Mohammed Ali Al-Garadi , Sangmi Kim , Yuting Guo , Elise Warren , Yuan-Chi Yang , Sahithi Lakamana , Abeed Sarker
{"title":"自动识别Twitter亲密伴侣暴力报告的自然语言模型","authors":"Mohammed Ali Al-Garadi , Sangmi Kim , Yuting Guo , Elise Warren , Yuan-Chi Yang , Sahithi Lakamana , Abeed Sarker","doi":"10.1016/j.array.2022.100217","DOIUrl":null,"url":null,"abstract":"<div><p>Intimate partner violence (IPV) is a preventable public health problem that affects millions of people worldwide. Approximately one in four women are estimated to be or have been victims of severe violence at some point in their lives, irrespective of age, ethnicity, and economic status. Victims often report IPV experiences on social media, and automatic detection of such reports via machine learning may enable improved surveillance and targeted distribution of support and/or interventions for those in need. However, no artificial intelligence systems for automatic detection currently exists, and we attempted to address this research gap. We collected posts from Twitter using a list of IPV-related keywords, manually reviewed subsets of retrieved posts, and prepared annotation guidelines to categorize tweets into IPV-report or non-IPV-report. We annotated 6,348 tweets in total, with the inter-annotator agreement (IAA) of 0.86 (Cohen's kappa) among 1,834 double-annotated tweets. The class distribution in the annotated dataset was highly imbalanced, with only 668 posts (∼11%) labeled as IPV-report. We then developed an effective natural language processing model to identify IPV-reporting tweets automatically. The developed model achieved classification F<sub>1</sub>-scores of 0.76 for the IPV-report class and 0.97 for the non-IPV-report class. We conducted post-classification analyses to determine the causes of system errors and to ensure that the system did not exhibit biases in its decision making, particularly with respect to race and gender. Our automatic model can be an essential component for a proactive social media-based intervention and support framework, while also aiding population-level surveillance and large-scale cohort studies.</p></div>","PeriodicalId":8417,"journal":{"name":"Array","volume":"15 ","pages":"Article 100217"},"PeriodicalIF":4.5000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/48/57/nihms-1882589.PMC10065459.pdf","citationCount":"15","resultStr":"{\"title\":\"Natural language model for automatic identification of Intimate Partner Violence reports from Twitter\",\"authors\":\"Mohammed Ali Al-Garadi , Sangmi Kim , Yuting Guo , Elise Warren , Yuan-Chi Yang , Sahithi Lakamana , Abeed Sarker\",\"doi\":\"10.1016/j.array.2022.100217\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Intimate partner violence (IPV) is a preventable public health problem that affects millions of people worldwide. Approximately one in four women are estimated to be or have been victims of severe violence at some point in their lives, irrespective of age, ethnicity, and economic status. Victims often report IPV experiences on social media, and automatic detection of such reports via machine learning may enable improved surveillance and targeted distribution of support and/or interventions for those in need. However, no artificial intelligence systems for automatic detection currently exists, and we attempted to address this research gap. We collected posts from Twitter using a list of IPV-related keywords, manually reviewed subsets of retrieved posts, and prepared annotation guidelines to categorize tweets into