Lisa Chang, Yoshimi Fukuoka, Bradley E Aouizerat, Li Zhang, Elena Flowers
{"title":"利用菲律宾裔美国人的多维数据预测减肥可降低 2 型糖尿病风险:二次分析。","authors":"Lisa Chang, Yoshimi Fukuoka, Bradley E Aouizerat, Li Zhang, Elena Flowers","doi":"10.2196/44018","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Type 2 diabetes (T2D) has an immense disease burden, affecting millions of people worldwide and costing billions of dollars in treatment. As T2D is a multifactorial disease with both genetic and nongenetic influences, accurate risk assessments for patients are difficult to perform. Machine learning has served as a useful tool in T2D risk prediction, as it can analyze and detect patterns in large and complex data sets like that of RNA sequencing. However, before machine learning can be implemented, feature selection is a necessary step to reduce the dimensionality in high-dimensional data and optimize modeling results. Different combinations of feature selection methods and machine learning models have been used in studies reporting disease predictions and classifications with high accuracy.</p><p><strong>Objective: </strong>The purpose of this study was to assess the use of feature selection and classification approaches that integrate different data types to predict weight loss for the prevention of T2D.</p><p><strong>Methods: </strong>The data of 56 participants (ie, demographic and clinical factors, dietary scores, step counts, and transcriptomics) were obtained from a previously completed randomized clinical trial adaptation of the Diabetes Prevention Program study. Feature selection methods were used to select for subsets of transcripts to be used in the selected classification approaches: support vector machine, logistic regression, decision trees, random forest, and extremely randomized decision trees (extra-trees). Data types were included in different classification approaches in an additive manner to assess model performance for the prediction of weight loss.</p><p><strong>Results: </strong>Average waist and hip circumference were found to be different between those who exhibited weight loss and those who did not exhibit weight loss (P=.02 and P=.04, respectively). The incorporation of dietary and step count data did not improve modeling performance compared to classifiers that included only demographic and clinical data. Optimal subsets of transcripts identified through feature selection yielded higher prediction accuracy than when all available transcripts were included. After comparison of different feature selection methods and classifiers, DESeq2 as a feature selection method and an extra-trees classifier with and without ensemble learning provided the most optimal results, as defined by differences in training and testing accuracy, cross-validated area under the curve, and other factors. We identified 5 genes in two or more of the feature selection subsets (ie, CDP-diacylglycerol-inositol 3-phosphatidyltransferase [CDIPT], mannose receptor C type 2 [MRC2], PAT1 homolog 2 [PATL2], regulatory factor X-associated ankyrin containing protein [RFXANK], and small ubiquitin like modifier 3 [SUMO3]).</p><p><strong>Conclusions: </strong>Our results suggest that the inclusion of transcriptomic data in classification approaches for prediction has the potential to improve weight loss prediction models. Identification of which individuals are likely to respond to interventions for weight loss may help to prevent incident T2D. Out of the 5 genes identified as optimal predictors, 3 (ie, CDIPT, MRC2, and SUMO3) have been previously shown to be associated with T2D or obesity.</p><p><strong>Trial registration: </strong>ClinicalTrials.gov NCT02278939; https://clinicaltrials.gov/ct2/show/NCT02278939.</p>","PeriodicalId":52371,"journal":{"name":"JMIR Diabetes","volume":"8 ","pages":"e44018"},"PeriodicalIF":2.6000,"publicationDate":"2023-04-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131631/pdf/","citationCount":"0","resultStr":"{\"title\":\"Prediction of Weight Loss to Decrease the Risk for Type 2 Diabetes Using Multidimensional Data in Filipino Americans: Secondary Analysis.\",\"authors\":\"Lisa Chang, Yoshimi Fukuoka, Bradley E Aouizerat, Li Zhang, Elena Flowers\",\"doi\":\"10.2196/44018\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Type 2 diabetes (T2D) has an immense disease burden, affecting millions of people worldwide and costing billions of dollars in treatment. As T2D is a multifactorial disease with both genetic and nongenetic influences, accurate risk assessments for patients are difficult to perform. Machine learning has served as a useful tool in T2D risk prediction, as it can analyze and detect patterns in large and complex data sets like that of RNA sequencing. However, before machine learning can be implemented, feature selection is a necessary step to reduce the dimensionality in high-dimensional data and optimize modeling results. Different combinations of feature selection methods and machine learning models have been used in studies reporting disease predictions and classifications with high accuracy.</p><p><strong>Objective: </strong>The purpose of this study was to assess the use of feature selection and classification approaches that integrate different data types to predict weight loss for the prevention of T2D.</p><p><strong>Methods: </strong>The data of 56 participants (ie, demographic and clinical factors, dietary scores, step counts, and transcriptomics) were obtained from a previously completed randomized clinical trial adaptation of the Diabetes Prevention Program study. Feature selection methods were used to select for subsets of transcripts to be used in the selected classification approaches: support vector machine, logistic regression, decision trees, random forest, and extremely randomized decision trees (extra-trees). Data types were included in different classification approaches in an additive manner to assess model performance for the prediction of weight loss.</p><p><strong>Results: </strong>Average waist and hip circumference were found to be different between those who exhibited weight loss and those who did not exhibit weight loss (P=.02 and P=.04, respectively). The incorporation of dietary and step count data did not improve modeling performance compared to classifiers that included only demographic and clinical data. Optimal subsets of transcripts identified through feature selection yielded higher prediction accuracy than when all available transcripts were included. After comparison of different feature selection methods and classifiers, DESeq2 as a feature selection method and an extra-trees classifier with and without ensemble learning provided the most optimal results, as defined by differences in training and testing accuracy, cross-validated area under the curve, and other factors. We identified 5 genes in two or more of the feature selection subsets (ie, CDP-diacylglycerol-inositol 3-phosphatidyltransferase [CDIPT], mannose receptor C type 2 [MRC2], PAT1 homolog 2 [PATL2], regulatory factor X-associated ankyrin containing protein [RFXANK], and small ubiquitin like modifier 3 [SUMO3]).</p><p><strong>Conclusions: </strong>Our results suggest that the inclusion of transcriptomic data in classification approaches for prediction has the potential to improve weight loss prediction models. Identification of which individuals are likely to respond to interventions for weight loss may help to prevent incident T2D. Out of the 5 genes identified as optimal predictors, 3 (ie, CDIPT, MRC2, and SUMO3) have been previously shown to be associated with T2D or obesity.</p><p><strong>Trial registration: </strong>ClinicalTrials.gov NCT02278939; https://clinicaltrials.gov/ct2/show/NCT02278939.</p>\",\"PeriodicalId\":52371,\"journal\":{\"name\":\"JMIR Diabetes\",\"volume\":\"8 \",\"pages\":\"e44018\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2023-04-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131631/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Diabetes\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/44018\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Diabetes","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/44018","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
Prediction of Weight Loss to Decrease the Risk for Type 2 Diabetes Using Multidimensional Data in Filipino Americans: Secondary Analysis.
