Chris Graziul, Alexander Belikov, Ishanu Chattopadyay, Ziwen Chen, Hongbo Fang, Anuraag Girdhar, Xiaoshuang Jia, P M Krafft, Max Kleiman-Weiner, Candice Lewis, Chen Liang, John Muchovej, Alejandro Vientós, Meg Young, James Evans
{"title":"大数据服务于政策吗?没有背景是不行的。硅社会科学实验。","authors":"Chris Graziul, Alexander Belikov, Ishanu Chattopadyay, Ziwen Chen, Hongbo Fang, Anuraag Girdhar, Xiaoshuang Jia, P M Krafft, Max Kleiman-Weiner, Candice Lewis, Chen Liang, John Muchovej, Alejandro Vientós, Meg Young, James Evans","doi":"10.1007/s10588-022-09362-3","DOIUrl":null,"url":null,"abstract":"<p><p>The DARPA Ground Truth project sought to evaluate social science by constructing four varied simulated social worlds with hidden causality and unleashed teams of scientists to collect data, discover their causal structure, predict their future, and prescribe policies to create desired outcomes. This large-scale, long-term experiment of in silico social science, about which the ground truth of simulated worlds was known, but not by us, reveals the limits of contemporary quantitative social science methodology. First, problem solving without a shared ontology-in which many world characteristics remain existentially uncertain-poses strong limits to quantitative analysis even when scientists share a common task, and suggests how they could become insurmountable without it. Second, data labels biased the associations our analysts made and assumptions they employed, often away from the simulated causal processes those labels signified, suggesting limits on the degree to which analytic concepts developed in one domain may port to others. Third, the current standard for computational social science publication is a demonstration of novel causes, but this limits the relevance of models to solve problems and propose policies that benefit from the simpler and less surprising answers associated with most important causes, or the combination of all causes. Fourth, most singular quantitative methods applied on their own did not help to solve most analytical challenges, and we explored a range of established and emerging methods, including probabilistic programming, deep neural networks, systems of predictive probabilistic finite state machines, and more to achieve plausible solutions. However, despite these limitations common to the current practice of computational social science, we find on the positive side that even imperfect knowledge can be sufficient to identify robust prediction if a more pluralistic approach is applied. Applying competing approaches by distinct subteams, including at one point the vast TopCoder.com global community of problem solvers, enabled discovery of many aspects of the relevant structure underlying worlds that singular methods could not. Together, these lessons suggest how different a policy-oriented computational social science would be than the computational social science we have inherited. Computational social science that serves policy would need to endure more failure, sustain more diversity, maintain more uncertainty, and allow for more complexity than current institutions support.</p>","PeriodicalId":50648,"journal":{"name":"Computational and Mathematical Organization Theory","volume":"29 1","pages":"188-219"},"PeriodicalIF":1.8000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9713146/pdf/","citationCount":"0","resultStr":"{\"title\":\"Does big data serve policy? Not without context. An experiment with in silico social science.\",\"authors\":\"Chris Graziul, Alexander Belikov, Ishanu Chattopadyay, Ziwen Chen, Hongbo Fang, Anuraag Girdhar, Xiaoshuang Jia, P M Krafft, Max Kleiman-Weiner, Candice Lewis, Chen Liang, John Muchovej, Alejandro Vientós, Meg Young, James Evans\",\"doi\":\"10.1007/s10588-022-09362-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The DARPA Ground Truth project sought to evaluate social science by constructing four varied simulated social worlds with hidden causality and unleashed teams of scientists to collect data, discover their causal structure, predict their future, and prescribe policies to create desired outcomes. This large-scale, long-term experiment of in silico social science, about which the ground truth of simulated worlds was known, but not by us, reveals the limits of contemporary quantitative social science methodology. First, problem solving without a shared ontology-in which many world characteristics remain existentially uncertain-poses strong limits to quantitative analysis even when scientists share a common task, and suggests how they could become insurmountable without it. Second, data labels biased the associations our analysts made and assumptions they employed, often away from the simulated causal processes those labels signified, suggesting limits on the degree to which analytic concepts developed in one domain may port to others. Third, the current standard for computational social science publication is a demonstration of novel causes, but this limits the relevance of models to solve problems and propose policies that benefit from the simpler and less surprising answers associated with most important causes, or the combination of all causes. Fourth, most singular quantitative methods applied on their own did not help to solve most analytical challenges, and we explored a range of established and emerging methods, including probabilistic programming, deep neural networks, systems of predictive probabilistic finite state machines, and more to achieve plausible solutions. However, despite these limitations common to the current practice of computational social science, we find on the positive side that even imperfect knowledge can be sufficient to identify robust prediction if a more pluralistic approach is applied. Applying competing approaches by distinct subteams, including at one point the vast TopCoder.com global community of problem solvers, enabled discovery of many aspects of the relevant structure underlying worlds that singular methods could not. Together, these lessons suggest how different a policy-oriented computational social science would be than the computational social science we have inherited. Computational social science that serves policy would need to endure more failure, sustain more diversity, maintain more uncertainty, and allow for more complexity than current institutions support.</p>\",\"PeriodicalId\":50648,\"journal\":{\"name\":\"Computational and Mathematical Organization Theory\",\"volume\":\"29 1\",\"pages\":\"188-219\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9713146/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational and Mathematical Organization Theory\",\"FirstCategoryId\":\"91\",\"ListUrlMain\":\"https://doi.org/10.1007/s10588-022-09362-3\",\"RegionNum\":4,\"RegionCategory\":\"管理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/11/30 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and Mathematical Organization Theory","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1007/s10588-022-09362-3","RegionNum":4,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/11/30 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Does big data serve policy? Not without context. An experiment with in silico social science.
