Md Rajib Hossain, Mohammed Moshiul Hoque, Nazmul Siddique, Iqbal H Sarker
{"title":"CovTiNet:基于注意力的位置嵌入特征融合的Covid文本识别网络。","authors":"Md Rajib Hossain, Mohammed Moshiul Hoque, Nazmul Siddique, Iqbal H Sarker","doi":"10.1007/s00521-023-08442-y","DOIUrl":null,"url":null,"abstract":"<p><p>Covid text identification (CTI) is a crucial research concern in natural language processing (NLP). Social and electronic media are simultaneously adding a large volume of Covid-affiliated text on the World Wide Web due to the effortless access to the Internet, electronic gadgets and the Covid outbreak. Most of these texts are uninformative and contain misinformation, disinformation and malinformation that create an infodemic. Thus, Covid text identification is essential for controlling societal distrust and panic. Though very little Covid-related research (such as Covid disinformation, misinformation and fake news) has been reported in high-resource languages (e.g. English), CTI in low-resource languages (like Bengali) is in the preliminary stage to date. However, automatic CTI in Bengali text is challenging due to the deficit of benchmark corpora, complex linguistic constructs, immense verb inflexions and scarcity of NLP tools. On the other hand, the manual processing of Bengali Covid texts is arduous and costly due to their messy or unstructured forms. This research proposes a deep learning-based network (CovTiNet) to identify Covid text in Bengali. The CovTiNet incorporates an attention-based position embedding feature fusion for text-to-feature representation and attention-based CNN for Covid text identification. Experimental results show that the proposed CovTiNet achieved the highest accuracy of 96.61±.001% on the developed dataset (<i>BCovC</i>) compared to the other methods and baselines (i.e. BERT-M, IndicBERT, ELECTRA-Bengali, DistilBERT-M, BiLSTM, DCNN, CNN, LSTM, VDCNN and ACNN).</p>","PeriodicalId":49766,"journal":{"name":"Neural Computing & Applications","volume":"35 18","pages":"13503-13527"},"PeriodicalIF":4.5000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10011801/pdf/","citationCount":"4","resultStr":"{\"title\":\"CovTiNet: Covid text identification network using attention-based positional embedding feature fusion.\",\"authors\":\"Md Rajib Hossain, Mohammed Moshiul Hoque, Nazmul Siddique, Iqbal H Sarker\",\"doi\":\"10.1007/s00521-023-08442-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Covid text identification (CTI) is a crucial research concern in natural language processing (NLP). Social and electronic media are simultaneously adding a large volume of Covid-affiliated text on the World Wide Web due to the effortless access to the Internet, electronic gadgets and the Covid outbreak. Most of these texts are uninformative and contain misinformation, disinformation and malinformation that create an infodemic. Thus, Covid text identification is essential for controlling societal distrust and panic. Though very little Covid-related research (such as Covid disinformation, misinformation and fake news) has been reported in high-resource languages (e.g. English), CTI in low-resource languages (like Bengali) is in the preliminary stage to date. However, automatic CTI in Bengali text is challenging due to the deficit of benchmark corpora, complex linguistic constructs, immense verb inflexions and scarcity of NLP tools. On the other hand, the manual processing of Bengali Covid texts is arduous and costly due to their messy or unstructured forms. This research proposes a deep learning-based network (CovTiNet) to identify Covid text in Bengali. The CovTiNet incorporates an attention-based position embedding feature fusion for text-to-feature representation and attention-based CNN for Covid text identification. Experimental results show that the proposed CovTiNet achieved the highest accuracy of 96.61±.001% on the developed dataset (<i>BCovC</i>) compared to the other methods and baselines (i.e. BERT-M, IndicBERT, ELECTRA-Bengali, DistilBERT-M, BiLSTM, DCNN, CNN, LSTM, VDCNN and ACNN).</p>\",\"PeriodicalId\":49766,\"journal\":{\"name\":\"Neural Computing & Applications\",\"volume\":\"35 18\",\"pages\":\"13503-13527\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10011801/pdf/\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neural Computing & Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00521-023-08442-y\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Computing & Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00521-023-08442-y","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
CovTiNet: Covid text identification network using attention-based positional embedding feature fusion.
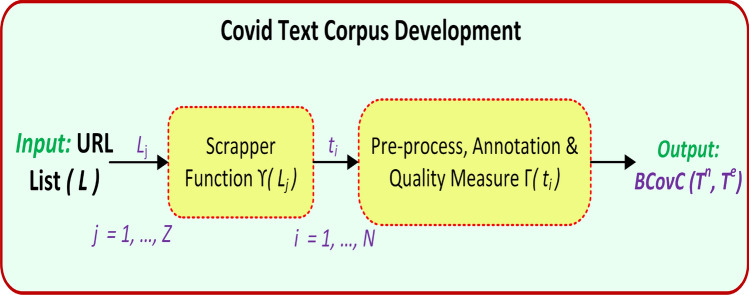
Covid text identification (CTI) is a crucial research concern in natural language processing (NLP). Social and electronic media are simultaneously adding a large volume of Covid-affiliated text on the World Wide Web due to the effortless access to the Internet, electronic gadgets and the Covid outbreak. Most of these texts are uninformative and contain misinformation, disinformation and malinformation that create an infodemic. Thus, Covid text identification is essential for controlling societal distrust and panic. Though very little Covid-related research (such as Covid disinformation, misinformation and fake news) has been reported in high-resource languages (e.g. English), CTI in low-resource languages (like Bengali) is in the preliminary stage to date. However, automatic CTI in Bengali text is challenging due to the deficit of benchmark corpora, complex linguistic constructs, immense verb inflexions and scarcity of NLP tools. On the other hand, the manual processing of Bengali Covid texts is arduous and costly due to their messy or unstructured forms. This research proposes a deep learning-based network (CovTiNet) to identify Covid text in Bengali. The CovTiNet incorporates an attention-based position embedding feature fusion for text-to-feature representation and attention-based CNN for Covid text identification. Experimental results show that the proposed CovTiNet achieved the highest accuracy of 96.61±.001% on the developed dataset (BCovC) compared to the other methods and baselines (i.e. BERT-M, IndicBERT, ELECTRA-Bengali, DistilBERT-M, BiLSTM, DCNN, CNN, LSTM, VDCNN and ACNN).
期刊介绍:
Neural Computing & Applications is an international journal which publishes original research and other information in the field of practical applications of neural computing and related techniques such as genetic algorithms, fuzzy logic and neuro-fuzzy systems.
All items relevant to building practical systems are within its scope, including but not limited to:
-adaptive computing-
algorithms-
applicable neural networks theory-
applied statistics-
architectures-
artificial intelligence-
benchmarks-
case histories of innovative applications-
fuzzy logic-
genetic algorithms-
hardware implementations-
hybrid intelligent systems-
intelligent agents-
intelligent control systems-
intelligent diagnostics-
intelligent forecasting-
machine learning-
neural networks-
neuro-fuzzy systems-
pattern recognition-
performance measures-
self-learning systems-
software simulations-
supervised and unsupervised learning methods-
system engineering and integration.
Featured contributions fall into several categories: Original Articles, Review Articles, Book Reviews and Announcements.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