Background: Type 2 diabetes (T2D) has an immense disease burden, affecting millions of people worldwide and costing billions of dollars in treatment. As T2D is a multifactorial disease with both genetic and nongenetic influences, accurate risk assessments for patients are difficult to perform. Machine learning has served as a useful tool in T2D risk prediction, as it can analyze and detect patterns in large and complex data sets like that of RNA sequencing. However, before machine learning can be implemented, feature selection is a necessary step to reduce the dimensionality in high-dimensional data and optimize modeling results. Different combinations of feature selection methods and machine learning models have been used in studies reporting disease predictions and classifications with high accuracy.
Objective: The purpose of this study was to assess the use of feature selection and classification approaches that integrate different data types to predict weight loss for the prevention of T2D.
Methods: The data of 56 participants (ie, demographic and clinical factors, dietary scores, step counts, and transcriptomics) were obtained from a previously completed randomized clinical trial adaptation of the Diabetes Prevention Program study. Feature selection methods were used to select for subsets of transcripts to be used in the selected classification approaches: support vector machine, logistic regression, decision trees, random forest, and extremely randomized decision trees (extra-trees). Data types were included in different classification approaches in an additive manner to assess model performance for the prediction of weight loss.
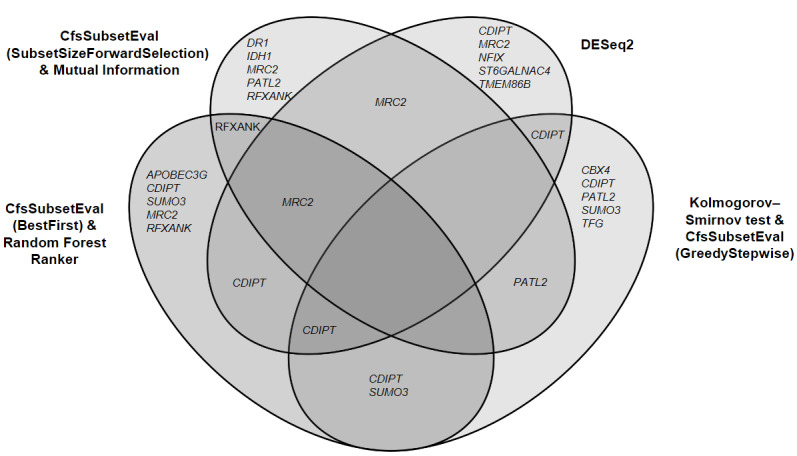
Results: Average waist and hip circumference were found to be different between those who exhibited weight loss and those who did not exhibit weight loss (P=.02 and P=.04, respectively). The incorporation of dietary and step count data did not improve modeling performance compared to classifiers that included only demographic and clinical data. Optimal subsets of transcripts identified through feature selection yielded higher prediction accuracy than when all available transcripts were included. After comparison of different feature selection methods and classifiers, DESeq2 as a feature selection method and an extra-trees classifier with and without ensemble learning provided the most optimal results, as defined by differences in training and testing accuracy, cross-validated area under the curve, and other factors. We identified 5 genes in two or more of the feature selection subsets (ie, CDP-diacylglycerol-inositol 3-phosphatidyltransferase [CDIPT], mannose receptor C type 2 [MRC2], PAT1 homolog 2 [PATL2], regulatory factor X-associated ankyrin containing protein [RFXANK], and small ubiquitin like modifier 3 [SUMO3]).
Conclusions: Our results suggest that the inclusion of transcriptomic data in classification approaches for prediction has the potential to improve weight loss prediction models. Identification of which individuals are likely to respond to interventions for weight loss may help to prevent incident T2D. Out of the 5 genes identified as optimal predictors, 3 (ie, CDIPT, MRC2, and SUMO3) have been previously shown to be associated with T2D or obesity.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