IPV-report or non-IPV-report. We annotated 6,348 tweets in total, with the inter-annotator agreement (IAA) of 0.86 (Cohen's kappa) among 1,834 double-annotated tweets. The class distribution in the annotated dataset was highly imbalanced, with only 668 posts (∼11%) labeled as IPV-report. We then developed an effective natural language processing model to identify IPV-reporting tweets automatically. The developed model achieved classification F<sub>1</sub>-scores of 0.76 for the IPV-report class and 0.97 for the non-IPV-report class. We conducted post-classification analyses to determine the causes of system errors and to ensure that the system did not exhibit biases in its decision making, particularly with respect to race and gender. Our automatic model can be an essential component for a proactive social media-based intervention and support framework, while also aiding population-level surveillance and large-scale cohort studies.</p></div>\",\"PeriodicalId\":8417,\"journal\":{\"name\":\"Array\",\"volume\":\"15 \",\"pages\":\"Article 100217\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2022-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/48/57/nihms-1882589.PMC10065459.pdf\",\"citationCount\":\"15\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Array\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2590005622000625\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Array","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2590005622000625","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Natural language model for automatic identification of Intimate Partner Violence reports from Twitter
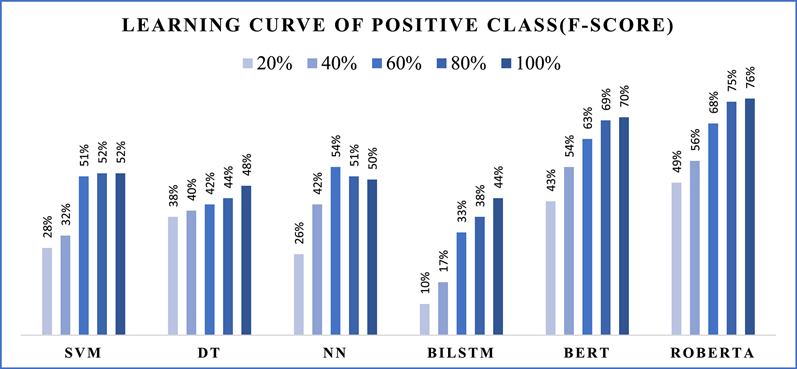
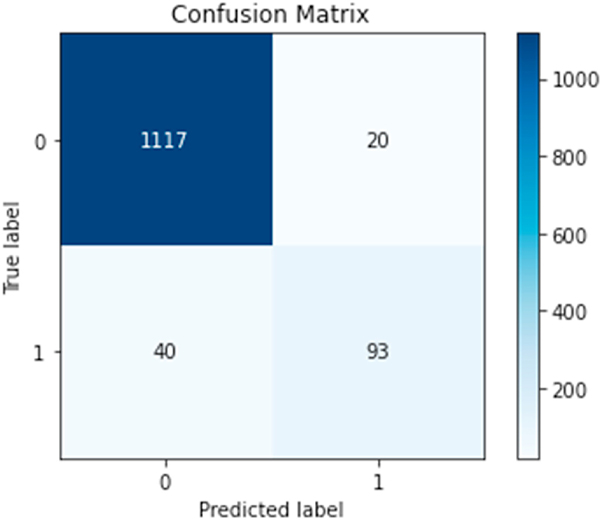
Intimate partner violence (IPV) is a preventable public health problem that affects millions of people worldwide. Approximately one in four women are estimated to be or have been victims of severe violence at some point in their lives, irrespective of age, ethnicity, and economic status. Victims often report IPV experiences on social media, and automatic detection of such reports via machine learning may enable improved surveillance and targeted distribution of support and/or interventions for those in need. However, no artificial intelligence systems for automatic detection currently exists, and we attempted to address this research gap. We collected posts from Twitter using a list of IPV-related keywords, manually reviewed subsets of retrieved posts, and prepared annotation guidelines to categorize tweets into IPV-report or non-IPV-report. We annotated 6,348 tweets in total, with the inter-annotator agreement (IAA) of 0.86 (Cohen's kappa) among 1,834 double-annotated tweets. The class distribution in the annotated dataset was highly imbalanced, with only 668 posts (∼11%) labeled as IPV-report. We then developed an effective natural language processing model to identify IPV-reporting tweets automatically. The developed model achieved classification F1-scores of 0.76 for the IPV-report class and 0.97 for the non-IPV-report class. We conducted post-classification analyses to determine the causes of system errors and to ensure that the system did not exhibit biases in its decision making, particularly with respect to race and gender. Our automatic model can be an essential component for a proactive social media-based intervention and support framework, while also aiding population-level surveillance and large-scale cohort studies.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
