AIR 科研|LLM RL最强算法,清华AIR-字节跳动SIA-Lab联合发布
智药邦
2025-03-27 08:00
文章摘要
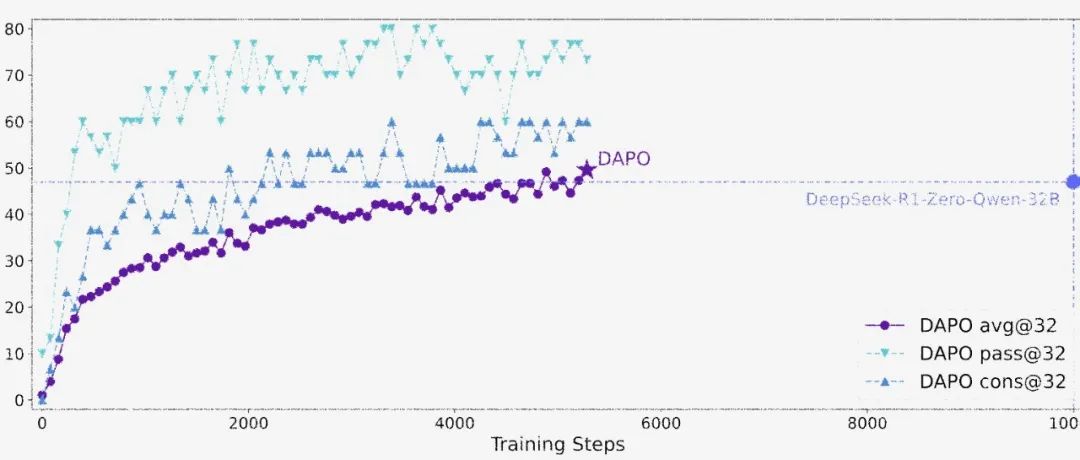
本文介绍了清华大学智能产业研究院(AIR)与字节跳动SIA-Lab联合开发的大规模LLM强化学习系统DAPO。该系统在纯RL端的比较中超越了DeepSeed R1模型所使用的GRPO算法,取得了新的SOTA结果。研究团队通过引入Clip-Higher、Dynamic Sampling、Token-Level Policy Gradient Loss和Overlong Reward Shaping四项关键技术,解决了大规模强化学习训练中的熵崩塌、梯度衰减和奖励噪声等问题。实验结果显示,DAPO在AIME 2024测试集上取得了50分的优异成绩,超越了前SOTA模型DeepSeek-R1-Zero-Qwen-32B,且仅用了一半的训练步数。
本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者速来电或来函联系。