Seo Yi Chng, Paul J. W. Tern, Matthew R. X. Kan, Lionel T. E. Cheng
{"title":"使用自然语言处理的放射学报告自动标记:传统方法和新方法的比较","authors":"Seo Yi Chng, Paul J. W. Tern, Matthew R. X. Kan, Lionel T. E. Cheng","doi":"10.1002/hcs2.40","DOIUrl":null,"url":null,"abstract":"<p>Automated labelling of radiology reports using natural language processing allows for the labelling of ground truth for large datasets of radiological studies that are required for training of computer vision models. This paper explains the necessary data preprocessing steps, reviews the main methods for automated labelling and compares their performance. There are four main methods of automated labelling, namely: (1) rules-based text-matching algorithms, (2) conventional machine learning models, (3) neural network models and (4) Bidirectional Encoder Representations from Transformers (BERT) models. Rules-based labellers perform a brute force search against manually curated keywords and are able to achieve high F1 scores. However, they require proper handling of negative words. Machine learning models require preprocessing that involves tokenization and vectorization of text into numerical vectors. Multilabel classification approaches are required in labelling radiology reports and conventional models can achieve good performance if they have large enough training sets. Deep learning models make use of connected neural networks, often a long short-term memory network, and are similarly able to achieve good performance if trained on a large data set. BERT is a transformer-based model that utilizes attention. Pretrained BERT models only require fine-tuning with small data sets. In particular, domain-specific BERT models can achieve superior performance compared with the other methods for automated labelling.</p>","PeriodicalId":100601,"journal":{"name":"Health Care Science","volume":"2 2","pages":"120-128"},"PeriodicalIF":0.0000,"publicationDate":"2023-04-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/hcs2.40","citationCount":"1","resultStr":"{\"title\":\"Automated labelling of radiology reports using natural language processing: Comparison of traditional and newer methods\",\"authors\":\"Seo Yi Chng, Paul J. W. Tern, Matthew R. X. Kan, Lionel T. E. Cheng\",\"doi\":\"10.1002/hcs2.40\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Automated labelling of radiology reports using natural language processing allows for the labelling of ground truth for large datasets of radiological studies that are required for training of computer vision models. This paper explains the necessary data preprocessing steps, reviews the main methods for automated labelling and compares their performance. There are four main methods of automated labelling, namely: (1) rules-based text-matching algorithms, (2) conventional machine learning models, (3) neural network models and (4) Bidirectional Encoder Representations from Transformers (BERT) models. Rules-based labellers perform a brute force search against manually curated keywords and are able to achieve high F1 scores. However, they require proper handling of negative words. Machine learning models require preprocessing that involves tokenization and vectorization of text into numerical vectors. Multilabel classification approaches are required in labelling radiology reports and conventional models can achieve good performance if they have large enough training sets. Deep learning models make use of connected neural networks, often a long short-term memory network, and are similarly able to achieve good performance if trained on a large data set. BERT is a transformer-based model that utilizes attention. Pretrained BERT models only require fine-tuning with small data sets. In particular, domain-specific BERT models can achieve superior performance compared with the other methods for automated labelling.</p>\",\"PeriodicalId\":100601,\"journal\":{\"name\":\"Health Care Science\",\"volume\":\"2 2\",\"pages\":\"120-128\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-04-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/hcs2.40\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Health Care Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/hcs2.40\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health Care Science","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/hcs2.40","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Automated labelling of radiology reports using natural language processing: Comparison of traditional and newer methods
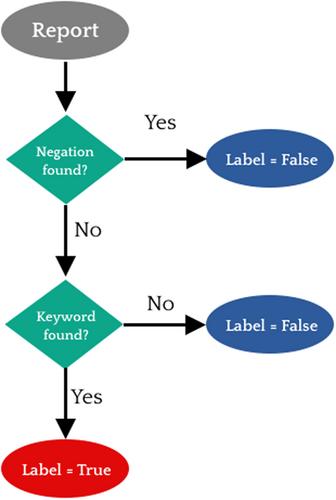
Automated labelling of radiology reports using natural language processing allows for the labelling of ground truth for large datasets of radiological studies that are required for training of computer vision models. This paper explains the necessary data preprocessing steps, reviews the main methods for automated labelling and compares their performance. There are four main methods of automated labelling, namely: (1) rules-based text-matching algorithms, (2) conventional machine learning models, (3) neural network models and (4) Bidirectional Encoder Representations from Transformers (BERT) models. Rules-based labellers perform a brute force search against manually curated keywords and are able to achieve high F1 scores. However, they require proper handling of negative words. Machine learning models require preprocessing that involves tokenization and vectorization of text into numerical vectors. Multilabel classification approaches are required in labelling radiology reports and conventional models can achieve good performance if they have large enough training sets. Deep learning models make use of connected neural networks, often a long short-term memory network, and are similarly able to achieve good performance if trained on a large data set. BERT is a transformer-based model that utilizes attention. Pretrained BERT models only require fine-tuning with small data sets. In particular, domain-specific BERT models can achieve superior performance compared with the other methods for automated labelling.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
