Camiel Colruyt, Orphée De Clercq, Thierry Desot, Véronique Hoste
{"title":"EventDNA:荷兰新闻事件提取的数据集,作为新闻多样化的基础。","authors":"Camiel Colruyt, Orphée De Clercq, Thierry Desot, Véronique Hoste","doi":"10.1007/s10579-022-09623-2","DOIUrl":null,"url":null,"abstract":"<p><p>News organizations increasingly tailor their news offering to the reader through personalized recommendation algorithms. However, automated recommendation algorithms reflect a commercial logic based on calculated relevance to the user, rather than aiming at a well-informed citizenry. In this paper, we introduce the EventDNA corpus, a dataset of 1773 Dutch-language news articles annotated with information on entities, news events and IPTC Media Topic codes, with the ultimate goal to outline a recommendation algorithm that uses news event diversity rather than previous reading behaviour as a key driver for personalized news recommendation. We describe the EventDNA annotation guidelines, which are inspired by the well-known ERE framework and conclude that it is not practical to apply a fixed event typology such as used in ERE to an unrestricted data context. The corpus and related source code is made available at https://github.com/NewsDNA-LT3/.github.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"57 1","pages":"189-221"},"PeriodicalIF":1.8000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9672586/pdf/","citationCount":"5","resultStr":"{\"title\":\"EventDNA: a dataset for Dutch news event extraction as a basis for news diversification.\",\"authors\":\"Camiel Colruyt, Orphée De Clercq, Thierry Desot, Véronique Hoste\",\"doi\":\"10.1007/s10579-022-09623-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>News organizations increasingly tailor their news offering to the reader through personalized recommendation algorithms. However, automated recommendation algorithms reflect a commercial logic based on calculated relevance to the user, rather than aiming at a well-informed citizenry. In this paper, we introduce the EventDNA corpus, a dataset of 1773 Dutch-language news articles annotated with information on entities, news events and IPTC Media Topic codes, with the ultimate goal to outline a recommendation algorithm that uses news event diversity rather than previous reading behaviour as a key driver for personalized news recommendation. We describe the EventDNA annotation guidelines, which are inspired by the well-known ERE framework and conclude that it is not practical to apply a fixed event typology such as used in ERE to an unrestricted data context. The corpus and related source code is made available at https://github.com/NewsDNA-LT3/.github.</p>\",\"PeriodicalId\":49927,\"journal\":{\"name\":\"Language Resources and Evaluation\",\"volume\":\"57 1\",\"pages\":\"189-221\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9672586/pdf/\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Language Resources and Evaluation\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10579-022-09623-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-022-09623-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
EventDNA: a dataset for Dutch news event extraction as a basis for news diversification.
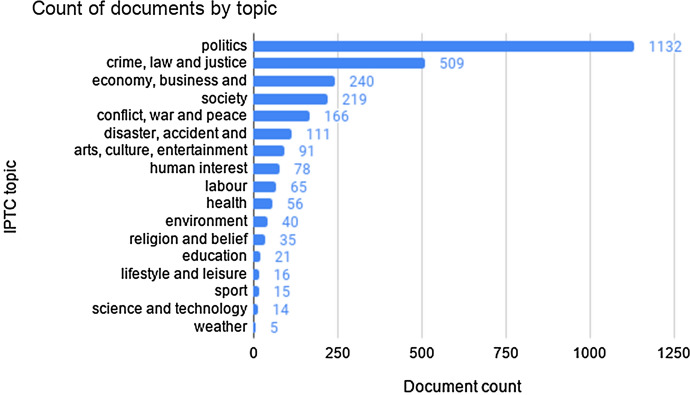
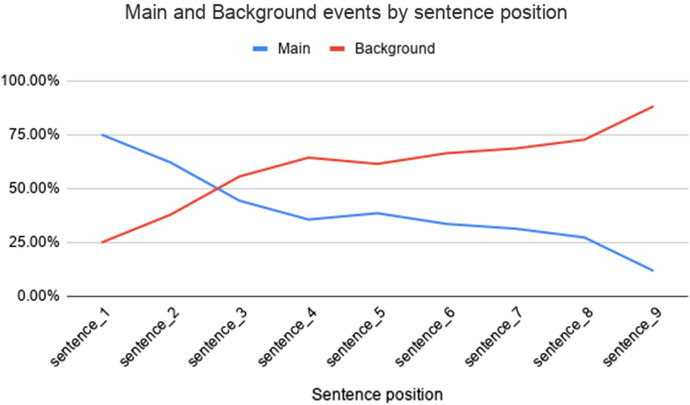
News organizations increasingly tailor their news offering to the reader through personalized recommendation algorithms. However, automated recommendation algorithms reflect a commercial logic based on calculated relevance to the user, rather than aiming at a well-informed citizenry. In this paper, we introduce the EventDNA corpus, a dataset of 1773 Dutch-language news articles annotated with information on entities, news events and IPTC Media Topic codes, with the ultimate goal to outline a recommendation algorithm that uses news event diversity rather than previous reading behaviour as a key driver for personalized news recommendation. We describe the EventDNA annotation guidelines, which are inspired by the well-known ERE framework and conclude that it is not practical to apply a fixed event typology such as used in ERE to an unrestricted data context. The corpus and related source code is made available at https://github.com/NewsDNA-LT3/.github.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
