Sam Witty, Jun K. Lee, Emma Tosch, Akanksha Atrey, Kaleigh Clary, Michael L. Littman, David Jensen
{"title":"深度强化学习中泛化的测量和表征","authors":"Sam Witty, Jun K. Lee, Emma Tosch, Akanksha Atrey, Kaleigh Clary, Michael L. Littman, David Jensen","doi":"10.1002/ail2.45","DOIUrl":null,"url":null,"abstract":"<p>Deep reinforcement learning (RL) methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. We focus our analyses on the deep Q-networks (DQNs) that kicked off the modern era of deep RL. Taken together, these results call into question the extent to which DQNs learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.</p>","PeriodicalId":72253,"journal":{"name":"Applied AI letters","volume":"2 4","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2021-11-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ail2.45","citationCount":"46","resultStr":"{\"title\":\"Measuring and characterizing generalization in deep reinforcement learning\",\"authors\":\"Sam Witty, Jun K. Lee, Emma Tosch, Akanksha Atrey, Kaleigh Clary, Michael L. Littman, David Jensen\",\"doi\":\"10.1002/ail2.45\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Deep reinforcement learning (RL) methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. We focus our analyses on the deep Q-networks (DQNs) that kicked off the modern era of deep RL. Taken together, these results call into question the extent to which DQNs learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.</p>\",\"PeriodicalId\":72253,\"journal\":{\"name\":\"Applied AI letters\",\"volume\":\"2 4\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2021-11-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ail2.45\",\"citationCount\":\"46\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied AI letters\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ail2.45\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied AI letters","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ail2.45","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Measuring and characterizing generalization in deep reinforcement learning
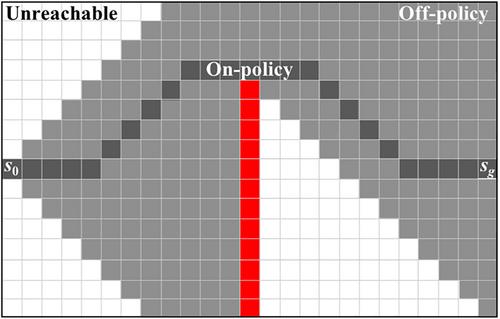
Deep reinforcement learning (RL) methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. We focus our analyses on the deep Q-networks (DQNs) that kicked off the modern era of deep RL. Taken together, these results call into question the extent to which DQNs learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
