{"title":"将改进的 YOLOv5 集成到人脸面具检测器和自动标记中,生成用于对抗 COVID-19 的数据集。","authors":"Thi-Ngot Pham, Viet-Hoan Nguyen, Jun-Ho Huh","doi":"10.1007/s11227-022-04979-2","DOIUrl":null,"url":null,"abstract":"<p><p>One of the most effective deterrent methods is using face masks to prevent the spread of the virus during the COVID-19 pandemic. Deep learning face mask detection networks have been implemented into COVID-19 monitoring systems to provide effective supervision for public areas. However, previous works have limitations: the challenge of real-time performance (i.e., fast inference and low accuracy) and training datasets. The current study aims to propose a comprehensive solution by creating a new face mask dataset and improving the YOLOv5 baseline to balance accuracy and detection time. Particularly, we improve YOLOv5 by adding coordinate attention (CA) module into the baseline backbone following two different schemes, namely YOLOv5s-CA and YOLOV5s-C3CA. In detail, we train three models with a Kaggle dataset of 853 images consisting of three categories: without a mask \"NM,\" with mask \"M,\" and incorrectly worn mask \"IWM\" classes. The experimental results show that our modified YOLOv5 with CA module achieves the highest accuracy mAP@0.5 of 93.9% compared with 87% of baseline and detection time per image of 8.0 ms (125 FPS). In addition, we build an integrated system of improved YOLOv5-CA and auto-labeling module to create a new face mask dataset of 7110 images with more than 3500 labels for three categories from YouTube videos. Our proposed YOLOv5-CA and the state-of-the-art detection models (i.e., YOLOX, YOLOv6, and YOLOv7) are trained on our 7110 images dataset. In our dataset, the YOLOv5-CA performance enhances with mAP@0.5 of 96.8%. The results indicate the enhancement of the improved YOLOv5-CA model compared with several state-of-the-art works.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"79 8","pages":"8966-8992"},"PeriodicalIF":2.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9809528/pdf/","citationCount":"0","resultStr":"{\"title\":\"Integration of improved YOLOv5 for face mask detector and auto-labeling to generate dataset for fighting against COVID-19.\",\"authors\":\"Thi-Ngot Pham, Viet-Hoan Nguyen, Jun-Ho Huh\",\"doi\":\"10.1007/s11227-022-04979-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>One of the most effective deterrent methods is using face masks to prevent the spread of the virus during the COVID-19 pandemic. Deep learning face mask detection networks have been implemented into COVID-19 monitoring systems to provide effective supervision for public areas. However, previous works have limitations: the challenge of real-time performance (i.e., fast inference and low accuracy) and training datasets. The current study aims to propose a comprehensive solution by creating a new face mask dataset and improving the YOLOv5 baseline to balance accuracy and detection time. Particularly, we improve YOLOv5 by adding coordinate attention (CA) module into the baseline backbone following two different schemes, namely YOLOv5s-CA and YOLOV5s-C3CA. In detail, we train three models with a Kaggle dataset of 853 images consisting of three categories: without a mask \\\"NM,\\\" with mask \\\"M,\\\" and incorrectly worn mask \\\"IWM\\\" classes. The experimental results show that our modified YOLOv5 with CA module achieves the highest accuracy mAP@0.5 of 93.9% compared with 87% of baseline and detection time per image of 8.0 ms (125 FPS). In addition, we build an integrated system of improved YOLOv5-CA and auto-labeling module to create a new face mask dataset of 7110 images with more than 3500 labels for three categories from YouTube videos. Our proposed YOLOv5-CA and the state-of-the-art detection models (i.e., YOLOX, YOLOv6, and YOLOv7) are trained on our 7110 images dataset. In our dataset, the YOLOv5-CA performance enhances with mAP@0.5 of 96.8%. The results indicate the enhancement of the improved YOLOv5-CA model compared with several state-of-the-art works.</p>\",\"PeriodicalId\":50034,\"journal\":{\"name\":\"Journal of Supercomputing\",\"volume\":\"79 8\",\"pages\":\"8966-8992\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9809528/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Supercomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11227-022-04979-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/3 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-022-04979-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/3 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
Integration of improved YOLOv5 for face mask detector and auto-labeling to generate dataset for fighting against COVID-19.
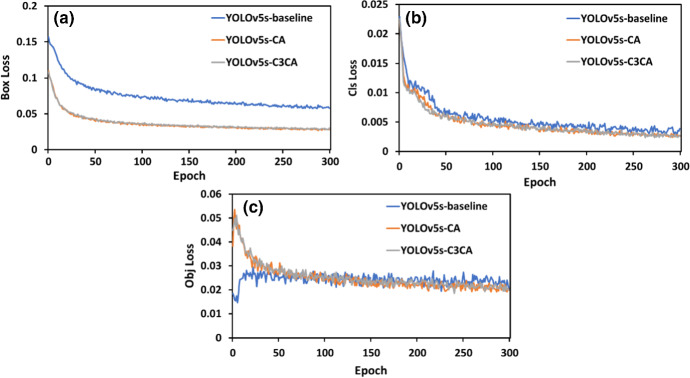
One of the most effective deterrent methods is using face masks to prevent the spread of the virus during the COVID-19 pandemic. Deep learning face mask detection networks have been implemented into COVID-19 monitoring systems to provide effective supervision for public areas. However, previous works have limitations: the challenge of real-time performance (i.e., fast inference and low accuracy) and training datasets. The current study aims to propose a comprehensive solution by creating a new face mask dataset and improving the YOLOv5 baseline to balance accuracy and detection time. Particularly, we improve YOLOv5 by adding coordinate attention (CA) module into the baseline backbone following two different schemes, namely YOLOv5s-CA and YOLOV5s-C3CA. In detail, we train three models with a Kaggle dataset of 853 images consisting of three categories: without a mask "NM," with mask "M," and incorrectly worn mask "IWM" classes. The experimental results show that our modified YOLOv5 with CA module achieves the highest accuracy mAP@0.5 of 93.9% compared with 87% of baseline and detection time per image of 8.0 ms (125 FPS). In addition, we build an integrated system of improved YOLOv5-CA and auto-labeling module to create a new face mask dataset of 7110 images with more than 3500 labels for three categories from YouTube videos. Our proposed YOLOv5-CA and the state-of-the-art detection models (i.e., YOLOX, YOLOv6, and YOLOv7) are trained on our 7110 images dataset. In our dataset, the YOLOv5-CA performance enhances with mAP@0.5 of 96.8%. The results indicate the enhancement of the improved YOLOv5-CA model compared with several state-of-the-art works.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
