François-Alexandre Tremblay , Audrey Durand , Michael Morin , Philippe Marier , Jonathan Gaudreault
{"title":"木材连续干燥生产线控制的深度强化学习","authors":"François-Alexandre Tremblay , Audrey Durand , Michael Morin , Philippe Marier , Jonathan Gaudreault","doi":"10.1016/j.compind.2023.104036","DOIUrl":null,"url":null,"abstract":"<div><p>Continuous high-frequency wood drying, when integrated with a traditional wood finishing line, allows correcting moisture content one piece of lumber at a time in order to improve its value. However, the integration of this precision drying process complicates sawmills logistics. The high stochasticity of lumber properties and less than ideal lumber routing decisions may cause bottlenecks and reduces productivity. To counteract this problem and fully exploit the technology, we propose to use reinforcement learning (RL) for learning continuous drying operation policies. An RL agent interacts with a simulated model of the finishing line to optimize its policies. Our results, based on multiple simulations, show that the learned policies outperform the heuristic currently used in industry and are robust to sudden disturbances which frequently occur in real contexts.</p></div>","PeriodicalId":55219,"journal":{"name":"Computers in Industry","volume":"154 ","pages":"Article 104036"},"PeriodicalIF":9.1000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Deep reinforcement learning for continuous wood drying production line control\",\"authors\":\"François-Alexandre Tremblay , Audrey Durand , Michael Morin , Philippe Marier , Jonathan Gaudreault\",\"doi\":\"10.1016/j.compind.2023.104036\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Continuous high-frequency wood drying, when integrated with a traditional wood finishing line, allows correcting moisture content one piece of lumber at a time in order to improve its value. However, the integration of this precision drying process complicates sawmills logistics. The high stochasticity of lumber properties and less than ideal lumber routing decisions may cause bottlenecks and reduces productivity. To counteract this problem and fully exploit the technology, we propose to use reinforcement learning (RL) for learning continuous drying operation policies. An RL agent interacts with a simulated model of the finishing line to optimize its policies. Our results, based on multiple simulations, show that the learned policies outperform the heuristic currently used in industry and are robust to sudden disturbances which frequently occur in real contexts.</p></div>\",\"PeriodicalId\":55219,\"journal\":{\"name\":\"Computers in Industry\",\"volume\":\"154 \",\"pages\":\"Article 104036\"},\"PeriodicalIF\":9.1000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers in Industry\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0166361523001860\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/11/6 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers in Industry","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0166361523001860","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/11/6 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Deep reinforcement learning for continuous wood drying production line control
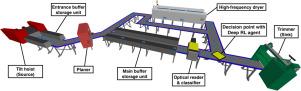
Continuous high-frequency wood drying, when integrated with a traditional wood finishing line, allows correcting moisture content one piece of lumber at a time in order to improve its value. However, the integration of this precision drying process complicates sawmills logistics. The high stochasticity of lumber properties and less than ideal lumber routing decisions may cause bottlenecks and reduces productivity. To counteract this problem and fully exploit the technology, we propose to use reinforcement learning (RL) for learning continuous drying operation policies. An RL agent interacts with a simulated model of the finishing line to optimize its policies. Our results, based on multiple simulations, show that the learned policies outperform the heuristic currently used in industry and are robust to sudden disturbances which frequently occur in real contexts.
期刊介绍:
The objective of Computers in Industry is to present original, high-quality, application-oriented research papers that:
• Illuminate emerging trends and possibilities in the utilization of Information and Communication Technology in industry;
• Establish connections or integrations across various technology domains within the expansive realm of computer applications for industry;
• Foster connections or integrations across diverse application areas of ICT in industry.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
