{"title":"基于带深的函数数据聚类K-means初始化","authors":"Javier Albert-Smet, Aurora Torrente, Juan Romo","doi":"10.1007/s11634-022-00510-w","DOIUrl":null,"url":null,"abstract":"<div><p>The <i>k</i>-Means algorithm is one of the most popular choices for clustering data but is well-known to be sensitive to the initialization process. There is a substantial number of methods that aim at finding optimal initial seeds for <i>k</i>-Means, though none of them is universally valid. This paper presents an extension to longitudinal data of one of such methods, the BRIk algorithm, that relies on clustering a set of centroids derived from bootstrap replicates of the data and on the use of the versatile Modified Band Depth. In our approach we improve the BRIk method by adding a step where we fit appropriate B-splines to our observations and a resampling process that allows computational feasibility and handling issues such as noise or missing data. We have derived two techniques for providing suitable initial seeds, each of them stressing respectively the multivariate or the functional nature of the data. Our results with simulated and real data sets indicate that our <i>F</i>unctional Data <i>A</i>pproach to the BRIK method (FABRIk) and our <i>F</i>unctional <i>D</i>ata <i>E</i>xtension of the BRIK method (FDEBRIk) are more effective than previous proposals at providing seeds to initialize <i>k</i>-Means in terms of clustering recovery.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"17 2","pages":"463 - 484"},"PeriodicalIF":1.3000,"publicationDate":"2022-09-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-022-00510-w.pdf","citationCount":"2","resultStr":"{\"title\":\"Band depth based initialization of K-means for functional data clustering\",\"authors\":\"Javier Albert-Smet, Aurora Torrente, Juan Romo\",\"doi\":\"10.1007/s11634-022-00510-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>The <i>k</i>-Means algorithm is one of the most popular choices for clustering data but is well-known to be sensitive to the initialization process. There is a substantial number of methods that aim at finding optimal initial seeds for <i>k</i>-Means, though none of them is universally valid. This paper presents an extension to longitudinal data of one of such methods, the BRIk algorithm, that relies on clustering a set of centroids derived from bootstrap replicates of the data and on the use of the versatile Modified Band Depth. In our approach we improve the BRIk method by adding a step where we fit appropriate B-splines to our observations and a resampling process that allows computational feasibility and handling issues such as noise or missing data. We have derived two techniques for providing suitable initial seeds, each of them stressing respectively the multivariate or the functional nature of the data. Our results with simulated and real data sets indicate that our <i>F</i>unctional Data <i>A</i>pproach to the BRIK method (FABRIk) and our <i>F</i>unctional <i>D</i>ata <i>E</i>xtension of the BRIK method (FDEBRIk) are more effective than previous proposals at providing seeds to initialize <i>k</i>-Means in terms of clustering recovery.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"17 2\",\"pages\":\"463 - 484\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2022-09-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s11634-022-00510-w.pdf\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-022-00510-w\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-022-00510-w","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
Band depth based initialization of K-means for functional data clustering
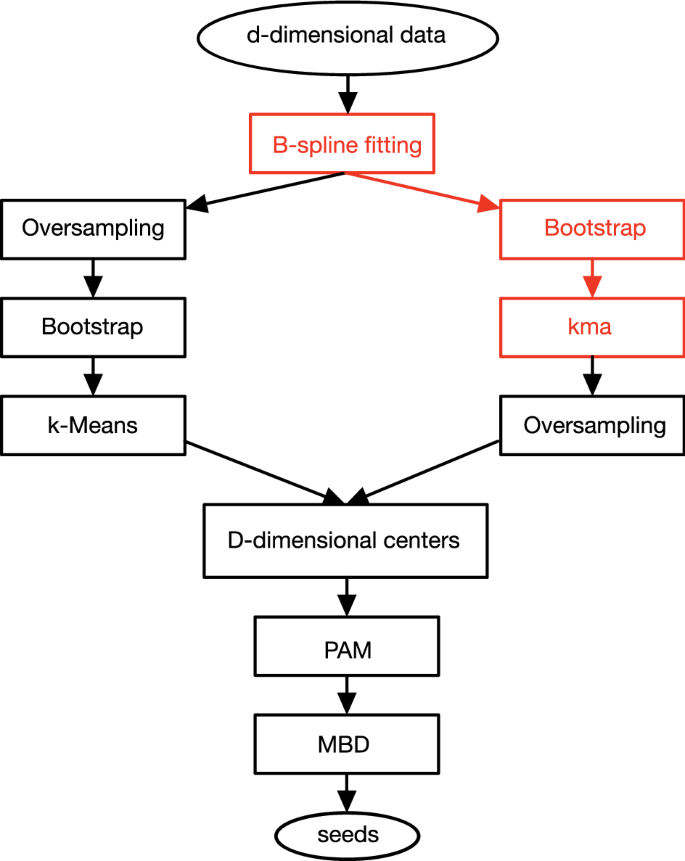
The k-Means algorithm is one of the most popular choices for clustering data but is well-known to be sensitive to the initialization process. There is a substantial number of methods that aim at finding optimal initial seeds for k-Means, though none of them is universally valid. This paper presents an extension to longitudinal data of one of such methods, the BRIk algorithm, that relies on clustering a set of centroids derived from bootstrap replicates of the data and on the use of the versatile Modified Band Depth. In our approach we improve the BRIk method by adding a step where we fit appropriate B-splines to our observations and a resampling process that allows computational feasibility and handling issues such as noise or missing data. We have derived two techniques for providing suitable initial seeds, each of them stressing respectively the multivariate or the functional nature of the data. Our results with simulated and real data sets indicate that our Functional Data Approach to the BRIK method (FABRIk) and our Functional Data Extension of the BRIK method (FDEBRIk) are more effective than previous proposals at providing seeds to initialize k-Means in terms of clustering recovery.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
