M. Chaim, Kesina Baral, J. Offutt, Mario Concilio Neto, Roberto P. A. Araujo
{"title":"论数据流测试中的包容关系","authors":"M. Chaim, Kesina Baral, J. Offutt, Mario Concilio Neto, Roberto P. A. Araujo","doi":"10.1002/stvr.1843","DOIUrl":null,"url":null,"abstract":"Data flow testing creates test requirements as definition‐use (DU) associations, where a definition is a program location that assigns a value to a variable and a use is a location where that value is accessed. Data flow testing is expensive, largely because of the number of test requirements. Luckily, many DU‐associations are redundant in the sense that if one test requirement (e.g. node, edge and DU‐association) is covered, other DU‐associations are guaranteed to also be covered. This relationship is called subsumption. Thus, testers can save resources by only covering DU‐associations that are not subsumed by other testing requirements. Although this has the potential to significantly decrease the cost of data flow testing, there are roadblocks to its application. Finding data flow subsumptions correctly and efficiently has been an elusive goal; the savings provided by data flow subsumptions and the cost to find them need to be assessed; and the fault detection ability of a reduced set of DU‐associations and the advantages of data flow testing over node and edge coverage need to be verified. This paper presents novel solutions to these problems. We present algorithms that correctly find data flow subsumptions and are asymptotically less costly than previous algorithms. We present empirical data that show that data flow subsumption is effective at reducing the number of DU‐associations to be tested and can be found at scale. Furthermore, we found that using reduced DU‐associations decreased the fault detection ability by less than 2%, and data flow testing adds testing value beyond node and edge coverage.","PeriodicalId":49506,"journal":{"name":"Software Testing Verification & Reliability","volume":"75 1","pages":""},"PeriodicalIF":1.2000,"publicationDate":"2023-03-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"On subsumption relationships in data flow testing\",\"authors\":\"M. Chaim, Kesina Baral, J. Offutt, Mario Concilio Neto, Roberto P. A. Araujo\",\"doi\":\"10.1002/stvr.1843\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Data flow testing creates test requirements as definition‐use (DU) associations, where a definition is a program location that assigns a value to a variable and a use is a location where that value is accessed. Data flow testing is expensive, largely because of the number of test requirements. Luckily, many DU‐associations are redundant in the sense that if one test requirement (e.g. node, edge and DU‐association) is covered, other DU‐associations are guaranteed to also be covered. This relationship is called subsumption. Thus, testers can save resources by only covering DU‐associations that are not subsumed by other testing requirements. Although this has the potential to significantly decrease the cost of data flow testing, there are roadblocks to its application. Finding data flow subsumptions correctly and efficiently has been an elusive goal; the savings provided by data flow subsumptions and the cost to find them need to be assessed; and the fault detection ability of a reduced set of DU‐associations and the advantages of data flow testing over node and edge coverage need to be verified. This paper presents novel solutions to these problems. We present algorithms that correctly find data flow subsumptions and are asymptotically less costly than previous algorithms. We present empirical data that show that data flow subsumption is effective at reducing the number of DU‐associations to be tested and can be found at scale. Furthermore, we found that using reduced DU‐associations decreased the fault detection ability by less than 2%, and data flow testing adds testing value beyond node and edge coverage.\",\"PeriodicalId\":49506,\"journal\":{\"name\":\"Software Testing Verification & Reliability\",\"volume\":\"75 1\",\"pages\":\"\"},\"PeriodicalIF\":1.2000,\"publicationDate\":\"2023-03-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Software Testing Verification & Reliability\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1002/stvr.1843\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Software Testing Verification & Reliability","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1002/stvr.1843","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
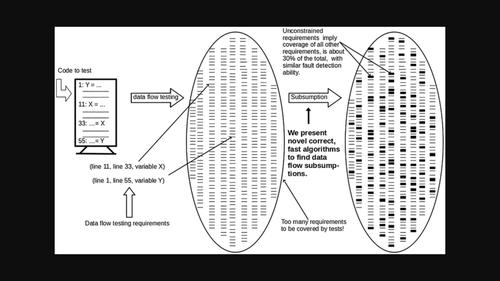
Data flow testing creates test requirements as definition‐use (DU) associations, where a definition is a program location that assigns a value to a variable and a use is a location where that value is accessed. Data flow testing is expensive, largely because of the number of test requirements. Luckily, many DU‐associations are redundant in the sense that if one test requirement (e.g. node, edge and DU‐association) is covered, other DU‐associations are guaranteed to also be covered. This relationship is called subsumption. Thus, testers can save resources by only covering DU‐associations that are not subsumed by other testing requirements. Although this has the potential to significantly decrease the cost of data flow testing, there are roadblocks to its application. Finding data flow subsumptions correctly and efficiently has been an elusive goal; the savings provided by data flow subsumptions and the cost to find them need to be assessed; and the fault detection ability of a reduced set of DU‐associations and the advantages of data flow testing over node and edge coverage need to be verified. This paper presents novel solutions to these problems. We present algorithms that correctly find data flow subsumptions and are asymptotically less costly than previous algorithms. We present empirical data that show that data flow subsumption is effective at reducing the number of DU‐associations to be tested and can be found at scale. Furthermore, we found that using reduced DU‐associations decreased the fault detection ability by less than 2%, and data flow testing adds testing value beyond node and edge coverage.
期刊介绍:
The journal is the premier outlet for research results on the subjects of testing, verification and reliability. Readers will find useful research on issues pertaining to building better software and evaluating it.
The journal is unique in its emphasis on theoretical foundations and applications to real-world software development. The balance of theory, empirical work, and practical applications provide readers with better techniques for testing, verifying and improving the reliability of software.
The journal targets researchers, practitioners, educators and students that have a vested interest in results generated by high-quality testing, verification and reliability modeling and evaluation of software. Topics of special interest include, but are not limited to:
-New criteria for software testing and verification
-Application of existing software testing and verification techniques to new types of software, including web applications, web services, embedded software, aspect-oriented software, and software architectures
-Model based testing
-Formal verification techniques such as model-checking
-Comparison of testing and verification techniques
-Measurement of and metrics for testing, verification and reliability
-Industrial experience with cutting edge techniques
-Descriptions and evaluations of commercial and open-source software testing tools
-Reliability modeling, measurement and application
-Testing and verification of software security
-Automated test data generation
-Process issues and methods
-Non-functional testing



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