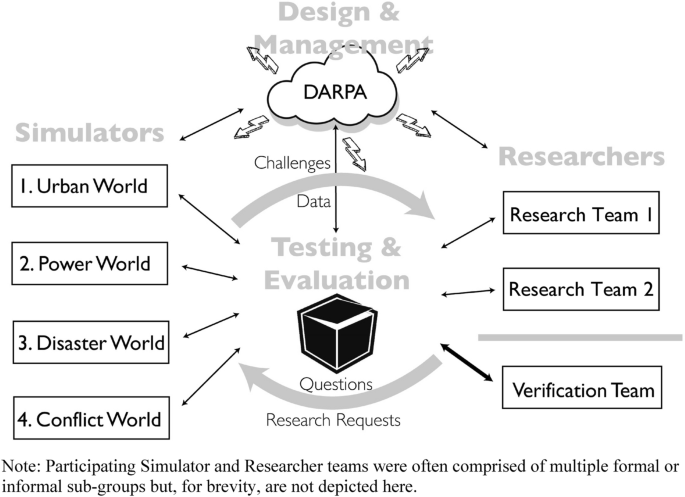
The DARPA Ground Truth project sought to evaluate social science by constructing four varied simulated social worlds with hidden causality and unleashed teams of scientists to collect data, discover their causal structure, predict their future, and prescribe policies to create desired outcomes. This large-scale, long-term experiment of in silico social science, about which the ground truth of simulated worlds was known, but not by us, reveals the limits of contemporary quantitative social science methodology. First, problem solving without a shared ontology-in which many world characteristics remain existentially uncertain-poses strong limits to quantitative analysis even when scientists share a common task, and suggests how they could become insurmountable without it. Second, data labels biased the associations our analysts made and assumptions they employed, often away from the simulated causal processes those labels signified, suggesting limits on the degree to which analytic concepts developed in one domain may port to others. Third, the current standard for computational social science publication is a demonstration of novel causes, but this limits the relevance of models to solve problems and propose policies that benefit from the simpler and less surprising answers associated with most important causes, or the combination of all causes. Fourth, most singular quantitative methods applied on their own did not help to solve most analytical challenges, and we explored a range of established and emerging methods, including probabilistic programming, deep neural networks, systems of predictive probabilistic finite state machines, and more to achieve plausible solutions. However, despite these limitations common to the current practice of computational social science, we find on the positive side that even imperfect knowledge can be sufficient to identify robust prediction if a more pluralistic approach is applied. Applying competing approaches by distinct subteams, including at one point the vast TopCoder.com global community of problem solvers, enabled discovery of many aspects of the relevant structure underlying worlds that singular methods could not. Together, these lessons suggest how different a policy-oriented computational social science would be than the computational social science we have inherited. Computational social science that serves policy would need to endure more failure, sustain more diversity, maintain more uncertainty, and allow for more complexity than current institutions support.
期刊介绍:
Computational and Mathematical Organization Theory provides an international forum for interdisciplinary research that combines computation, organizations and society. The goal is to advance the state of science in formal reasoning, analysis, and system building drawing on and encouraging advances in areas at the confluence of social networks, artificial intelligence, complexity, machine learning, sociology, business, political science, economics, and operations research. The papers in this journal will lead to the development of newtheories that explain and predict the behaviour of complex adaptive systems, new computational models and technologies that are responsible to society, business, policy, and law, new methods for integrating data, computational models, analysis and visualization techniques.
Various types of papers and underlying research are welcome. Papers presenting, validating, or applying models and/or computational techniques, new algorithms, dynamic metrics for networks and complex systems and papers comparing, contrasting and docking computational models are strongly encouraged. Both applied and theoretical work is strongly encouraged. The editors encourage theoretical research on fundamental principles of social behaviour such as coordination, cooperation, evolution, and destabilization. The editors encourage applied research representing actual organizational or policy problems that can be addressed using computational tools. Work related to fundamental concepts, corporate, military or intelligence issues are welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
