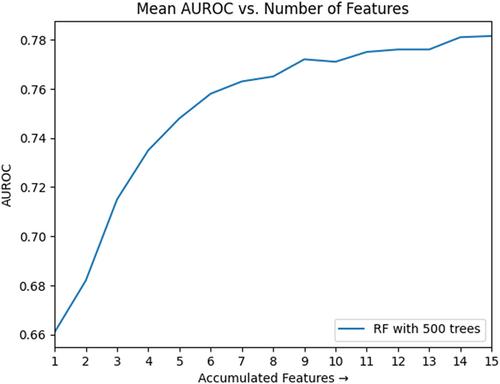
Our ML-based prediction model achieved an area under the receiver operating characteristic curve of 0.778 ± 0.006 (mean ± SD) when trained on a set of 15 features. This result is comparable with the model performance when trained on all features in our feature pool [0.779 ± 0.006 (mean ± SD) with 29 features]. Our result surpasses the most validated clinical scoring system for VTE risk assessment in cancer patients by 16.1%. We additionally found cancer stage information to be a useful predictor after all performed feature selection processes despite not being used in existing score-based approaches.
Conclusion
From these findings, we observe that ML can offer new insights and a significant improvement over the most validated clinical VTE risk scoring systems in cancer patients. The results of this study also allowed us to draw insight into our feature pool and identify the features that could have the most utility in the context of developing an efficient ML classifier. While a model trained on our entire feature pool of 29 features significantly outperformed the traditionally used clinical scoring system, we were able to achieve an equivalent performance using a subset of only 15 features through strategic feature selection methods. These results are encouraging for potential applications of ML to predicting cancer-associated VTE in clinical settings such as in bedside decision support systems where feature availability may be limited.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
