{"title":"比较 ChatGPT 与新西兰医科学生对刻板印象程度和刻板印象归因一致性的评级能力,以开发相似性评级测试:一项方法论研究。","authors":"Chao-Cheng Lin, Zaine Akuhata-Huntington, Che-Wei Hsu","doi":"10.3352/jeehp.2023.20.17","DOIUrl":null,"url":null,"abstract":"<p><p>Learning about one’s implicit bias is crucial for improving one’s cultural competency and thereby reducing health inequity. To evaluate bias among medical students following a previously developed cultural training program targeting New Zealand Māori, we developed a text-based, self-evaluation tool called the Similarity Rating Test (SRT). The development process of the SRT was resource-intensive, limiting its generalizability and applicability. Here, we explored the potential of ChatGPT, an automated chatbot, to assist in the development process of the SRT by comparing ChatGPT’s and students’ evaluations of the SRT. Despite results showing non-significant equivalence and difference between ChatGPT’s and students’ ratings, ChatGPT’s ratings were more consistent than students’ ratings. The consistency rate was higher for non-stereotypical than for stereotypical statements, regardless of rater type. Further studies are warranted to validate ChatGPT’s potential for assisting in SRT development for implementation in medical education and evaluation of ethnic stereotypes and related topics.</p>","PeriodicalId":46098,"journal":{"name":"Journal of Educational Evaluation for Health Professions","volume":"20 ","pages":"17"},"PeriodicalIF":3.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10356547/pdf/","citationCount":"2","resultStr":"{\"title\":\"Comparing ChatGPT’s ability to rate the degree of stereotypes and the consistency of stereotype attribution with those of medical students in New Zealand in developing a similarity rating test: a methodological study.\",\"authors\":\"Chao-Cheng Lin, Zaine Akuhata-Huntington, Che-Wei Hsu\",\"doi\":\"10.3352/jeehp.2023.20.17\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Learning about one’s implicit bias is crucial for improving one’s cultural competency and thereby reducing health inequity. To evaluate bias among medical students following a previously developed cultural training program targeting New Zealand Māori, we developed a text-based, self-evaluation tool called the Similarity Rating Test (SRT). The development process of the SRT was resource-intensive, limiting its generalizability and applicability. Here, we explored the potential of ChatGPT, an automated chatbot, to assist in the development process of the SRT by comparing ChatGPT’s and students’ evaluations of the SRT. Despite results showing non-significant equivalence and difference between ChatGPT’s and students’ ratings, ChatGPT’s ratings were more consistent than students’ ratings. The consistency rate was higher for non-stereotypical than for stereotypical statements, regardless of rater type. Further studies are warranted to validate ChatGPT’s potential for assisting in SRT development for implementation in medical education and evaluation of ethnic stereotypes and related topics.</p>\",\"PeriodicalId\":46098,\"journal\":{\"name\":\"Journal of Educational Evaluation for Health Professions\",\"volume\":\"20 \",\"pages\":\"17\"},\"PeriodicalIF\":3.7000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10356547/pdf/\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Educational Evaluation for Health Professions\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3352/jeehp.2023.20.17\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/6/12 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Educational Evaluation for Health Professions","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3352/jeehp.2023.20.17","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/6/12 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
Comparing ChatGPT’s ability to rate the degree of stereotypes and the consistency of stereotype attribution with those of medical students in New Zealand in developing a similarity rating test: a methodological study.
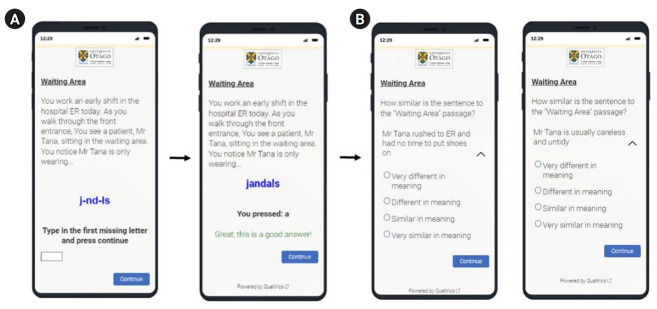
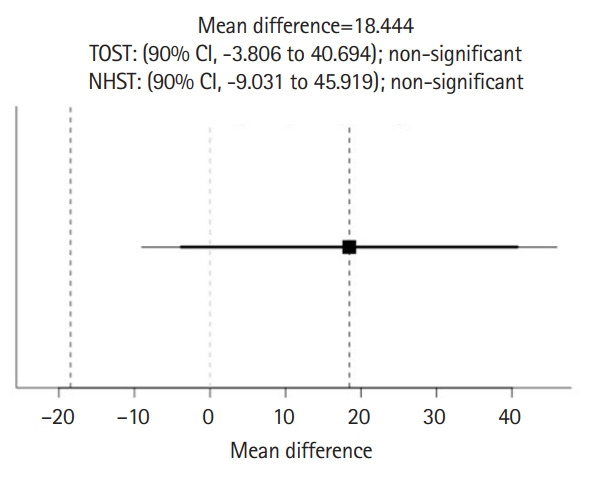
Learning about one’s implicit bias is crucial for improving one’s cultural competency and thereby reducing health inequity. To evaluate bias among medical students following a previously developed cultural training program targeting New Zealand Māori, we developed a text-based, self-evaluation tool called the Similarity Rating Test (SRT). The development process of the SRT was resource-intensive, limiting its generalizability and applicability. Here, we explored the potential of ChatGPT, an automated chatbot, to assist in the development process of the SRT by comparing ChatGPT’s and students’ evaluations of the SRT. Despite results showing non-significant equivalence and difference between ChatGPT’s and students’ ratings, ChatGPT’s ratings were more consistent than students’ ratings. The consistency rate was higher for non-stereotypical than for stereotypical statements, regardless of rater type. Further studies are warranted to validate ChatGPT’s potential for assisting in SRT development for implementation in medical education and evaluation of ethnic stereotypes and related topics.
期刊介绍:
Journal of Educational Evaluation for Health Professions aims to provide readers the state-of-the art practical information on the educational evaluation for health professions so that to increase the quality of undergraduate, graduate, and continuing education. It is specialized in educational evaluation including adoption of measurement theory to medical health education, promotion of high stakes examination such as national licensing examinations, improvement of nationwide or international programs of education, computer-based testing, computerized adaptive testing, and medical health regulatory bodies. Its field comprises a variety of professions that address public medical health as following but not limited to: Care workers Dental hygienists Dental technicians Dentists Dietitians Emergency medical technicians Health educators Medical record technicians Medical technologists Midwives Nurses Nursing aides Occupational therapists Opticians Oriental medical doctors Oriental medicine dispensers Oriental pharmacists Pharmacists Physical therapists Physicians Prosthetists and Orthotists Radiological technologists Rehabilitation counselor Sanitary technicians Speech-language therapists.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
